
HyperText Markup Language or HTML is the standard markup language for documents designed to be displayed in a web browser. It defines the content and structure of web content. It is often assisted by technologies such as Cascading Style Sheets (CSS) and scripting languages such as JavaScript.
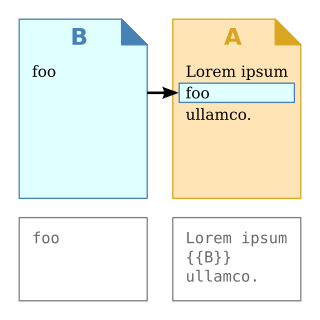
In computer science, transclusion is the inclusion of part or all of an electronic document into one or more other documents by reference via hypertext. Transclusion is usually performed when the referencing document is displayed, and is normally automatic and transparent to the end user. The result of transclusion is a single integrated document made of parts assembled dynamically from separate sources, possibly stored on different computers in disparate places.

The Standard Generalized Markup Language is a standard for defining generalized markup languages for documents. ISO 8879 Annex A.1 states that generalized markup is "based on two postulates":

A wiki is a form of online hypertext publication that is collaboratively edited and managed by its own audience directly through a web browser. A typical wiki contains multiple pages for the subjects or scope of the project, and could be either open to the public or limited to use within an organization for maintaining its internal knowledge base.

Extensible Markup Language (XML) is a markup language and file format for storing, transmitting, and reconstructing arbitrary data. It defines a set of rules for encoding documents in a format that is both human-readable and machine-readable. The World Wide Web Consortium's XML 1.0 Specification of 1998 and several other related specifications—all of them free open standards—define XML.
An HTML element is a type of HTML document component, one of several types of HTML nodes. The first used version of HTML was written by Tim Berners-Lee in 1993 and there have since been many versions of HTML. The current de facto standard is governed by the industry group WHATWG and is known as the HTML Living Standard.

MediaWiki is free and open-source wiki software originally developed by Magnus Manske for use on Wikipedia on January 25, 2002, and further improved by Lee Daniel Crocker, after which it has been coordinated by the Wikimedia Foundation. It powers several wiki hosting websites across the Internet, as well as most websites hosted by the Foundation including Wikipedia, Wiktionary, Wikimedia Commons, Wikiquote, Meta-Wiki and Wikidata, which define a large part of the set requirements for the software. MediaWiki is written in the PHP programming language and stores all text content into a database. The software is optimized to efficiently handle large projects, which can have terabytes of content and hundreds of thousands of views per second. Because Wikipedia is one of the world's largest and most visited websites, achieving scalability through multiple layers of caching and database replication has been a major concern for developers. Another major aspect of MediaWiki is its internationalization; its interface is available in more than 400 languages. The software has more than 1,000 configuration settings and more than 1,800 extensions available for enabling various features to be added or changed. Besides its usage on Wikimedia sites, MediaWiki has been used as a knowledge management and content management system on websites such as Fandom, wikiHow and major internal installations like Intellipedia and Diplopedia.
In web development, "tag soup" is a pejorative for HTML written for a web page that is syntactically or structurally incorrect. Web browsers have historically treated structural or syntax errors in HTML leniently, so there has been little pressure for web developers to follow published standards. Therefore there is a need for all browser implementations to provide mechanisms to cope with the appearance of "tag soup", accepting and correcting for invalid syntax and structure where possible.
A lightweight markup language (LML), also termed a simple or humane markup language, is a markup language with simple, unobtrusive syntax. It is designed to be easy to write using any generic text editor and easy to read in its raw form. Lightweight markup languages are used in applications where it may be necessary to read the raw document as well as the final rendered output.
XFA stands for XML Forms Architecture, a family of proprietary XML specifications that was suggested and developed by JetForm to enhance the processing of web forms. It can be also used in PDF files starting with the PDF 1.5 specification. The XFA specification is referenced as an external specification necessary for full application of the ISO 32000-1 specification. The XML Forms Architecture was not standardized as an ISO standard, and has been deprecated in PDF 2.0.
The following tables compare general and technical information for many wiki software packages.
Microformats (μF) are a set of defined HTML classes created to serve as consistent and descriptive metadata about an element, designating it as representing a certain type of data. They allow software to process the information reliably by having set classes refer to a specific type of data rather than being arbitrary. Microformats emerged around 2005 and were predominantly designed for use by search engines, web syndication and aggregators such as RSS.
The term CDATA, meaning character data, is used for distinct, but related, purposes in the markup languages SGML and XML. The term indicates that a certain portion of the document is general character data, rather than non-character data or character data with a more specific, limited structure.
Data exchange is the process of taking data structured under a source schema and transforming it into a target schema, so that the target data is an accurate representation of the source data. Data exchange allows data to be shared between different computer programs.
Advanced Content provides interactivity in the HD DVD optical disc format.
Extensible HyperText Markup Language (XHTML) is part of the family of XML markup languages which mirrors or extends versions of the widely used HyperText Markup Language (HTML), the language in which Web pages are formulated.

MoinMoin is a wiki engine implemented in Python, initially based on the PikiPiki wiki engine. Its name is a play on the North German greeting Moin, repeated as in WikiWiki. The MoinMoin code is licensed under the GNU General Public License v2, or any later version.
Creole is a lightweight markup language, aimed at being a common markup language for wikis, enabling and simplifying the transfer of content between different wiki engines.
A structured document is an electronic document where some method of markup is used to identify the whole and parts of the document as having various meanings beyond their formatting. For example, a structured document might identify a certain portion as a "chapter title" rather than as "Helvetica bold 24" or "indented Courier". Such portions in general are commonly called "components" or "elements" of a document.

Yesod is a web framework based on the programming language Haskell for productive development of type-safe, representational state transfer (REST) model based, high performance web applications, developed by Michael Snoyman, et al. It is free and open-source software released under an MIT License.