
In mathematics, the discrete Fourier transform (DFT) converts a finite sequence of equally-spaced samples of a function into a same-length sequence of equally-spaced samples of the discrete-time Fourier transform (DTFT), which is a complex-valued function of frequency. The interval at which the DTFT is sampled is the reciprocal of the duration of the input sequence. An inverse DFT is a Fourier series, using the DTFT samples as coefficients of complex sinusoids at the corresponding DTFT frequencies. It has the same sample-values as the original input sequence. The DFT is therefore said to be a frequency domain representation of the original input sequence. If the original sequence spans all the non-zero values of a function, its DTFT is continuous, and the DFT provides discrete samples of one cycle. If the original sequence is one cycle of a periodic function, the DFT provides all the non-zero values of one DTFT cycle.
In mathematics, a symmetric matrix with real entries is positive-definite if the real number is positive for every nonzero real column vector where is the transpose of . More generally, a Hermitian matrix is positive-definite if the real number is positive for every nonzero complex column vector where denotes the conjugate transpose of

The principal components of a collection of points in a real coordinate space are a sequence of unit vectors, where the -th vector is the direction of a line that best fits the data while being orthogonal to the first vectors. Here, a best-fitting line is defined as one that minimizes the average squared distance from the points to the line. These directions constitute an orthonormal basis in which different individual dimensions of the data are linearly uncorrelated. Principal component analysis (PCA) is the process of computing the principal components and using them to perform a change of basis on the data, sometimes using only the first few principal components and ignoring the rest.

In linear algebra, the singular value decomposition (SVD) is a factorization of a real or complex matrix. It generalizes the eigendecomposition of a square normal matrix with an orthonormal eigenbasis to any matrix. It is related to the polar decomposition.
In mathematics, a self-adjoint operator on an infinite-dimensional complex vector space V with inner product is a linear map A that is its own adjoint. If V is finite-dimensional with a given orthonormal basis, this is equivalent to the condition that the matrix of A is a Hermitian matrix, i.e., equal to its conjugate transpose A∗. By the finite-dimensional spectral theorem, V has an orthonormal basis such that the matrix of A relative to this basis is a diagonal matrix with entries in the real numbers. In this article, we consider generalizations of this concept to operators on Hilbert spaces of arbitrary dimension.
In linear algebra, a square matrix is called diagonalizable or non-defective if it is similar to a diagonal matrix, i.e., if there exists an invertible matrix and a diagonal matrix such that , or equivalently . For a finite-dimensional vector space , a linear map is called diagonalizable if there exists an ordered basis of consisting of eigenvectors of . These definitions are equivalent: if has a matrix representation as above, then the column vectors of form a basis consisting of eigenvectors of , and the diagonal entries of are the corresponding eigenvalues of ; with respect to this eigenvector basis, is represented by .Diagonalization is the process of finding the above and .
In physics, an operator is a function over a space of physical states onto another space of physical states. The simplest example of the utility of operators is the study of symmetry. Because of this, they are very useful tools in classical mechanics. Operators are even more important in quantum mechanics, where they form an intrinsic part of the formulation of the theory.

High-dimensional data, meaning data that requires more than two or three dimensions to represent, can be difficult to interpret. One approach to simplification is to assume that the data of interest lies within lower-dimensional space. If the data of interest is of low enough dimension, the data can be visualised in the low-dimensional space.

An eigenface is the name given to a set of eigenvectors when used in the computer vision problem of human face recognition. The approach of using eigenfaces for recognition was developed by Sirovich and Kirby and used by Matthew Turk and Alex Pentland in face classification. The eigenvectors are derived from the covariance matrix of the probability distribution over the high-dimensional vector space of face images. The eigenfaces themselves form a basis set of all images used to construct the covariance matrix. This produces dimension reduction by allowing the smaller set of basis images to represent the original training images. Classification can be achieved by comparing how faces are represented by the basis set.
In mathematics, a canonical basis is a basis of an algebraic structure that is canonical in a sense that depends on the precise context:
The Rayleigh–Ritz method is a direct numerical method of approximating eigenvalue, originated in the context of solving physical boundary value problems and named after Lord Rayleigh and Walther Ritz.
In linear algebra, an eigenvector or characteristic vector of a linear transformation is a nonzero vector that changes at most by a scalar factor when that linear transformation is applied to it. The corresponding eigenvalue, often denoted by , is the factor by which the eigenvector is scaled.
In quantum mechanics, the position operator is the operator that corresponds to the position observable of a particle.
In the field of multivariate statistics, kernel principal component analysis is an extension of principal component analysis (PCA) using techniques of kernel methods. Using a kernel, the originally linear operations of PCA are performed in a reproducing kernel Hilbert space.
In functional analysis, the concept of a compact operator on Hilbert space is an extension of the concept of a matrix acting on a finite-dimensional vector space; in Hilbert space, compact operators are precisely the closure of finite-rank operators in the topology induced by the operator norm. As such, results from matrix theory can sometimes be extended to compact operators using similar arguments. By contrast, the study of general operators on infinite-dimensional spaces often requires a genuinely different approach.
In linear algebra, eigendecomposition is the factorization of a matrix into a canonical form, whereby the matrix is represented in terms of its eigenvalues and eigenvectors. Only diagonalizable matrices can be factorized in this way. When the matrix being factorized is a normal or real symmetric matrix, the decomposition is called "spectral decomposition", derived from the spectral theorem.
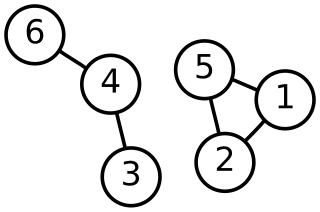
In multivariate statistics, spectral clustering techniques make use of the spectrum (eigenvalues) of the similarity matrix of the data to perform dimensionality reduction before clustering in fewer dimensions. The similarity matrix is provided as an input and consists of a quantitative assessment of the relative similarity of each pair of points in the dataset.
In statistics, principal component regression (PCR) is a regression analysis technique that is based on principal component analysis (PCA). More specifically, PCR is used for estimating the unknown regression coefficients in a standard linear regression model.
In mathematics, and especially affine differential geometry, the affine focal set of a smooth submanifold M embedded in a smooth manifold N is the caustic generated by the affine normal lines. It can be realised as the bifurcation set of a certain family of functions. The bifurcation set is the set of parameter values of the family which yield functions with degenerate singularities. This is not the same as the bifurcation diagram in dynamical systems.
In mathematics, particularly in linear algebra and applications, matrix analysis is the study of matrices and their algebraic properties. Some particular topics out of many include; operations defined on matrices, functions of matrices, and the eigenvalues of matrices.













