The growth curve model in statistics is a specific multivariate linear model, also known as GMANOVA (Generalized Multivariate Analysis-Of-Variance). [1] It generalizes MANOVA by allowing post-matrices, as seen in the definition.
The growth curve model in statistics is a specific multivariate linear model, also known as GMANOVA (Generalized Multivariate Analysis-Of-Variance). [1] It generalizes MANOVA by allowing post-matrices, as seen in the definition.
Growth curve model: [2] Let X be a p×n random matrix corresponding to the observations, A a p×q within design matrix with q ≤ p, B a q×k parameter matrix, C a k×n between individual design matrix with rank(C) + p ≤ n and let Σ be a positive-definite p×p matrix. Then
defines the growth curve model, where A and C are known, B and Σ are unknown, and E is a random matrix distributed as Np,n(0,Ip,n).
This differs from standard MANOVA by the addition of C, a "postmatrix". [3]
Many writers have considered the growth curve analysis, among them Wishart (1938), [4] Box (1950) [5] and Rao (1958). [6] Potthoff and Roy in 1964; [3] were the first in analyzing longitudinal data applying GMANOVA models.
GMANOVA is frequently used for the analysis of surveys, clinical trials, and agricultural data, [7] as well as more recently in the context of Radar adaptive detection. [8] [9]
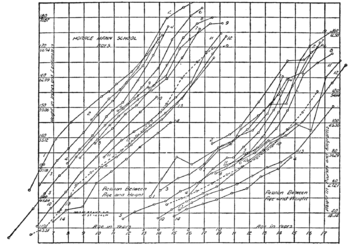
In mathematical statistics, growth curves such as those used in biology are often modeled as being continuous stochastic processes, e.g. as being sample paths that almost surely solve stochastic differential equations. [10] Growth curves have been also applied in forecasting market development. [11] When variables are measured with error, a Latent growth modeling SEM can be used.
Multivariate statistics is a subdivision of statistics encompassing the simultaneous observation and analysis of more than one outcome variable, i.e., multivariate random variables. Multivariate statistics concerns understanding the different aims and background of each of the different forms of multivariate analysis, and how they relate to each other. The practical application of multivariate statistics to a particular problem may involve several types of univariate and multivariate analyses in order to understand the relationships between variables and their relevance to the problem being studied.
Statistics is a field of inquiry that studies the collection, analysis, interpretation, and presentation of data. It is applicable to a wide variety of academic disciplines, from the physical and social sciences to the humanities; it is also used and misused for making informed decisions in all areas of business and government.

In probability theory and statistics, the multivariate normal distribution, multivariate Gaussian distribution, or joint normal distribution is a generalization of the one-dimensional (univariate) normal distribution to higher dimensions. One definition is that a random vector is said to be k-variate normally distributed if every linear combination of its k components has a univariate normal distribution. Its importance derives mainly from the multivariate central limit theorem. The multivariate normal distribution is often used to describe, at least approximately, any set of (possibly) correlated real-valued random variables each of which clusters around a mean value.

In statistics, correlation or dependence is any statistical relationship, whether causal or not, between two random variables or bivariate data. Although in the broadest sense, "correlation" may indicate any type of association, in statistics it usually refers to the degree to which a pair of variables are linearly related. Familiar examples of dependent phenomena include the correlation between the height of parents and their offspring, and the correlation between the price of a good and the quantity the consumers are willing to purchase, as it is depicted in the so-called demand curve.

In mathematics, a time series is a series of data points indexed in time order. Most commonly, a time series is a sequence taken at successive equally spaced points in time. Thus it is a sequence of discrete-time data. Examples of time series are heights of ocean tides, counts of sunspots, and the daily closing value of the Dow Jones Industrial Average.

In statistics, multivariate analysis of variance (MANOVA) is a procedure for comparing multivariate sample means. As a multivariate procedure, it is used when there are two or more dependent variables, and is often followed by significance tests involving individual dependent variables separately.
The general linear model or general multivariate regression model is a compact way of simultaneously writing several multiple linear regression models. In that sense it is not a separate statistical linear model. The various multiple linear regression models may be compactly written as
Ridge regression is a method of estimating the coefficients of multiple-regression models in scenarios where the independent variables are highly correlated. It has been used in many fields including econometrics, chemistry, and engineering. Also known as Tikhonov regularization, named for Andrey Tikhonov, it is a method of regularization of ill-posed problems. It is particularly useful to mitigate the problem of multicollinearity in linear regression, which commonly occurs in models with large numbers of parameters. In general, the method provides improved efficiency in parameter estimation problems in exchange for a tolerable amount of bias.

In statistics, nonlinear regression is a form of regression analysis in which observational data are modeled by a function which is a nonlinear combination of the model parameters and depends on one or more independent variables. The data are fitted by a method of successive approximations.

In the design of experiments, optimal designs are a class of experimental designs that are optimal with respect to some statistical criterion. The creation of this field of statistics has been credited to Danish statistician Kirstine Smith.
Functional data analysis (FDA) is a branch of statistics that analyses data providing information about curves, surfaces or anything else varying over a continuum. In its most general form, under an FDA framework, each sample element of functional data is considered to be a random function. The physical continuum over which these functions are defined is often time, but may also be spatial location, wavelength, probability, etc. Intrinsically, functional data are infinite dimensional. The high intrinsic dimensionality of these data brings challenges for theory as well as computation, where these challenges vary with how the functional data were sampled. However, the high or infinite dimensional structure of the data is a rich source of information and there are many interesting challenges for research and data analysis.

Samarendra Nath Roy was an Indian-born American mathematician and an applied statistician.
Repeated measures design is a research design that involves multiple measures of the same variable taken on the same or matched subjects either under different conditions or over two or more time periods. For instance, repeated measurements are collected in a longitudinal study in which change over time is assessed.

In probability theory and statistics, the generalized chi-squared distribution is the distribution of a quadratic form of a multinormal variable, or a linear combination of different normal variables and squares of normal variables. Equivalently, it is also a linear sum of independent noncentral chi-square variables and a normal variable. There are several other such generalizations for which the same term is sometimes used; some of them are special cases of the family discussed here, for example the gamma distribution.
In probability and statistics, an elliptical distribution is any member of a broad family of probability distributions that generalize the multivariate normal distribution. Intuitively, in the simplified two and three dimensional case, the joint distribution forms an ellipse and an ellipsoid, respectively, in iso-density plots.
The Generalized Additive Model for Location, Scale and Shape (GAMLSS) is an approach to statistical modelling and learning. GAMLSS is a modern distribution-based approach to (semiparametric) regression. A parametric distribution is assumed for the response (target) variable but the parameters of this distribution can vary according to explanatory variables using linear, nonlinear or smooth functions. In machine learning parlance, GAMLSS is a form of supervised machine learning.
David Firth is a British statistician. He is Emeritus Professor in the Department of Statistics at the University of Warwick.
Fang Kaitai, also known as Kai-Tai Fang, is a Chinese mathematician and statistician who has helped to develop generalized multivariate analysis, which extends classical multivariate analysis beyond the multivariate normal distribution to more general elliptical distributions. He has also contributed to the design of experiments.
| Computational statistics | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Correlation and dependence | |||||||||
| Regression analysis | |||||||||
| Regression as a statistical model |
| ||||||||
| Decomposition of variance | |||||||||
| Model exploration | |||||||||
| Background | |||||||||
| Design of experiments | |||||||||
| Numerical approximation | |||||||||
| Applications | |||||||||
