Related Research Articles
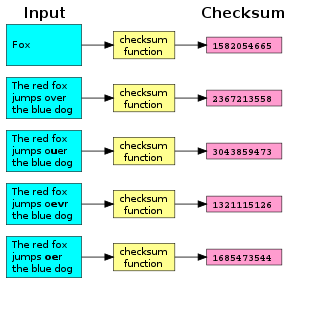
A checksum is a small-sized block of data derived from another block of digital data for the purpose of detecting errors that may have been introduced during its transmission or storage. By themselves, checksums are often used to verify data integrity but are not relied upon to verify data authenticity.

In information theory and coding theory with applications in computer science and telecommunication, error detection and correction (EDAC) or error control are techniques that enable reliable delivery of digital data over unreliable communication channels. Many communication channels are subject to channel noise, and thus errors may be introduced during transmission from the source to a receiver. Error detection techniques allow detecting such errors, while error correction enables reconstruction of the original data in many cases.
A cyclic redundancy check (CRC) is an error-detecting code commonly used in digital networks and storage devices to detect accidental changes to digital data. Blocks of data entering these systems get a short check value attached, based on the remainder of a polynomial division of their contents. On retrieval, the calculation is repeated and, in the event the check values do not match, corrective action can be taken against data corruption. CRCs can be used for error correction.
In computer science and telecommunication, Hamming codes are a family of linear error-correcting codes. Hamming codes can detect one-bit and two-bit errors, or correct one-bit errors without detection of uncorrected errors. By contrast, the simple parity code cannot correct errors, and can detect only an odd number of bits in error. Hamming codes are perfect codes, that is, they achieve the highest possible rate for codes with their block length and minimum distance of three. Richard W. Hamming invented Hamming codes in 1950 as a way of automatically correcting errors introduced by punched card readers. In his original paper, Hamming elaborated his general idea, but specifically focused on the Hamming(7,4) code which adds three parity bits to four bits of data.
In telecommunication, a longitudinal redundancy check (LRC), or horizontal redundancy check, is a form of redundancy check that is applied independently to each of a parallel group of bit streams. The data must be divided into transmission blocks, to which the additional check data is added.
RAID is a data storage virtualization technology that combines multiple physical disk drive components into one or more logical units for the purposes of data redundancy, performance improvement, or both. This is in contrast to the previous concept of highly reliable mainframe disk drives referred to as "single large expensive disk" (SLED).

In computing, a serial port is a serial communication interface through which information transfers in or out sequentially one bit at a time. This is in contrast to a parallel port, which communicates multiple bits simultaneously in parallel. Throughout most of the history of personal computers, data has been transferred through serial ports to devices such as modems, terminals, various peripherals, and directly between computers.
A parity bit, or check bit, is a bit added to a string of binary code. Parity bits are a simple form of error detecting code. Parity bits are generally applied to the smallest units of a communication protocol, typically 8-bit octets (bytes), although they can also be applied separately to an entire message string of bits.

Coding theory is the study of the properties of codes and their respective fitness for specific applications. Codes are used for data compression, cryptography, error detection and correction, data transmission and data storage. Codes are studied by various scientific disciplines—such as information theory, electrical engineering, mathematics, linguistics, and computer science—for the purpose of designing efficient and reliable data transmission methods. This typically involves the removal of redundancy and the correction or detection of errors in the transmitted data.
In information theory, turbo codes are a class of high-performance forward error correction (FEC) codes developed around 1990–91, but first published in 1993. They were the first practical codes to closely approach the maximum channel capacity or Shannon limit, a theoretical maximum for the code rate at which reliable communication is still possible given a specific noise level. Turbo codes are used in 3G/4G mobile communications and in satellite communications as well as other applications where designers seek to achieve reliable information transfer over bandwidth- or latency-constrained communication links in the presence of data-corrupting noise. Turbo codes compete with low-density parity-check (LDPC) codes, which provide similar performance.
In information theory, a low-density parity-check (LDPC) code is a linear error correcting code, a method of transmitting a message over a noisy transmission channel. An LDPC code is constructed using a sparse Tanner graph. LDPC codes are capacity-approaching codes, which means that practical constructions exist that allow the noise threshold to be set very close to the theoretical maximum for a symmetric memoryless channel. The noise threshold defines an upper bound for the channel noise, up to which the probability of lost information can be made as small as desired. Using iterative belief propagation techniques, LDPC codes can be decoded in time linear to their block length.

Data corruption refers to errors in computer data that occur during writing, reading, storage, transmission, or processing, which introduce unintended changes to the original data. Computer, transmission, and storage systems use a number of measures to provide end-to-end data integrity, or lack of errors.
In coding theory, an erasure code is a forward error correction (FEC) code under the assumption of bit erasures, which transforms a message of k symbols into a longer message with n symbols such that the original message can be recovered from a subset of the n symbols. The fraction r = k/n is called the code rate. The fraction k’/k, where k’ denotes the number of symbols required for recovery, is called reception efficiency.
RAM parity checking is the storing of a redundant parity bit representing the parity of a small amount of computer data stored in random-access memory, and the subsequent comparison of the stored and the computed parity to detect whether a data error has occurred.
Hybrid automatic repeat request is a combination of high-rate forward error correction (FEC) and automatic repeat request (ARQ) error-control. In standard ARQ, redundant bits are added to data to be transmitted using an error-detecting (ED) code such as a cyclic redundancy check (CRC). Receivers detecting a corrupted message will request a new message from the sender. In Hybrid ARQ, the original data is encoded with an FEC code, and the parity bits are either immediately sent along with the message or only transmitted upon request when a receiver detects an erroneous message. The ED code may be omitted when a code is used that can perform both forward error correction (FEC) in addition to error detection, such as a Reed–Solomon code. The FEC code is chosen to correct an expected subset of all errors that may occur, while the ARQ method is used as a fall-back to correct errors that are uncorrectable using only the redundancy sent in the initial transmission. As a result, hybrid ARQ performs better than ordinary ARQ in poor signal conditions, but in its simplest form this comes at the expense of significantly lower throughput in good signal conditions. There is typically a signal quality cross-over point below which simple hybrid ARQ is better, and above which basic ARQ is better.
In computing, telecommunication, information theory, and coding theory, forward error correction (FEC) or channel coding is a technique used for controlling errors in data transmission over unreliable or noisy communication channels.

Error correction code memory is a type of computer data storage that uses an error correction code (ECC) to detect and correct n-bit data corruption which occurs in memory. ECC memory is used in most computers where data corruption cannot be tolerated, like industrial control applications, critical databases, and infrastructural memory caches.
In computer main memory, auxiliary storage and computer buses, data redundancy is the existence of data that is additional to the actual data and permits correction of errors in stored or transmitted data. The additional data can simply be a complete copy of the actual data, or only select pieces of data that allow detection of errors and reconstruction of lost or damaged data up to a certain level.
In computer storage, the standard RAID levels comprise a basic set of RAID configurations that employ the techniques of striping, mirroring, or parity to create large reliable data stores from multiple general-purpose computer hard disk drives (HDDs). The most common types are RAID 0 (striping), RAID 1 (mirroring) and its variants, RAID 5, and RAID 6. Multiple RAID levels can also be combined or nested, for instance RAID 10 or RAID 01. RAID levels and their associated data formats are standardized by the Storage Networking Industry Association (SNIA) in the Common RAID Disk Drive Format (DDF) standard. The numerical values only serve as identifiers and do not signify performance, reliability, generation, or any other metric.
In coding theory, Hamming(7,4) is a linear error-correcting code that encodes four bits of data into seven bits by adding three parity bits. It is a member of a larger family of Hamming codes, but the term Hamming code often refers to this specific code that Richard W. Hamming introduced in 1950. At the time, Hamming worked at Bell Telephone Laboratories and was frustrated with the error-prone punched card reader, which is why he started working on error-correcting codes.
References
 This article incorporates public domain material from Federal Standard 1037C. General Services Administration. (in support of MIL-STD-188).
This article incorporates public domain material from Federal Standard 1037C. General Services Administration. (in support of MIL-STD-188).