Related Research Articles
Hidden Markov Model (HMM) is a statistical Markov model in which the system being modeled is assumed to be a Markov process – call it – with unobservable ("hidden") states. HMM assumes that there is another process whose behavior "depends" on . The goal is to learn about by observing . HMM stipulates that, for each time instance , the conditional probability distribution of given the history must NOT depend on .
Nonparametric statistics is the branch of statistics that is not based solely on parametrized families of probability distributions. Nonparametric statistics is based on either being distribution-free or having a specified distribution but with the distribution's parameters unspecified. Nonparametric statistics includes both descriptive statistics and statistical inference. Nonparametric tests are often used when the assumptions of parametric tests are violated.
Unsupervised learning is a type of machine learning that looks for previously undetected patterns in a data set with no pre-existing labels and with a minimum of human supervision. In contrast to supervised learning that usually makes use of human-labeled data, unsupervised learning, also known as self-organization allows for modeling of probability densities over inputs. It forms one of the three main categories of machine learning, along with supervised and reinforcement learning. Semi-supervised learning, a related variant, makes use of supervised and unsupervised techniques.
In physics, an observable is a physical quantity that can be measured. Examples include position and momentum. In systems governed by classical mechanics, it is a real-valued "function" on the set of all possible system states. In quantum physics, it is an operator, or gauge, where the property of the quantum state can be determined by some sequence of operations. For example, these operations might involve submitting the system to various electromagnetic fields and eventually reading a value.

Partial least squares regression is a statistical method that bears some relation to principal components regression; instead of finding hyperplanes of maximum variance between the response and independent variables, it finds a linear regression model by projecting the predicted variables and the observable variables to a new space. Because both the X and Y data are projected to new spaces, the PLS family of methods are known as bilinear factor models. Partial least squares discriminant analysis (PLS-DA) is a variant used when the Y is categorical.
Automated planning and scheduling, sometimes denoted as simply AI planning, is a branch of artificial intelligence that concerns the realization of strategies or action sequences, typically for execution by intelligent agents, autonomous robots and unmanned vehicles. Unlike classical control and classification problems, the solutions are complex and must be discovered and optimized in multidimensional space. Planning is also related to decision theory.
Latency or latent may refer to:
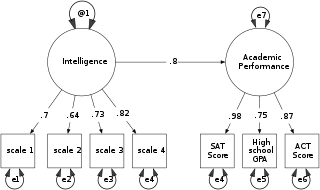
Structural equation modeling (SEM) includes a diverse set of mathematical models, computer algorithms, and statistical methods that fit networks of constructs to data. SEM includes confirmatory factor analysis, confirmatory composite analysis, path analysis, partial least squares path modeling, and latent growth modeling. The concept should not be confused with the related concept of structural models in econometrics, nor with structural models in economics. Structural equation models are often used to assess unobservable 'latent' constructs. They often invoke a measurement model that defines latent variables using one or more observed variables, and a structural model that imputes relationships between latent variables. The links between constructs of a structural equation model may be estimated with independent regression equations or through more involved approaches such as those employed in LISREL.
In statistics, latent variables are variables that are not directly observed but are rather inferred from other variables that are observed. Mathematical models that aim to explain observed variables in terms of latent variables are called latent variable models. Latent variable models are used in many disciplines, including psychology, demography, economics, engineering, medicine, physics, machine learning/artificial intelligence, bioinformatics, chemometrics, natural language processing, econometrics, management and the social sciences.
In quantum mechanics, the Kochen–Specker (KS) theorem, also known as the Bell–Kochen–Specker theorem, is a "no-go" theorem proved by John S. Bell in 1966 and by Simon B. Kochen and Ernst Specker in 1967. It places certain constraints on the permissible types of hidden-variable theories, which try to explain the predictions of quantum mechanics in a context-independent way. The version of the theorem proved by Kochen and Specker also gave an explicit example for this constraint in terms of a finite number of state vectors.
The behavioral approach to systems theory and control theory was initiated in the late-1970s by J. C. Willems as a result of resolving inconsistencies present in classical approaches based on state-space, transfer function, and convolution representations. This approach is also motivated by the aim of obtaining a general framework for system analysis and control that respects the underlying physics.
In statistics, a latent class model (LCM) relates a set of observed multivariate variables to a set of latent variables. It is a type of latent variable model. It is called a latent class model because the latent variable is discrete. A class is characterized by a pattern of conditional probabilities that indicate the chance that variables take on certain values.
A latent variable model is a statistical model that relates a set of observable variables to a set of latent variables.
In statistics, binomial regression is a regression analysis technique in which the response has a binomial distribution: it is the number of successes in a series of independent Bernoulli trials, where each trial has probability of success . In binomial regression, the probability of a success is related to explanatory variables: the corresponding concept in ordinary regression is to relate the mean value of the unobserved response to explanatory variables.

A construct in the philosophy of science is an ideal object, where the existence of the thing may be said to depend upon a subject's mind. This contrasts with a real object, where existence does not seem to depend on the existence of a mind.
In Bayesian inference, plate notation is a method of representing variables that repeat in a graphical model. Instead of drawing each repeated variable individually, a plate or rectangle is used to group variables into a subgraph that repeat together, and a number is drawn on the plate to represent the number of repetitions of the subgraph in the plate. The assumptions are that the subgraph is duplicated that many times, the variables in the subgraph are indexed by the repetition number, and any links that cross a plate boundary are replicated once for each subgraph repetition.
In statistics, a hidden Markov random field is a generalization of a hidden Markov model. Instead of having an underlying Markov chain, hidden Markov random fields have an underlying Markov random field.
In statistics, errors-in-variables models or measurement error models are regression models that account for measurement errors in the independent variables. In contrast, standard regression models assume that those regressors have been measured exactly, or observed without error; as such, those models account only for errors in the dependent variables, or responses.
In statistics, confirmatory composite analysis (CCA) is a sub-type of structural equation modeling (SEM). Although, historically, CCA emerged from a re-orientation and re-start of partial least squares path modeling (PLS-PM), it has become an independent approach and the two should not be confused. In many ways it is similar to, but also quite distinct from confirmatory factor analysis (CFA). It shares with CFA the process of model specification, model identification, model estimation, and model assessment. However, in contrast to CFA which always assumes the existence of latent variables, in CCA all variables can be observable, with their interrelationships expressed in terms of composites, i.e., linear compounds of subsets of the variables. The composites are treated as the fundamental objects and path diagrams can be used to illustrate their relationships. This makes CCA particularly useful for disciplines examining theoretical concepts that are designed to attain certain goals, so-called artifacts, and their interplay with theoretical concepts of behavioral sciences.
An energy-based model (EBM) is a form of generative model (GM). GMs learn an underlying data distribution by analyzing a sample dataset. Once trained, a GM can produce other datasets that also match the data distribution. EBMs provide a unified framework for many probabilistic and non-probabilistic approaches to such learning, particularly for training graphical and other structured models.
References
- ↑ Dodge, Y. (2003) The Oxford Dictionary of Statistical Terms, OUP. ISBN 0-19-920613-9
| This statistics-related article is a stub. You can help Wikipedia by expanding it. |