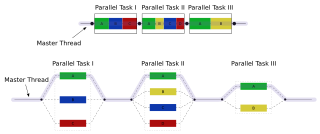
Map is an idiom in parallel computing where a simple operation is applied to all elements of a sequence, potentially in parallel. [1] It is used to solve embarrassingly parallel problems: those problems that can be decomposed into independent subtasks, requiring no communication/synchronization between the subtasks except a join or barrier at the end.
A programming idiom or code idiom is expressing a special feature of a recurring construct in one or more programming languages. Developers recognize programming idioms by associating and giving meaning to one or more code fragments. The idiom can be seen as a concept underlying a pattern in code, which is represented in implementation by contiguous or scattered code fragments. These fragments are available in several programming languages, frameworks or even libraries. Generally speaking, a programming idiom is a natural language expression of a simple task, algorithm, or data structure that is not a built-in feature in the programming language being used, or, conversely, the use of an unusual or notable feature that is built into a programming language. Furthermore, the term can be used more broadly, to refer to complex algorithms or programming design patterns in terms of implementation and omitting design rationale.

Parallel computing is a type of computation in which many calculations or the execution of processes are carried out simultaneously. Large problems can often be divided into smaller ones, which can then be solved at the same time. There are several different forms of parallel computing: bit-level, instruction-level, data, and task parallelism. Parallelism has long been employed in high-performance computing, but it's gaining broader interest due to the physical constraints preventing frequency scaling. As power consumption by computers has become a concern in recent years, parallel computing has become the dominant paradigm in computer architecture, mainly in the form of multi-core processors.
In parallel computing, an embarrassingly parallel workload or problem is one where little or no effort is needed to separate the problem into a number of parallel tasks. This is often the case where there is little or no dependency or need for communication between those parallel tasks, or for results between them.
When applying the map pattern, one formulates an elemental function that captures the operation to be performed on a data item that represents a part of the problem, then applies this elemental function in one or more threads of execution, hyperthreads, SIMD lanes or on multiple computers.

In computer science, a thread of execution is the smallest sequence of programmed instructions that can be managed independently by a scheduler, which is typically a part of the operating system. The implementation of threads and processes differs between operating systems, but in most cases a thread is a component of a process. Multiple threads can exist within one process, executing concurrently and sharing resources such as memory, while different processes do not share these resources. In particular, the threads of a process share its executable code and the values of its dynamically allocated variables and non-thread-local global variables at any given time.
Distributed computing is a field of computer science that studies distributed systems. A distributed system is a system whose components are located on different networked computers, which communicate and coordinate their actions by passing messages to one another. The components interact with one another in order to achieve a common goal. Three significant characteristics of distributed systems are: concurrency of components, lack of a global clock, and independent failure of components. Examples of distributed systems vary from SOA-based systems to massively multiplayer online games to peer-to-peer applications.
Some parallel programming systems, such as OpenMP and Cilk, have language support for the map pattern in the form of a parallel for loop; [2] languages such as OpenCL and CUDA support elemental functions (as "kernels") at the language level. The map pattern is typically combined with other parallel design patterns. For example, map combined with category reduction gives the MapReduce pattern. [3] :106–107
OpenMP is an application programming interface (API) that supports multi-platform shared memory multiprocessing programming in C, C++, and Fortran, on most platforms, instruction set architectures and operating systems, including Solaris, AIX, HP-UX, Linux, macOS, and Windows. It consists of a set of compiler directives, library routines, and environment variables that influence run-time behavior.
Cilk, Cilk++ and Cilk Plus are general-purpose programming languages designed for multithreaded parallel computing. They are based on the C and C++ programming languages, which they extend with constructs to express parallel loops and the fork–join idiom.
OpenCL is a framework for writing programs that execute across heterogeneous platforms consisting of central processing units (CPUs), graphics processing units (GPUs), digital signal processors (DSPs), field-programmable gate arrays (FPGAs) and other processors or hardware accelerators. OpenCL specifies programming languages for programming these devices and application programming interfaces (APIs) to control the platform and execute programs on the compute devices. OpenCL provides a standard interface for parallel computing using task- and data-based parallelism.