In graph theory, a perfect matching in a graph is a matching that covers every vertex of the graph. More formally, given a graph G = (V, E), a perfect matching in G is a subset M of edge set E, such that every vertex in the vertex set V is adjacent to exactly one edge in M.

In mathematics, a system of linear equations is a collection of two or more linear equations involving the same variables. For example,
In linear algebra, the Cholesky decomposition or Cholesky factorization is a decomposition of a Hermitian, positive-definite matrix into the product of a lower triangular matrix and its conjugate transpose, which is useful for efficient numerical solutions, e.g., Monte Carlo simulations. It was discovered by André-Louis Cholesky for real matrices, and posthumously published in 1924. When it is applicable, the Cholesky decomposition is roughly twice as efficient as the LU decomposition for solving systems of linear equations.
In the mathematical discipline of linear algebra, a matrix decomposition or matrix factorization is a factorization of a matrix into a product of matrices. There are many different matrix decompositions; each finds use among a particular class of problems.

In numerical analysis and scientific computing, a sparse matrix or sparse array is a matrix in which most of the elements are zero. There is no strict definition regarding the proportion of zero-value elements for a matrix to qualify as sparse but a common criterion is that the number of non-zero elements is roughly equal to the number of rows or columns. By contrast, if most of the elements are non-zero, the matrix is considered dense. The number of zero-valued elements divided by the total number of elements is sometimes referred to as the sparsity of the matrix.
An integer programming problem is a mathematical optimization or feasibility program in which some or all of the variables are restricted to be integers. In many settings the term refers to integer linear programming (ILP), in which the objective function and the constraints are linear.

In numerical linear algebra, the Cuthill–McKee algorithm (CM), named after Elizabeth Cuthill and James McKee, is an algorithm to permute a sparse matrix that has a symmetric sparsity pattern into a band matrix form with a small bandwidth. The reverse Cuthill–McKee algorithm (RCM) due to Alan George and Joseph Liu is the same algorithm but with the resulting index numbers reversed. In practice this generally results in less fill-in than the CM ordering when Gaussian elimination is applied.
In the mathematical subfield of numerical analysis the symbolic Cholesky decomposition is an algorithm used to determine the non-zero pattern for the factors of a symmetric sparse matrix when applying the Cholesky decomposition or variants.
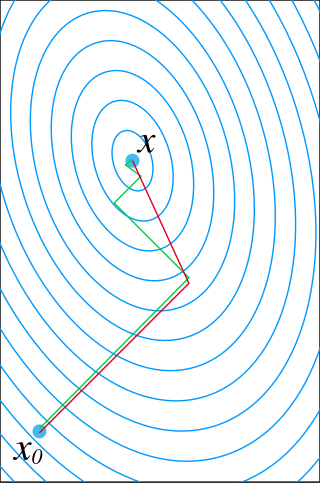
In mathematics, the conjugate gradient method is an algorithm for the numerical solution of particular systems of linear equations, namely those whose matrix is positive-semidefinite. The conjugate gradient method is often implemented as an iterative algorithm, applicable to sparse systems that are too large to be handled by a direct implementation or other direct methods such as the Cholesky decomposition. Large sparse systems often arise when numerically solving partial differential equations or optimization problems.
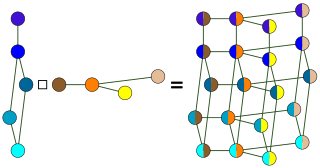
In graph theory, the Cartesian productG □ H of graphs G and H is a graph such that:
Non-negative matrix factorization, also non-negative matrix approximation is a group of algorithms in multivariate analysis and linear algebra where a matrix V is factorized into (usually) two matrices W and H, with the property that all three matrices have no negative elements. This non-negativity makes the resulting matrices easier to inspect. Also, in applications such as processing of audio spectrograms or muscular activity, non-negativity is inherent to the data being considered. Since the problem is not exactly solvable in general, it is commonly approximated numerically.
In mathematics, preconditioning is the application of a transformation, called the preconditioner, that conditions a given problem into a form that is more suitable for numerical solving methods. Preconditioning is typically related to reducing a condition number of the problem. The preconditioned problem is then usually solved by an iterative method.
In numerical analysis and linear algebra, lower–upper (LU) decomposition or factorization factors a matrix as the product of a lower triangular matrix and an upper triangular matrix. The product sometimes includes a permutation matrix as well. LU decomposition can be viewed as the matrix form of Gaussian elimination. Computers usually solve square systems of linear equations using LU decomposition, and it is also a key step when inverting a matrix or computing the determinant of a matrix. The LU decomposition was introduced by the Polish astronomer Tadeusz Banachiewicz in 1938. To quote: "It appears that Gauss and Doolittle applied the method [of elimination] only to symmetric equations. More recent authors, for example, Aitken, Banachiewicz, Dwyer, and Crout … have emphasized the use of the method, or variations of it, in connection with non-symmetric problems … Banachiewicz … saw the point … that the basic problem is really one of matrix factorization, or “decomposition” as he called it." It is also sometimes referred to as LR decomposition.
Numerical linear algebra, sometimes called applied linear algebra, is the study of how matrix operations can be used to create computer algorithms which efficiently and accurately provide approximate answers to questions in continuous mathematics. It is a subfield of numerical analysis, and a type of linear algebra. Computers use floating-point arithmetic and cannot exactly represent irrational data, so when a computer algorithm is applied to a matrix of data, it can sometimes increase the difference between a number stored in the computer and the true number that it is an approximation of. Numerical linear algebra uses properties of vectors and matrices to develop computer algorithms that minimize the error introduced by the computer, and is also concerned with ensuring that the algorithm is as efficient as possible.
In numerical linear algebra, an incomplete LU factorization of a matrix is a sparse approximation of the LU factorization often used as a preconditioner.
In numerical analysis, an incomplete Cholesky factorization of a symmetric positive definite matrix is a sparse approximation of the Cholesky factorization. An incomplete Cholesky factorization is often used as a preconditioner for algorithms like the conjugate gradient method.
In linear algebra, eigendecomposition is the factorization of a matrix into a canonical form, whereby the matrix is represented in terms of its eigenvalues and eigenvectors. Only diagonalizable matrices can be factorized in this way. When the matrix being factorized is a normal or real symmetric matrix, the decomposition is called "spectral decomposition", derived from the spectral theorem.
In graph theory, the cycle rank of a directed graph is a digraph connectivity measure proposed first by Eggan and Büchi. Intuitively, this concept measures how close a digraph is to a directed acyclic graph (DAG), in the sense that a DAG has cycle rank zero, while a complete digraph of order n with a self-loop at each vertex has cycle rank n. The cycle rank of a directed graph is closely related to the tree-depth of an undirected graph and to the star height of a regular language. It has also found use in sparse matrix computations and logic (Rossman 2008).
In numerical analysis, nested dissection is a divide and conquer heuristic for the solution of sparse symmetric systems of linear equations based on graph partitioning. Nested dissection was introduced by George (1973); the name was suggested by Garrett Birkhoff.
In statistics and machine learning, Gaussian process approximation is a computational method that accelerates inference tasks in the context of a Gaussian process model, most commonly likelihood evaluation and prediction. Like approximations of other models, they can often be expressed as additional assumptions imposed on the model, which do not correspond to any actual feature, but which retain its key properties while simplifying calculations. Many of these approximation methods can be expressed in purely linear algebraic or functional analytic terms as matrix or function approximations. Others are purely algorithmic and cannot easily be rephrased as a modification of a statistical model.








