Related Research Articles
Knowledge representation and reasoning is the field of artificial intelligence (AI) dedicated to representing information about the world in a form that a computer system can use to solve complex tasks such as diagnosing a medical condition or having a dialog in a natural language. Knowledge representation incorporates findings from psychology about how humans solve problems and represent knowledge, in order to design formalisms that will make complex systems easier to design and build. Knowledge representation and reasoning also incorporates findings from logic to automate various kinds of reasoning.

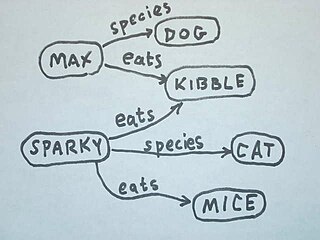
A semantic network, or frame network is a knowledge base that represents semantic relations between concepts in a network. This is often used as a form of knowledge representation. It is a directed or undirected graph consisting of vertices, which represent concepts, and edges, which represent semantic relations between concepts, mapping or connecting semantic fields. A semantic network may be instantiated as, for example, a graph database or a concept map. Typical standardized semantic networks are expressed as semantic triples.

The Semantic Web, sometimes known as Web 3.0, is an extension of the World Wide Web through standards set by the World Wide Web Consortium (W3C). The goal of the Semantic Web is to make Internet data machine-readable.
Data mining is the process of extracting and discovering patterns in large data sets involving methods at the intersection of machine learning, statistics, and database systems. Data mining is an interdisciplinary subfield of computer science and statistics with an overall goal of extracting information from a data set and transforming the information into a comprehensible structure for further use. Data mining is the analysis step of the "knowledge discovery in databases" process, or KDD. Aside from the raw analysis step, it also involves database and data management aspects, data pre-processing, model and inference considerations, interestingness metrics, complexity considerations, post-processing of discovered structures, visualization, and online updating.
In information science, an ontology encompasses a representation, formal naming, and definitions of the categories, properties, and relations between the concepts, data, or entities that pertain to one, many, or all domains of discourse. More simply, an ontology is a way of showing the properties of a subject area and how they are related, by defining a set of terms and relational expressions that represent the entities in that subject area. The field which studies ontologies so conceived is sometimes referred to as applied ontology.
RuleML is a global initiative, led by a non-profit organization RuleML Inc., that is devoted to advancing research and industry standards design activities in the technical area of rules that are semantic and highly inter-operable. The standards design takes the form primarily of a markup language, also known as RuleML. The research activities include an annual research conference, the RuleML Symposium, also known as RuleML for short. Founded in fall 2000 by Harold Boley, Benjamin Grosof, and Said Tabet, RuleML was originally devoted purely to standards design, but then quickly branched out into the related activities of coordinating research and organizing an annual research conference starting in 2002. The M in RuleML is sometimes interpreted as standing for Markup and Modeling. The markup language was developed to express both forward (bottom-up) and backward (top-down) rules in XML for deduction, rewriting, and further inferential-transformational tasks. It is defined by the Rule Markup Initiative, an open network of individuals and groups from both industry and academia that was formed to develop a canonical Web language for rules using XML markup and transformations from and to other rule standards/systems.
A semantic wiki is a wiki that has an underlying model of the knowledge described in its pages. Regular, or syntactic, wikis have structured text and untyped hyperlinks. Semantic wikis, on the other hand, provide the ability to capture or identify information about the data within pages, and the relationships between pages, in ways that can be queried or exported like a database through semantic queries.
The ultimate goal of semantic technology is to help machines understand data. To enable the encoding of semantics with the data, well-known technologies are RDF and OWL. These technologies formally represent the meaning involved in information. For example, ontology can describe concepts, relationships between things, and categories of things. These embedded semantics with the data offer significant advantages such as reasoning over data and dealing with heterogeneous data sources.
Oracle Spatial and Graph, formerly Oracle Spatial, is a free option component of the Oracle Database. The spatial features in Oracle Spatial and Graph aid users in managing geographic and location-data in a native type within an Oracle database, potentially supporting a wide range of applications — from automated mapping, facilities management, and geographic information systems (AM/FM/GIS), to wireless location services and location-enabled e-business. The graph features in Oracle Spatial and Graph include Oracle Network Data Model (NDM) graphs used in traditional network applications in major transportation, telcos, utilities and energy organizations and RDF semantic graphs used in social networks and social interactions and in linking disparate data sets to address requirements from the research, health sciences, finance, media and intelligence communities.
LOGML is an XML 1.0–based markup language for web server log reports, that allows automated data mining and report generation. LOGML is based on XGMML for graph description.
Knowledge extraction is the creation of knowledge from structured and unstructured sources. The resulting knowledge needs to be in a machine-readable and machine-interpretable format and must represent knowledge in a manner that facilitates inferencing. Although it is methodically similar to information extraction (NLP) and ETL, the main criterion is that the extraction result goes beyond the creation of structured information or the transformation into a relational schema. It requires either the reuse of existing formal knowledge or the generation of a schema based on the source data.

Sebastian Schaffert is a software engineer and researcher. He was born in Trostberg, Bavaria, Germany on March 18, 1976 and obtained his doctorate in 2004.
In markup languages and the digital humanities, overlap occurs when a document has two or more structures that interact in a non-hierarchical manner. A document with overlapping markup cannot be represented as a tree. This is also known as concurrent markup. Overlap happens, for instance, in poetry, where there may be a metrical structure of feet and lines; a linguistic structure of sentences and quotations; and a physical structure of volumes and pages and editorial annotations.
Semantic queries allow for queries and analytics of associative and contextual nature. Semantic queries enable the retrieval of both explicitly and implicitly derived information based on syntactic, semantic and structural information contained in data. They are designed to deliver precise results or to answer more fuzzy and wide open questions through pattern matching and digital reasoning.
In natural language processing, linguistics, and neighboring fields, Linguistic Linked Open Data (LLOD) describes a method and an interdisciplinary community concerned with creating, sharing, and (re-)using language resources in accordance with Linked Data principles. The Linguistic Linked Open Data Cloud was conceived and is being maintained by the Open Linguistics Working Group (OWLG) of the Open Knowledge Foundation, but has been a point of focal activity for several W3C community groups, research projects, and infrastructure efforts since then.

A personal knowledge base (PKB) is an electronic tool used to express, capture, and later retrieve the personal knowledge of an individual. It differs from a traditional database in that it contains subjective material particular to the owner, that others may not agree with nor care about. Importantly, a PKB consists primarily of knowledge, rather than information; in other words, it is not a collection of documents or other sources an individual has encountered, but rather an expression of the distilled knowledge the owner has extracted from those sources or from elsewhere.

In knowledge representation and reasoning, a knowledge graph is a knowledge base that uses a graph-structured data model or topology to represent and operate on data. Knowledge graphs are often used to store interlinked descriptions of entities – objects, events, situations or abstract concepts – while also encoding the semantics or relationships underlying these entities.
References
- 1 2 The Dark Web: Breakthroughs in Research and Practice: Breakthroughs in Research and Practice. IGI Global. 2017-07-12. ISBN 978-1-5225-3164-7.
- 1 2 Powell, James (2015-07-09). A Librarian's Guide to Graphs, Data and the Semantic Web. Elsevier. ISBN 978-1-78063-434-0.
- ↑ Shakunthala, Rangarajan. Emerging Trends in Computing zncrtc 2010. Allied Publishers. ISBN 978-81-8424-622-3.
- ↑ Kohavi, Ron; Masand, Brij M.; Spiliopoulou, Myra; Srivastava, Jaideep (2003-08-02). WEBKDD 2001 - Mining Web Log Data Across All Customers Touch Points: Third International Workshop, San Francisco, CA, USA, August 26, 2001, Revised Papers. Springer. ISBN 978-3-540-45640-7.