Definitions
Clique Percolation Method (CPM)
The clique percolation method builds up the communities from k-cliques, which correspond to complete (fully connected) sub-graphs of k nodes. (E.g., a k-clique at k = 3 is equivalent to a triangle). Two k-cliques are considered adjacent if they share k − 1 nodes. A community is defined as the maximal union of k-cliques that can be reached from each other through a series of adjacent k-cliques. Such communities can be best interpreted with the help of a k-clique template (an object isomorphic to a complete graph of k nodes). Such a template can be placed onto any k-clique in the graph, and rolled to an adjacent k-clique by relocating one of its nodes and keeping its other k − 1 nodes fixed. Thus, the k-clique communities of a network are all those sub-graphs that can be fully explored by rolling a k-clique template in them, but cannot be left by this template.
This definition allows overlaps between the communities in a natural way, as illustrated in Fig.1, showing four k-clique communities at k = 4. The communities are color-coded and the overlap between them is emphasized in red. The definition above is also local: if a certain sub-graph fulfills the criteria to be considered as a community, then it will remain a community independent of what happens to another part of the network far away. In contrast, when searching for the communities by optimizing with respect to a global quantity, a change far away in the network can reshape the communities in the unperturbed regions as well. Furthermore, it has been shown that global methods can suffer from a resolution limit problem, [3] where the size of the smallest community that can be extracted is dependent on the system size. A local community definition such as here circumvents this problem automatically.
Since even small networks can contain a vast number of k-cliques, the implementation of this approach is based on locating all maximal cliques rather than the individual k-cliques. [1] This inevitably requires finding the graph's maximum clique, which is an NP-hard problem. (We emphasize to the reader that finding a maximum clique is much harder than finding a single maximal clique.) This means that although networks with few million nodes have already been analyzed successfully with this approach, [4] the worst case runtime complexity is exponential in the number of nodes.
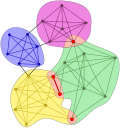 Fig.1. Illustration of the k-clique communities at k = 4.
Fig.1. Illustration of the k-clique communities at k = 4.

Directed Clique Percolation Method (CPMd)
On a network with directed links a directed k-clique is a complete subgraph with k nodes fulfilling the following condition. The k nodes can be ordered such that between an arbitrary pair of them there exists a directed link pointing from the node with the higher rank towards the node with the lower rank. The directed Clique Percolation Method defines directed network communities as the percolation clusters of directed k-cliques.
Weighted Clique Percolation Method (CPMw)
On a network with weighted links a weighted k-clique is a complete subgraph with k nodes such that the geometric mean of the k (k - 1) / 2 link weights within the k-clique is greater than a selected threshold value, I. The weighted Clique Percolation Method defines weighted network communities as the percolation clusters of weighted k-cliques. Note that the geometric mean of link weights within a subgraph is called the intensity of that subgraph. [5]
Clique Graph Generalizations
Clique percolation methods may be generalized by recording different amounts of overlap between the various k-cliques. This then defines a new type of graph, a clique graph, [6] where each k-clique in the original graph is represented by a vertex in the new clique graph. The edges in the clique graph are used to record the strength of the overlap of cliques in the original graph. One may then apply any community detection method to this clique graph to identify the clusters in the original graph through the k-clique structure.
For instance in a simple graph, we can define the overlap between two k-cliques to be the number of vertices common to both k-cliques. The Clique Percolation Method is then equivalent to thresholding this clique graph, dropping all edges of weight less than (k-1), with the remaining connected components forming the communities of cliques found in CPM. For k=2 the cliques are the edges of the original graph and the clique graph in this case is the line graph of the original network.
In practice, using the number of common vertices as a measure of the strength of clique overlap may give poor results as large cliques in the original graph, those with many more than k vertices, will dominate the clique graph. The problem arises because if a vertex is in n different k-cliques it will contribute to n(n-1)/2 edges in such a clique graph. A simple solution is to let each vertex common to two overlapping kcliques to contribute a weight equal to 1/n when measuring the overlap strength of the two k-cliques.
In general the clique graph viewpoint is a useful way of finding generalizations of standard clique-percolation methods to get around any problems encountered. It even shows how to describe extensions of these methods based on other motifs, subgraphs other than k-cliques. In this case a clique graph is best thought of a particular example of a hypergraph.