Related Research Articles
In computer science, consistency models are used in distributed systems like distributed shared memory systems or distributed data stores. The system is said to support a given model if operations on memory follow specific rules. The data consistency model specifies a contract between programmer and system, wherein the system guarantees that if the programmer follows the rules, memory will be consistent and the results of reading, writing, or updating memory will be predictable. This is different from coherence, which occurs in systems that are cached or cache-less, and is consistency of data with respect to all processors. Coherence deals with maintaining a global order in which writes to a single location or single variable are seen by all processors. Consistency deals with the ordering of operations to multiple locations with respect to all processors.

In electromagnetism, displacement current density is the quantity ∂D/∂t appearing in Maxwell's equations that is defined in terms of the rate of change of D, the electric displacement field. Displacement current density has the same units as electric current density, and it is a source of the magnetic field just as actual current is. However it is not an electric current of moving charges, but a time-varying electric field. In physical materials, there is also a contribution from the slight motion of charges bound in atoms, called dielectric polarization.
A Byzantine fault is a condition of a computer system, particularly distributed computing systems, where components may fail and there is imperfect information on whether a component has failed. The term takes its name from an allegory, the "Byzantine Generals Problem", developed to describe a situation in which, in order to avoid catastrophic failure of the system, the system's actors must agree on a concerted strategy, but some of these actors are unreliable.
The International Federation for Information Processing (IFIP) is a global organisation for researchers and professionals working in the field of computing to conduct research, develop standards and promote information sharing.
Eventual consistency is a consistency model used in distributed computing to achieve high availability that informally guarantees that, if no new updates are made to a given data item, eventually all accesses to that item will return the last updated value. Eventual consistency, also called optimistic replication, is widely deployed in distributed systems, and has origins in early mobile computing projects. A system that has achieved eventual consistency is often said to have converged, or achieved replica convergence. Eventual consistency is a weak guarantee – most stronger models, like linearizability are trivially eventually consistent, but a system that is merely eventually consistent does not usually fulfill these stronger constraints.
Replication in computing involves sharing information so as to ensure consistency between redundant resources, such as software or hardware components, to improve reliability, fault-tolerance, or accessibility.
A fundamental problem in distributed computing and multi-agent systems is to achieve overall system reliability in the presence of a number of faulty processes. This often requires coordinating processes to reach consensus, or agree on some data value that is needed during computation. Example applications of consensus include agreeing on what transactions to commit to a database in which order, state machine replication, and atomic broadcasts. Real-world applications often requiring consensus include cloud computing, clock synchronization, PageRank, opinion formation, smart power grids, state estimation, control of UAVs, load balancing, blockchain, and others.
Paxos is a family of protocols for solving consensus in a network of unreliable or fallible processors. Consensus is the process of agreeing on one result among a group of participants. This problem becomes difficult when the participants or their communications may experience failures.
Operational transformation (OT) is a technology for supporting a range of collaboration functionalities in advanced collaborative software systems. OT was originally invented for consistency maintenance and concurrency control in collaborative editing of plain text documents. Its capabilities have been extended and its applications expanded to include group undo, locking, conflict resolution, operation notification and compression, group-awareness, HTML/XML and tree-structured document editing, collaborative office productivity tools, application-sharing, and collaborative computer-aided media design tools. In 2009 OT was adopted as a core technique behind the collaboration features in Apache Wave and Google Docs.
A gossip protocol is a procedure or process of computer peer-to-peer communication that is based on the way epidemics spread. Some distributed systems use peer-to-peer gossip to ensure that data is disseminated to all members of a group. Some ad-hoc networks have no central registry and the only way to spread common data is to rely on each member to pass it along to their neighbours.
Routing in delay-tolerant networking concerns itself with the ability to transport, or route, data from a source to a destination, which is a fundamental ability all communication networks must have. Delay- and disruption-tolerant networks (DTNs) are characterized by their lack of connectivity, resulting in a lack of instantaneous end-to-end paths. In these challenging environments, popular ad hoc routing protocols such as AODV and DSR fail to establish routes. This is due to these protocols trying to first establish a complete route and then, after the route has been established, forward the actual data. However, when instantaneous end-to-end paths are difficult or impossible to establish, routing protocols must take to a "store and forward" approach, where data is incrementally moved and stored throughout the network in hopes that it will eventually reach its destination. A common technique used to maximize the probability of a message being successfully transferred is to replicate many copies of the message in hopes that one will succeed in reaching its destination.

Live distributed object refers to a running instance of a distributed multi-party protocol, viewed from the object-oriented perspective, as an entity that has a distinct identity, may encapsulate internal state and threads of execution, and that exhibits a well-defined externally visible behavior.
A version vector is a mechanism for tracking changes to data in a distributed system, where multiple agents might update the data at different times. The version vector allows the participants to determine if one update preceded another (happened-before), followed it, or if the two updates happened concurrently. In this way, version vectors enable causality tracking among data replicas and are a basic mechanism for optimistic replication. In mathematical terms, the version vector generates a preorder that tracks the events that precede, and may therefore influence, later updates.
A distributed operating system is system software over a collection of independent, networked, communicating, and physically separate computational nodes. They handle jobs which are serviced by multiple CPUs. Each individual node holds a specific software subset of the global aggregate operating system. Each subset is a composite of two distinct service provisioners. The first is a ubiquitous minimal kernel, or microkernel, that directly controls that node's hardware. Second is a higher-level collection of system management components that coordinate the node's individual and collaborative activities. These components abstract microkernel functions and support user applications.

A data grid is an architecture or set of services that gives individuals or groups of users the ability to access, modify and transfer extremely large amounts of geographically distributed data for research purposes. Data grids make this possible through a host of middleware applications and services that pull together data and resources from multiple administrative domains and then present it to users upon request. The data in a data grid can be located at a single site or multiple sites where each site can be its own administrative domain governed by a set of security restrictions as to who may access the data. Likewise, multiple replicas of the data may be distributed throughout the grid outside their original administrative domain and the security restrictions placed on the original data for who may access it must be equally applied to the replicas. Specifically developed data grid middleware is what handles the integration between users and the data they request by controlling access while making it available as efficiently as possible. The adjacent diagram depicts a high level view of a data grid.
Quality-of-Data (QoD) is a designation coined by L. Veiga, that specifies and describes the required Quality of Service of a distributed storage system from the Consistency point of view of its data. It can be used to support Big Data management frameworks, Workflow management, and HPC systems. It takes into account data semantics, namely Time interval of data freshness, Sequence of tolerable number of outstanding versions of the data read before refresh, and Value divergence allowed before displaying it. Initially it was based in a model from an existing research work regarding vector-field Consistency, awarded the best-paper prize in the ACM/IFIP/Usenix Middleware Conference 2007 and later enhanced for increased scalability and fault-tolerance.
In distributed computing, a conflict-free replicated data type (CRDT) is a data structure which can be replicated across multiple computers in a network, where the replicas can be updated independently and concurrently without coordination between the replicas, and where it is always mathematically possible to resolve inconsistencies that might come up.
The network and service management taxonomy serves as a classification system for research on the management of computer networks and the services provided by computer networks. The taxonomy has been created and is being maintained by a joint effort of and the Committee of Network Operations and Management (CNOM) of the Communications Society (COMSOC) of the Institute of Electrical and Electronics Engineers (IEEE) and the Working Group 6.6 of the International Federation of Information Processing (IFIP). The taxonomy is organized into seven categories. The first four categories identify what kind of network/service/business aspect is being managed and which functional areas are covered. The remaining three categories identify which management paradigms, technologies, and methods are used.
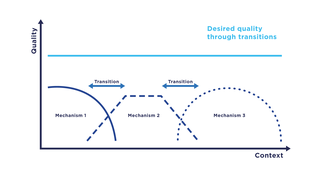
Transition refers to a computer science paradigm in the context of communication systems which describes the change of communication mechanisms, i.e., functions of a communication system, in particular, service and protocol components. In a transition, communication mechanisms within a system are replaced by functionally comparable mechanisms with the aim to ensure the highest possible quality, e.g., as captured by the quality of service.
References
- ↑ Nuno Santos; Luís Veiga; Paulo Ferreira (2007). "Vector-Field Consistency for Adhoc Gaming" (PDF). ACM/IFIP/Usenix Middleware Conference 2007.
- ↑ Luís Veiga; André Negrão; Nuno Santos; Paulo Ferreira (2010). "Unifying Divergence Bounding and Locality Awareness in Replicated Systems with Vector-Field Consistency" (PDF). JISA, Journal of Internet Services and Applications, Volume 1, Number 2, 95-115, Springer, 2010.