Description
Definition

There are multiple ways to define cyclomatic complexity of a section of source code. One common way is the number of linearly independent paths within it. A set of paths is linearly independent if the edge set of any path in is not the union of edge sets of the paths in some subset of . If the source code contained no control flow statements (conditionals or decision points) the complexity would be 1, since there would be only a single path through the code. If the code had one single-condition IF statement, there would be two paths through the code: one where the IF statement is TRUE and another one where it is FALSE. Here, the complexity would be 2. Two nested single-condition IFs, or one IF with two conditions, would produce a complexity of 3.



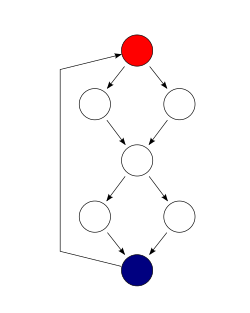
Another way to define the cyclomatic complexity of a program is to look at its control-flow graph, a directed graph containing the basic blocks of the program, with an edge between two basic blocks if control may pass from the first to the second. The complexity M is then defined as [2]

where
- E = the number of edges of the graph.
- N = the number of nodes of the graph.
- P = the number of connected components.

An alternative formulation of this, as originally proposed, is to use a graph in which each exit point is connected back to the entry point. In this case, the graph is strongly connected. Here, the cyclomatic complexity of the program is equal to the cyclomatic number of its graph (also known as the first Betti number), which is defined as [2]

This may be seen as calculating the number of linearly independent cycles that exist in the graph: those cycles that do not contain other cycles within themselves. Because each exit point loops back to the entry point, there is at least one such cycle for each exit point.
For a single program (or subroutine or method), P always equals 1; a simpler formula for a single subroutine is [3]

Cyclomatic complexity may be applied to several such programs or subprograms at the same time (to all of the methods in a class, for example). In these cases, P will equal the number of programs in question, and each subprogram will appear as a disconnected subset of the graph.
McCabe showed that the cyclomatic complexity of a structured program with only one entry point and one exit point is equal to the number of decision points ("if" statements or conditional loops) contained in that program plus one. This is true only for decision points counted at the lowest, machine-level instructions. [4] Decisions involving compound predicates like those found in high-level languages like IF cond1 AND cond2 THEN ... should be counted in terms of predicate variables involved. In this example, one should count two decision points because at machine level it is equivalent to IF cond1 THEN IF cond2 THEN .... [2] [5]
Cyclomatic complexity may be extended to a program with multiple exit points. In this case, it is equal to where is the number of decision points in the program and s is the number of exit points. [5] [6]


Interpretation
In his presentation "Software Quality Metrics to Identify Risk" [7] for the Department of Homeland Security, Tom McCabe introduced the following categorization of cyclomatic complexity:
- 1–10: Simple procedure, little risk
- 11–20: More complex, moderate risk
- 21–50: Complex, high risk
- > 50: Untestable code, very high risk