Natural language processing (NLP) is an interdisciplinary subfield of computer science and artificial intelligence. It is primarily concerned with providing computers with the ability to process data encoded in natural language and is thus closely related to information retrieval, knowledge representation and computational linguistics, a subfield of linguistics. Typically data is collected in text corpora, using either rule-based, statistical or neural-based approaches in machine learning and deep learning.
Information extraction (IE) is the task of automatically extracting structured information from unstructured and/or semi-structured machine-readable documents and other electronically represented sources. Typically, this involves processing human language texts by means of natural language processing (NLP). Recent activities in multimedia document processing like automatic annotation and content extraction out of images/audio/video/documents could be seen as information extraction.
Shallow parsing is an analysis of a sentence which first identifies constituent parts of sentences and then links them to higher order units that have discrete grammatical meanings. While the most elementary chunking algorithms simply link constituent parts on the basis of elementary search patterns, approaches that use machine learning techniques can take contextual information into account and thus compose chunks in such a way that they better reflect the semantic relations between the basic constituents. That is, these more advanced methods get around the problem that combinations of elementary constituents can have different higher level meanings depending on the context of the sentence.
Biomedical text mining refers to the methods and study of how text mining may be applied to texts and literature of the biomedical domain. As a field of research, biomedical text mining incorporates ideas from natural language processing, bioinformatics, medical informatics and computational linguistics. The strategies in this field have been applied to the biomedical literature available through services such as PubMed.
Sentence boundary disambiguation (SBD), also known as sentence breaking, sentence boundary detection, and sentence segmentation, is the problem in natural language processing of deciding where sentences begin and end. Natural language processing tools often require their input to be divided into sentences; however, sentence boundary identification can be challenging due to the potential ambiguity of punctuation marks. In written English, a period may indicate the end of a sentence, or may denote an abbreviation, a decimal point, an ellipsis, or an email address, among other possibilities. About 47% of the periods in The Wall Street Journal corpus denote abbreviations. Question marks and exclamation marks can be similarly ambiguous due to use in emoticons, source code, and slang.

The Apache OpenNLP library is a machine learning based toolkit for the processing of natural language text. It supports the most common NLP tasks, such as language detection, tokenization, sentence segmentation, part-of-speech tagging, named entity extraction, chunking, parsing and coreference resolution. These tasks are usually required to build more advanced text processing services.

Apache cTAKES: clinical Text Analysis and Knowledge Extraction System is an open-source Natural Language Processing (NLP) system that extracts clinical information from electronic health record unstructured text. It processes clinical notes, identifying types of clinical named entities — drugs, diseases/disorders, signs/symptoms, anatomical sites and procedures. Each named entity has attributes for the text span, the ontology mapping code, context, and negated/not negated.
The following outline is provided as an overview of and topical guide to natural-language processing:
Eclipse Deeplearning4j is a programming library written in Java for the Java virtual machine (JVM). It is a framework with wide support for deep learning algorithms. Deeplearning4j includes implementations of the restricted Boltzmann machine, deep belief net, deep autoencoder, stacked denoising autoencoder and recursive neural tensor network, word2vec, doc2vec, and GloVe. These algorithms all include distributed parallel versions that integrate with Apache Hadoop and Spark.
In natural language processing (NLP), a word embedding is a representation of a word. The embedding is used in text analysis. Typically, the representation is a real-valued vector that encodes the meaning of the word in such a way that the words that are closer in the vector space are expected to be similar in meaning. Word embeddings can be obtained using language modeling and feature learning techniques, where words or phrases from the vocabulary are mapped to vectors of real numbers.
Word2vec is a technique in natural language processing (NLP) for obtaining vector representations of words. These vectors capture information about the meaning of the word based on the surrounding words. The word2vec algorithm estimates these representations by modeling text in a large corpus. Once trained, such a model can detect synonymous words or suggest additional words for a partial sentence. Word2vec was developed by Tomáš Mikolov and colleagues at Google and published in 2013.
GloVe, coined from Global Vectors, is a model for distributed word representation. The model is an unsupervised learning algorithm for obtaining vector representations for words. This is achieved by mapping words into a meaningful space where the distance between words is related to semantic similarity. Training is performed on aggregated global word-word co-occurrence statistics from a corpus, and the resulting representations showcase interesting linear substructures of the word vector space. As log-bilinear regression model for unsupervised learning of word representations, it combines the features of two model families, namely the global matrix factorization and local context window methods.

A notebook interface or computational notebook is a virtual notebook environment used for literate programming, a method of writing computer programs. Some notebooks are WYSIWYG environments including executable calculations embedded in formatted documents; others separate calculations and text into separate sections. Notebooks share some goals and features with spreadsheets and word processors but go beyond their limited data models.

spaCy is an open-source software library for advanced natural language processing, written in the programming languages Python and Cython. The library is published under the MIT license and its main developers are Matthew Honnibal and Ines Montani, the founders of the software company Explosion.
Paraphrase or paraphrasing in computational linguistics is the natural language processing task of detecting and generating paraphrases. Applications of paraphrasing are varied including information retrieval, question answering, text summarization, and plagiarism detection. Paraphrasing is also useful in the evaluation of machine translation, as well as semantic parsing and generation of new samples to expand existing corpora.
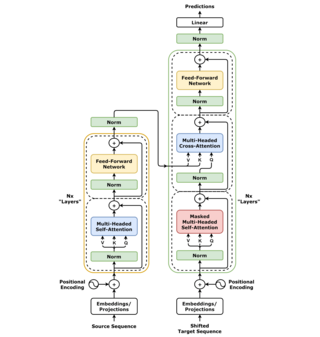
A transformer is a deep learning architecture developed by researchers at Google and based on the multi-head attention mechanism, proposed in a 2017 paper "Attention Is All You Need". Text is converted to numerical representations called tokens, and each token is converted into a vector via looking up from a word embedding table. At each layer, each token is then contextualized within the scope of the context window with other (unmasked) tokens via a parallel multi-head attention mechanism allowing the signal for key tokens to be amplified and less important tokens to be diminished.
Bidirectional encoder representations from transformers (BERT) is a language model introduced in October 2018 by researchers at Google. It learned by self-supervised learning to represent text as a sequence of vectors. It had the transformer encoder architecture. It was notable for its dramatic improvement over previous state of the art models, and as an early example of large language model. As of 2020, BERT was a ubiquitous baseline in natural language processing (NLP) experiments.

ELMo is a word embedding method for representing a sequence of words as a corresponding sequence of vectors. It was created by researchers at the Allen Institute for Artificial Intelligence, and University of Washington and first released in February, 2018. It is a bidirectional LSTM which takes character-level as inputs and produces word-level embeddings.

GPT-J or GPT-J-6B is an open-source large language model (LLM) developed by EleutherAI in 2021. As the name suggests, it is a generative pre-trained transformer model designed to produce human-like text that continues from a prompt. The optional "6B" in the name refers to the fact that it has 6 billion parameters.