Within mathematical analysis, Regularization perspectives on support-vector machines provide a way of interpreting support-vector machines (SVMs) in the context of other regularization-based machine-learning algorithms. SVM algorithms categorize binary data, with the goal of fitting the training set data in a way that minimizes the average of the hinge-loss function and L2 norm of the learned weights. This strategy avoids overfitting via Tikhonov regularization and in the L2 norm sense and also corresponds to minimizing the bias and variance of our estimator of the weights. Estimators with lower Mean squared error predict better or generalize better when given unseen data.
Specifically, Tikhonov regularization algorithms produce a decision boundary that minimizes the average training-set error and constrain the Decision boundary not to be excessively complicated or overfit the training data via a L2 norm of the weights term. The training and test-set errors can be measured without bias and in a fair way using accuracy, precision, Auc-Roc, precision-recall, and other metrics.
Regularization perspectives on support-vector machines interpret SVM as a special case of Tikhonov regularization, specifically Tikhonov regularization with the hinge loss for a loss function. This provides a theoretical framework with which to analyze SVM algorithms and compare them to other algorithms with the same goals: to generalize without overfitting. SVM was first proposed in 1995 by Corinna Cortes and Vladimir Vapnik, and framed geometrically as a method for finding hyperplanes that can separate multidimensional data into two categories. [1] This traditional geometric interpretation of SVMs provides useful intuition about how SVMs work, but is difficult to relate to other machine-learning techniques for avoiding overfitting, like regularization, early stopping, sparsity and Bayesian inference. However, once it was discovered that SVM is also a special case of Tikhonov regularization, regularization perspectives on SVM provided the theory necessary to fit SVM within a broader class of algorithms. [2] [3] [4] This has enabled detailed comparisons between SVM and other forms of Tikhonov regularization, and theoretical grounding for why it is beneficial to use SVM's loss function, the hinge loss. [5]
Theoretical background
In the statistical learning theory framework, an algorithm is a strategy for choosing a function  given a training set
given a training set  of inputs
of inputs  and their labels
and their labels  (the labels are usually
(the labels are usually  ). Regularization strategies avoid overfitting by choosing a function that fits the data, but is not too complex. Specifically:
). Regularization strategies avoid overfitting by choosing a function that fits the data, but is not too complex. Specifically:

where  is a hypothesis space [6] of functions,
is a hypothesis space [6] of functions,  is the loss function,
is the loss function,  is a norm on the hypothesis space of functions, and
is a norm on the hypothesis space of functions, and  is the regularization parameter. [7]
is the regularization parameter. [7]
When is a reproducing kernel Hilbert space, there exists a kernel function  that can be written as an
that can be written as an  symmetric positive-definite matrix
symmetric positive-definite matrix  . By the representer theorem, [8]
. By the representer theorem, [8]

Special properties of the hinge loss

The simplest and most intuitive loss function for categorization is the misclassification loss, or 0–1 loss, which is 0 if  and 1 if
and 1 if  , i.e. the Heaviside step function on
, i.e. the Heaviside step function on  . However, this loss function is not convex, which makes the regularization problem very difficult to minimize computationally. Therefore, we look for convex substitutes for the 0–1 loss. The hinge loss,
. However, this loss function is not convex, which makes the regularization problem very difficult to minimize computationally. Therefore, we look for convex substitutes for the 0–1 loss. The hinge loss,  , where
, where  , provides such a convex relaxation. In fact, the hinge loss is the tightest convex upper bound to the 0–1 misclassification loss function, [4] and with infinite data returns the Bayes-optimal solution: [5] [9]
, provides such a convex relaxation. In fact, the hinge loss is the tightest convex upper bound to the 0–1 misclassification loss function, [4] and with infinite data returns the Bayes-optimal solution: [5] [9]


In machine learning, support-vector machines are supervised learning models with associated learning algorithms that analyze data for classification and regression analysis. Developed at AT&T Bell Laboratories by Vladimir Vapnik with colleagues SVMs are one of the most robust prediction methods, being based on statistical learning frameworks or VC theory proposed by Vapnik and Chervonenkis (1974). Given a set of training examples, each marked as belonging to one of two categories, an SVM training algorithm builds a model that assigns new examples to one category or the other, making it a non-probabilistic binary linear classifier. SVM maps training examples to points in space so as to maximise the width of the gap between the two categories. New examples are then mapped into that same space and predicted to belong to a category based on which side of the gap they fall.
In the field of machine learning, the goal of statistical classification is to use an object's characteristics to identify which class it belongs to. A linear classifier achieves this by making a classification decision based on the value of a linear combination of the characteristics. An object's characteristics are also known as feature values and are typically presented to the machine in a vector called a feature vector. Such classifiers work well for practical problems such as document classification, and more generally for problems with many variables (features), reaching accuracy levels comparable to non-linear classifiers while taking less time to train and use.
In machine learning, early stopping is a form of regularization used to avoid overfitting when training a learner with an iterative method, such as gradient descent. Such methods update the learner so as to make it better fit the training data with each iteration. Up to a point, this improves the learner's performance on data outside of the training set. Past that point, however, improving the learner's fit to the training data comes at the expense of increased generalization error. Early stopping rules provide guidance as to how many iterations can be run before the learner begins to over-fit. Early stopping rules have been employed in many different machine learning methods, with varying amounts of theoretical foundation.
Multi-task learning (MTL) is a subfield of machine learning in which multiple learning tasks are solved at the same time, while exploiting commonalities and differences across tasks. This can result in improved learning efficiency and prediction accuracy for the task-specific models, when compared to training the models separately. Early versions of MTL were called "hints".
Statistical learning theory is a framework for machine learning drawing from the fields of statistics and functional analysis. Statistical learning theory deals with the statistical inference problem of finding a predictive function based on data. Statistical learning theory has led to successful applications in fields such as computer vision, speech recognition, and bioinformatics.
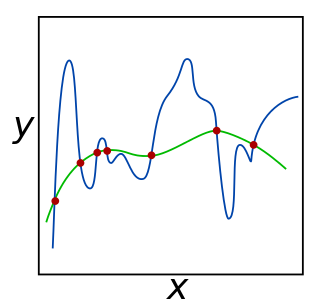
In mathematics, statistics, finance, computer science, particularly in machine learning and inverse problems, regularization is a process that changes the result answer to be "simpler". It is often used to obtain results for ill-posed problems or to prevent overfitting.

Semi-supervised learning is an approach to machine learning that combines a small amount of labeled data with a large amount of unlabeled data during training. Semi-supervised learning falls between unsupervised learning and supervised learning. It is a special instance of weak supervision.
In machine learning, kernel machines are a class of algorithms for pattern analysis, whose best known member is the support-vector machine (SVM). Less commonly known includes the Importance Vector Machine, and Kernel PCA The general task of pattern analysis is to find and study general types of relations in datasets. For many algorithms that solve these tasks, the data in raw representation have to be explicitly transformed into feature vector representations via a user-specified feature map: in contrast, kernel methods require only a user-specified kernel, i.e., a similarity function over all pairs of data points computed using Inner products. The feature map in kernel machines is infinite dimensional but only requires a finite dimensional matrix from user-input according to the Representer theorem. Kernel machines are slow to compute for datasets larger than a couple of thousand examples without parallel processing.
Augmented Lagrangian methods are a certain class of algorithms for solving constrained optimization problems. They have similarities to penalty methods in that they replace a constrained optimization problem by a series of unconstrained problems and add a penalty term to the objective; the difference is that the augmented Lagrangian method adds yet another term, designed to mimic a Lagrange multiplier. The augmented Lagrangian is related to, but not identical with the method of Lagrange multipliers.

In machine learning, the hinge loss is a loss function used for training classifiers. The hinge loss is used for "maximum-margin" classification, most notably for support vector machines (SVMs).
In statistics and, in particular, in the fitting of linear or logistic regression models, the elastic net is a regularized regression method that linearly combines the L1 and L2 penalties of the lasso and ridge methods.
Within bayesian statistics for machine learning, kernel methods arise from the assumption of an inner product space or similarity structure on inputs. For some such methods, such as support vector machines (SVMs), the original formulation and its regularization were not Bayesian in nature. It is helpful to understand them from a Bayesian perspective. Because the kernels are not necessarily positive semidefinite, the underlying structure may not be inner product spaces, but instead more general reproducing kernel Hilbert spaces. In Bayesian probability kernel methods are a key component of Gaussian processes, where the kernel function is known as the covariance function. Kernel methods have traditionally been used in supervised learning problems where the input space is usually a space of vectors while the output space is a space of scalars. More recently these methods have been extended to problems that deal with multiple outputs such as in multi-task learning.
For computer science, in statistical learning theory, a representer theorem is any of several related results stating that a minimizer of a regularized empirical risk functional defined over a reproducing kernel Hilbert space can be represented as a finite linear combination of kernel products evaluated on the input points in the training set data.
Spectral regularization is any of a class of regularization techniques used in machine learning to control the impact of noise and prevent overfitting. Spectral regularization can be used in a broad range of applications, from deblurring images to classifying emails into a spam folder and a non-spam folder. For instance, in the email classification example, spectral regularization can be used to reduce the impact of noise and prevent overfitting when a machine learning system is being trained on a labeled set of emails to learn how to tell a spam and a non-spam email apart.
In machine learning, the kernel embedding of distributions comprises a class of nonparametric methods in which a probability distribution is represented as an element of a reproducing kernel Hilbert space (RKHS). A generalization of the individual data-point feature mapping done in classical kernel methods, the embedding of distributions into infinite-dimensional feature spaces can preserve all of the statistical features of arbitrary distributions, while allowing one to compare and manipulate distributions using Hilbert space operations such as inner products, distances, projections, linear transformations, and spectral analysis. This learning framework is very general and can be applied to distributions over any space on which a sensible kernel function may be defined. For example, various kernels have been proposed for learning from data which are: vectors in , discrete classes/categories, strings, graphs/networks, images, time series, manifolds, dynamical systems, and other structured objects. The theory behind kernel embeddings of distributions has been primarily developed by Alex Smola, Le Song , Arthur Gretton, and Bernhard Schölkopf. A review of recent works on kernel embedding of distributions can be found in.
Kernel methods are a well-established tool to analyze the relationship between input data and the corresponding output of a function. Kernels encapsulate the properties of functions in a computationally efficient way and allow algorithms to easily swap functions of varying complexity.

In machine learning and mathematical optimization, loss functions for classification are computationally feasible loss functions representing the price paid for inaccuracy of predictions in classification problems. Given as the space of all possible inputs, and as the set of labels, a typical goal of classification algorithms is to find a function which best predicts a label for a given input . However, because of incomplete information, noise in the measurement, or probabilistic components in the underlying process, it is possible for the same to generate different . As a result, the goal of the learning problem is to minimize expected loss, defined as
In the field of statistical learning theory, matrix regularization generalizes notions of vector regularization to cases where the object to be learned is a matrix. The purpose of regularization is to enforce conditions, for example sparsity or smoothness, that can produce stable predictive functions. For example, in the more common vector framework, Tikhonov regularization optimizes over
In machine learning, Manifold regularization is a technique for using the shape of a dataset to constrain the functions that should be learned on that dataset. In many machine learning problems, the data to be learned do not cover the entire input space. For example, a facial recognition system may not need to classify any possible image, but only the subset of images that contain faces. The technique of manifold learning assumes that the relevant subset of data comes from a manifold, a mathematical structure with useful properties. The technique also assumes that the function to be learned is smooth: data with different labels are not likely to be close together, and so the labeling function should not change quickly in areas where there are likely to be many data points. Because of this assumption, a manifold regularization algorithm can use unlabeled data to inform where the learned function is allowed to change quickly and where it is not, using an extension of the technique of Tikhonov regularization. Manifold regularization algorithms can extend supervised learning algorithms in semi-supervised learning and transductive learning settings, where unlabeled data are available. The technique has been used for applications including medical imaging, geographical imaging, and object recognition.
Regularized least squares (RLS) is a family of methods for solving the least-squares problem while using regularization to further constrain the resulting solution.





