
In information theory, the entropy of a random variable is the average level of "information", "surprise", or "uncertainty" inherent to the variable's possible outcomes. Given a discrete random variable , which takes values in the alphabet and is distributed according to :
Reed–Solomon codes are a group of error-correcting codes that were introduced by Irving S. Reed and Gustave Solomon in 1960. They have many applications, the most prominent of which include consumer technologies such as MiniDiscs, CDs, DVDs, Blu-ray discs, QR codes, data transmission technologies such as DSL and WiMAX, broadcast systems such as satellite communications, DVB and ATSC, and storage systems such as RAID 6.
A binary symmetric channel is a common communications channel model used in coding theory and information theory. In this model, a transmitter wishes to send a bit, and the receiver will receive a bit. The bit will be "flipped" with a "crossover probability" of p, and otherwise is received correctly. This model can be applied to varied communication channels such as telephone lines or disk drive storage.
Additive white Gaussian noise (AWGN) is a basic noise model used in information theory to mimic the effect of many random processes that occur in nature. The modifiers denote specific characteristics:
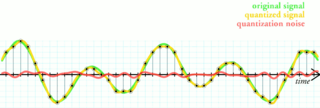
Quantization, in mathematics and digital signal processing, is the process of mapping input values from a large set to output values in a (countable) smaller set, often with a finite number of elements. Rounding and truncation are typical examples of quantization processes. Quantization is involved to some degree in nearly all digital signal processing, as the process of representing a signal in digital form ordinarily involves rounding. Quantization also forms the core of essentially all lossy compression algorithms.
In coding theory, block codes are a large and important family of error-correcting codes that encode data in blocks. There is a vast number of examples for block codes, many of which have a wide range of practical applications. The abstract definition of block codes is conceptually useful because it allows coding theorists, mathematicians, and computer scientists to study the limitations of all block codes in a unified way. Such limitations often take the form of bounds that relate different parameters of the block code to each other, such as its rate and its ability to detect and correct errors.
In coding theory, decoding is the process of translating received messages into codewords of a given code. There have been many common methods of mapping messages to codewords. These are often used to recover messages sent over a noisy channel, such as a binary symmetric channel.
Reed–Muller codes are error-correcting codes that are used in wireless communications applications, particularly in deep-space communication. Moreover, the proposed 5G standard relies on the closely related polar codes for error correction in the control channel. Due to their favorable theoretical and mathematical properties, Reed–Muller codes have also been extensively studied in theoretical computer science.

The Hadamard code is an error-correcting code named after Jacques Hadamard that is used for error detection and correction when transmitting messages over very noisy or unreliable channels. In 1971, the code was used to transmit photos of Mars back to Earth from the NASA space probe Mariner 9. Because of its unique mathematical properties, the Hadamard code is not only used by engineers, but also intensely studied in coding theory, mathematics, and theoretical computer science. The Hadamard code is also known under the names Walsh code, Walsh family, and Walsh–Hadamard code in recognition of the American mathematician Joseph Leonard Walsh.
In theoretical computer science, a small-bias sample space is a probability distribution that fools parity functions. In other words, no parity function can distinguish between a small-bias sample space and the uniform distribution with high probability, and hence, small-bias sample spaces naturally give rise to pseudorandom generators for parity functions.
In coding theory, list decoding is an alternative to unique decoding of error-correcting codes for large error rates. The notion was proposed by Elias in the 1950s. The main idea behind list decoding is that the decoding algorithm instead of outputting a single possible message outputs a list of possibilities one of which is correct. This allows for handling a greater number of errors than that allowed by unique decoding.
A randomness extractor, often simply called an "extractor", is a function, which being applied to output from a weak entropy source, together with a short, uniformly random seed, generates a highly random output that appears independent from the source and uniformly distributed. Examples of weakly random sources include radioactive decay or thermal noise; the only restriction on possible sources is that there is no way they can be fully controlled, calculated or predicted, and that a lower bound on their entropy rate can be established. For a given source, a randomness extractor can even be considered to be a true random number generator (TRNG); but there is no single extractor that has been proven to produce truly random output from any type of weakly random source.
A locally decodable code (LDC) is an error-correcting code that allows a single bit of the original message to be decoded with high probability by only examining a small number of bits of a possibly corrupted codeword. This property could be useful, say, in a context where information is being transmitted over a noisy channel, and only a small subset of the data is required at a particular time and there is no need to decode the entire message at once. Note that locally decodable codes are not a subset of locally testable codes, though there is some overlap between the two.
The Gilbert–Varshamov bound for linear codes is related to the general Gilbert–Varshamov bound, which gives a lower bound on the maximal number of elements in an error-correcting code of a given block length and minimum Hamming weight over a field . This may be translated into a statement about the maximum rate of a code with given length and minimum distance. The Gilbert–Varshamov bound for linear codes asserts the existence of q-ary linear codes for any relative minimum distance less than the given bound that simultaneously have high rate. The existence proof uses the probabilistic method, and thus is not constructive. The Gilbert–Varshamov bound is the best known in terms of relative distance for codes over alphabets of size less than 49. For larger alphabets, algebraic geometry codes sometimes achieve an asymptotically better rate vs. distance tradeoff than is given by the Gilbert–Varshamov bound.
In coding theory, generalized minimum-distance (GMD) decoding provides an efficient algorithm for decoding concatenated codes, which is based on using an errors-and-erasures decoder for the outer code.
In coding theory, the Zyablov bound is a lower bound on the rate and relative distance that are achievable by concatenated codes.
In coding theory, folded Reed–Solomon codes are like Reed–Solomon codes, which are obtained by mapping Reed–Solomon codewords over a larger alphabet by careful bundling of codeword symbols.
In coding theory, list decoding is an alternative to unique decoding of error-correcting codes in the presence of many errors. If a code has relative distance , then it is possible in principle to recover an encoded message when up to fraction of the codeword symbols are corrupted. But when error rate is greater than , this will not in general be possible. List decoding overcomes that issue by allowing the decoder to output a short list of messages that might have been encoded. List decoding can correct more than fraction of errors.
In coding theory, burst error-correcting codes employ methods of correcting burst errors, which are errors that occur in many consecutive bits rather than occurring in bits independently of each other.
In coding theory, Zemor's algorithm, designed and developed by Gilles Zemor, is a recursive low-complexity approach to code construction. It is an improvement over the algorithm of Sipser and Spielman.


















































