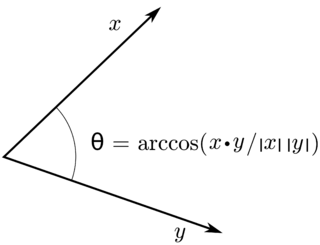
In mathematics, an inner product space is a real vector space or a complex vector space with an operation called an inner product. The inner product of two vectors in the space is a scalar, often denoted with angle brackets such as in . Inner products allow formal definitions of intuitive geometric notions, such as lengths, angles, and orthogonality of vectors. Inner product spaces generalize Euclidean vector spaces, in which the inner product is the dot product or scalar product of Cartesian coordinates. Inner product spaces of infinite dimension are widely used in functional analysis. Inner product spaces over the field of complex numbers are sometimes referred to as unitary spaces. The first usage of the concept of a vector space with an inner product is due to Giuseppe Peano, in 1898.
The Riesz representation theorem, sometimes called the Riesz–Fréchet representation theorem after Frigyes Riesz and Maurice René Fréchet, establishes an important connection between a Hilbert space and its continuous dual space. If the underlying field is the real numbers, the two are isometrically isomorphic; if the underlying field is the complex numbers, the two are isometrically anti-isomorphic. The (anti-) isomorphism is a particular natural isomorphism.
In statistics, naive Bayes classifiers are a family of linear "probabilistic classifiers" which assumes that the features are conditionally independent, given the target class. The strength (naivety) of this assumption is what gives the classifier its name. These classifiers are among the simplest Bayesian network models.
In database theory, relational algebra is a theory that uses algebraic structures for modeling data, and defining queries on it with a well founded semantics. The theory was introduced by Edgar F. Codd.

In corpus linguistics, a collocation is a series of words or terms that co-occur more often than would be expected by chance. In phraseology, a collocation is a type of compositional phraseme, meaning that it can be understood from the words that make it up. This contrasts with an idiom, where the meaning of the whole cannot be inferred from its parts, and may be completely unrelated.
In physics and probability theory, Mean-field theory (MFT) or Self-consistent field theory studies the behavior of high-dimensional random (stochastic) models by studying a simpler model that approximates the original by averaging over degrees of freedom. Such models consider many individual components that interact with each other.
In linear algebra, the Gram matrix of a set of vectors in an inner product space is the Hermitian matrix of inner products, whose entries are given by the inner product . If the vectors are the columns of matrix then the Gram matrix is in the general case that the vector coordinates are complex numbers, which simplifies to for the case that the vector coordinates are real numbers.
A language model is a probabilistic model of a natural language. In 1980, the first significant statistical language model was proposed, and during the decade IBM performed ‘Shannon-style’ experiments, in which potential sources for language modeling improvement were identified by observing and analyzing the performance of human subjects in predicting or correcting text.
Semidefinite programming (SDP) is a subfield of mathematical programming concerned with the optimization of a linear objective function over the intersection of the cone of positive semidefinite matrices with an affine space, i.e., a spectrahedron.
Katz back-off is a generative n-gram language model that estimates the conditional probability of a word given its history in the n-gram. It accomplishes this estimation by backing off through progressively shorter history models under certain conditions. By doing so, the model with the most reliable information about a given history is used to provide the better results.
Sliding window based part-of-speech tagging is used to part-of-speech tag a text.
In statistics, additive smoothing, also called Laplace smoothing or Lidstone smoothing, is a technique used to smooth count data, eliminating issues caused by certain values having 0 occurrences. Given a set of observation counts from a -dimensional multinomial distribution with trials, a "smoothed" version of the counts gives the estimator:
In computer science, more specifically in automata and formal language theory, nested words are a concept proposed by Alur and Madhusudan as a joint generalization of words, as traditionally used for modelling linearly ordered structures, and of ordered unranked trees, as traditionally used for modelling hierarchical structures. Finite-state acceptors for nested words, so-called nested word automata, then give a more expressive generalization of finite automata on words. The linear encodings of languages accepted by finite nested word automata gives the class of visibly pushdown languages. The latter language class lies properly between the regular languages and the deterministic context-free languages. Since their introduction in 2004, these concepts have triggered much research in that area.
Range concatenation grammar (RCG) is a grammar formalism developed by Pierre Boullier in 1998 as an attempt to characterize a number of phenomena of natural language, such as Chinese numbers and German word order scrambling, which are outside the bounds of the mildly context-sensitive languages.
The query likelihood model is a language model used in information retrieval. A language model is constructed for each document in the collection. It is then possible to rank each document by the probability of specific documents given a query. This is interpreted as being the likelihood of a document being relevant given a query.
In statistical mechanics, the mean squared displacement is a measure of the deviation of the position of a particle with respect to a reference position over time. It is the most common measure of the spatial extent of random motion, and can be thought of as measuring the portion of the system "explored" by the random walker. In the realm of biophysics and environmental engineering, the Mean Squared Displacement is measured over time to determine if a particle is spreading slowly due to diffusion, or if an advective force is also contributing. Another relevant concept, the variance-related diameter, is also used in studying the transportation and mixing phenomena in the realm of environmental engineering. It prominently appears in the Debye–Waller factor and in the Langevin equation.
Brown clustering is a hard hierarchical agglomerative clustering problem based on distributional information proposed by Peter Brown, William A. Brown, Vincent Della Pietra, Peter V. de Souza, Jennifer Lai, and Robert Mercer. The method, which is based on bigram language models, is typically applied to text, grouping words into clusters that are assumed to be semantically related by virtue of their having been embedded in similar contexts.
Word2vec is a technique in natural language processing (NLP) for obtaining vector representations of words. These vectors capture information about the meaning of the word and their usage in context. The word2vec algorithm estimates these representations by modeling text in a large corpus. Once trained, such a model can detect synonymous words or suggest additional words for a partial sentence. As the name implies, word2vec represents each distinct word with a particular list of numbers called a vector. The vectors are chosen carefully such that they capture the semantic and syntactic qualities of words; as such, a simple mathematical function can indicate the level of semantic similarity between the words represented by those vectors.
Pure inductive logic (PIL) is the area of mathematical logic concerned with the philosophical and mathematical foundations of probabilistic inductive reasoning. It combines classical predicate logic and probability theory. Probability values are assigned to sentences of a first-order relational language to represent degrees of belief that should be held by a rational agent. Conditional probability values represent degrees of belief based on the assumption of some received evidence.

A transformer is a deep learning architecture based on the multi-head attention mechanism, proposed in a 2017 paper "Attention Is All You Need". It has no recurrent units, and thus requires less training time than previous recurrent neural architectures, such as long short-term memory (LSTM), and its later variation has been prevalently adopted for training large language models on large (language) datasets, such as the Wikipedia corpus and Common Crawl. Input text is split into n-grams encoded as tokens and each token is converted into a vector via looking up from a word embedding table. At each layer, each token is then contextualized within the scope of the context window with other (unmasked) tokens via a parallel multi-head attention mechanism allowing the signal for key tokens to be amplified and less important tokens to be diminished. The transformer paper, published in 2017, is based on the softmax-based attention mechanism was proposed by Bahdanau et. al. in 2014 for machine translation, and the Fast Weight Controller, similar to a transformer, was proposed in 1992.













