The intent of this article is to document the important steps in these derivations.
Conjugate direction
The conjugate gradient method can be seen as a special case of the conjugate direction method applied to minimization of the quadratic function
which allows us to apply geometric intuition.
Line search
Geometrically, the quadratic function can be equivalently presented by writing down its value at every point in space. The points of equal value make up its contour surfaces, which are concentric ellipsoids with the equation for varying . As decreases, the ellipsoids become smaller and smaller, until at its minimal value, the ellipsoid shrinks to their shared center.
Minimizing the quadratic function is then a problem of moving around the plane, searching for that shared center of all those ellipsoids. The center can be found by computing explicitly, but this is precisely what we are trying to avoid.
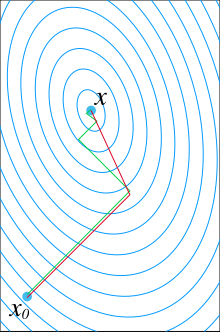
The simplest method is greedy line search, where we start at some point , pick a direction somehow, then minimize . This has a simple closed-form solution that does not involve matrix inversion:Geometrically, we start at some point on some ellipsoid, then choose a direction and travel along that direction, until we hit the point where the ellipsoid is minimized in that direction. This is not necessarily the minimum, but it is progress towards it. Visually, it is moving along a line, and stopping as soon as we reach a point tangent to the contour ellipsoid.
We can now repeat this procedure, starting at our new point , pick a new direction , compute , etc.
We can summarize this as the following algorithm:
Start by picking an initial guess , and compute the initial residual , then iterate:
where are to be picked. Notice in particular how the residual is calculated iteratively step-by-step, instead of anew every time:It is possibly true that prematurely, which would bring numerical problems. However, for particular choices of , this will not occur before convergence, as we will prove below.
Conjugate directions
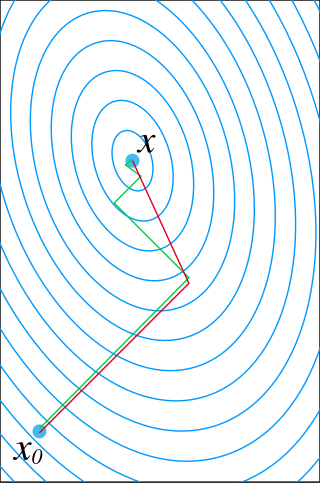
If the directions are not picked well, then progress will be slow. In particular, the gradient descent method would be slow. This can be seen in the diagram, where the green line is the result of always picking the local gradient direction. It zig-zags towards the minimum, but repeatedly overshoots. In contrast, if we pick the directions to be a set of mutually conjugate directions, then there will be no overshoot, and we would obtain the global minimum after steps, where is the number of dimensions.
Two conjugate diameters of an ellipse. Each edge of the bounding parallelogram is parallel to one of the diameters.
The concept of conjugate directions came from classical geometry of ellipse. For an ellipse, two semi-axes center are mutually conjugate with respect to the ellipse iff the lines are parallel to the tangent bounding parallelogram, as pictured. The concept generalizes to n-dimensional ellipsoids, where n semi-axes are mutually conjugate with respect to the ellipsoid iff each axis is parallel to the tangent bounding parallelepiped. In other words, for any , the tangent plane to the ellipsoid at is a hyperplane spanned by the vectors , where is the center of the ellipsoid.
Note that we need to scale each directional vector by a scalar , so that falls exactly on the ellipsoid.
Given an ellipsoid with equation for some constant , we can translate it so that its center is at origin. This changes the equation to for some other constant . The condition of tangency is then:that is, for any .
The conjugate direction method is imprecise in the sense that no formulae are given for selection of the directions . Specific choices lead to various methods including the conjugate gradient method and Gaussian elimination.
Gram–Schmidt process
We can tabulate the equations that we need to set to zero:
0
1
2
3
0
1
2
This resembles the problem of orthogonalization, which requires for any , and for any . Thus the problem of finding conjugate axes is less constrained than the problem of orthogonalization, so the Gram–Schmidt process works, with additional degrees of freedom that we can later use to pick the ones that would simplify the computation:
Arbitrarily set .
Arbitrarily set , then modify it to .
Arbitrarily set , then modify it to .
...
Arbitrarily set , then modify it to .
The most natural choice of is the gradient. That is, . Since conjugate directions can be scaled by a nonzero value, we scale it by for notational cleanness, obtaining Thus, we have . Plugging it in, we have the conjugate gradient algorithm:Proposition. If at some point, , then the algorithm has converged, that is, .
Proof. By construction, it would mean that , that is, taking a conjugate gradient step gets us exactly back to where we were. This is only possible if the local gradient is already zero.
Simplification
This algorithm can be significantly simplified by some lemmas, resulting in the conjugate gradient algorithm.
Lemma 1. and .
Proof. By the geometric construction, the tangent plane to the ellipsoid at contains each of the previous conjugate direction vectors . Further, is perpendicular to the tangent, thus . The second equation is true since by construction, is a linear transform of .
Lemma 2..
Proof. By construction, , now apply lemma 1.
Lemma 3..
Proof. By construction, we have , thusNow apply lemma 1.
Plugging lemmas 1-3 in, we have and , which is the proper conjugate gradient algorithm.
Put in matrix form, the iteration is captured by the equation
where
with
When applying the Arnoldi iteration to solving linear systems, one starts with , the residual corresponding to an initial guess . After each step of iteration, one computes and the new iterate .
The direct Lanczos method
For the rest of discussion, we assume that is symmetric positive-definite. With symmetry of , the upper Hessenberg matrix becomes symmetric and thus tridiagonal. It then can be more clearly denoted by
This enables a short three-term recurrence for in the iteration, and the Arnoldi iteration is reduced to the Lanczos iteration.
In fact, there are short recurrences for and as well:
With this formulation, we arrive at a simple recurrence for :
The relations above straightforwardly lead to the direct Lanczos method, which turns out to be slightly more complex.
The conjugate gradient method from imposing orthogonality and conjugacy
If we allow to scale and compensate for the scaling in the constant factor, we potentially can have simpler recurrences of the form:
As premises for the simplification, we now derive the orthogonality of and conjugacy of , i.e., for ,
The residuals are mutually orthogonal because is essentially a multiple of since for , , for ,
To see the conjugacy of , it suffices to show that is diagonal:
is symmetric and lower triangular simultaneously and thus must be diagonal.
Now we can derive the constant factors and with respect to the scaled by solely imposing the orthogonality of and conjugacy of .
Due to the orthogonality of , it is necessary that . As a result,
Similarly, due to the conjugacy of , it is necessary that . As a result,
This completes the derivation.
Related Research Articles
In probability theory and statistics, the multivariate normal distribution, multivariate Gaussian distribution, or joint normal distribution is a generalization of the one-dimensional (univariate) normal distribution to higher dimensions. One definition is that a random vector is said to be k-variate normally distributed if every linear combination of its k components has a univariate normal distribution. Its importance derives mainly from the multivariate central limit theorem. The multivariate normal distribution is often used to describe, at least approximately, any set of (possibly) correlated real-valued random variables, each of which clusters around a mean value.
The moment of inertia, otherwise known as the mass moment of inertia, angular/rotational mass, second moment of mass, or most accurately, rotational inertia, of a rigid body is a quantity that determines the torque needed for a desired angular acceleration about a rotational axis, akin to how mass determines the force needed for a desired acceleration. It depends on the body's mass distribution and the axis chosen, with larger moments requiring more torque to change the body's rate of rotation by a given amount.
In mechanics and geometry, the 3D rotation group, often denoted SO(3), is the group of all rotations about the origin of three-dimensional Euclidean space under the operation of composition.
In continuum mechanics, the infinitesimal strain theory is a mathematical approach to the description of the deformation of a solid body in which the displacements of the material particles are assumed to be much smaller than any relevant dimension of the body; so that its geometry and the constitutive properties of the material at each point of space can be assumed to be unchanged by the deformation.
In the mathematical field of differential geometry, a metric tensor is an additional structure on a manifold M that allows defining distances and angles, just as the inner product on a Euclidean space allows defining distances and angles there. More precisely, a metric tensor at a point p of M is a bilinear form defined on the tangent space at p, and a metric field on M consists of a metric tensor at each point p of M that varies smoothly with p.
In physics, Hamiltonian mechanics is a reformulation of Lagrangian mechanics that emerged in 1833. Introduced by Sir William Rowan Hamilton, Hamiltonian mechanics replaces (generalized) velocities used in Lagrangian mechanics with (generalized) momenta. Both theories provide interpretations of classical mechanics and describe the same physical phenomena.
In linear algebra, a square matrix is called diagonalizable or non-defective if it is similar to a diagonal matrix. That is, if there exists an invertible matrix and a diagonal matrix such that . This is equivalent to . This property exists for any linear map: for a finite-dimensional vector space , a linear map is called diagonalizable if there exists an ordered basis of consisting of eigenvectors of . These definitions are equivalent: if has a matrix representation as above, then the column vectors of form a basis consisting of eigenvectors of , and the diagonal entries of are the corresponding eigenvalues of ; with respect to this eigenvector basis, is represented by .
In the calculus of variations, a field of mathematical analysis, the functional derivative relates a change in a functional to a change in a function on which the functional depends.
In mathematics, the conjugate gradient method is an algorithm for the numerical solution of particular systems of linear equations, namely those whose matrix is positive-semidefinite. The conjugate gradient method is often implemented as an iterative algorithm, applicable to sparse systems that are too large to be handled by a direct implementation or other direct methods such as the Cholesky decomposition. Large sparse systems often arise when numerically solving partial differential equations or optimization problems.
In statistics, the theory of minimum norm quadratic unbiased estimation (MINQUE) was developed by C. R. Rao. MINQUE is a theory alongside other estimation methods in estimation theory, such as the method of moments or maximum likelihood estimation. Similar to the theory of best linear unbiased estimation, MINQUE is specifically concerned with linear regression models. The method was originally conceived to estimate heteroscedastic error variance in multiple linear regression. MINQUE estimators also provide an alternative to maximum likelihood estimators or restricted maximum likelihood estimators for variance components in mixed effects models. MINQUE estimators are quadratic forms of the response variable and are used to estimate a linear function of the variances.
In differential geometry, the four-gradient is the four-vector analogue of the gradient from vector calculus.
In continuum mechanics, the finite strain theory—also called large strain theory, or large deformation theory—deals with deformations in which strains and/or rotations are large enough to invalidate assumptions inherent in infinitesimal strain theory. In this case, the undeformed and deformed configurations of the continuum are significantly different, requiring a clear distinction between them. This is commonly the case with elastomers, plastically deforming materials and other fluids and biological soft tissue.
In geometry, various formalisms exist to express a rotation in three dimensions as a mathematical transformation. In physics, this concept is applied to classical mechanics where rotational kinematics is the science of quantitative description of a purely rotational motion. The orientation of an object at a given instant is described with the same tools, as it is defined as an imaginary rotation from a reference placement in space, rather than an actually observed rotation from a previous placement in space.
In physics and continuum mechanics, deformation is the change in the shape or size of an object. It has dimension of length with SI unit of metre (m). It is quantified as the residual displacement of particles in a non-rigid body, from an initial configuration to a final configuration, excluding the body's average translation and rotation. A configuration is a set containing the positions of all particles of the body.
Stokes' theorem, also known as the Kelvin–Stokes theorem after Lord Kelvin and George Stokes, the fundamental theorem for curls or simply the curl theorem, is a theorem in vector calculus on . Given a vector field, the theorem relates the integral of the curl of the vector field over some surface, to the line integral of the vector field around the boundary of the surface. The classical theorem of Stokes can be stated in one sentence: The line integral of a vector field over a loop is equal to the surface integral of its curl over the enclosed surface. It is illustrated in the figure, where the direction of positive circulation of the bounding contour ∂Σ, and the direction n of positive flux through the surface Σ, are related by a right-hand-rule. For the right hand the fingers circulate along ∂Σ and the thumb is directed along n.
The Kirchhoff–Love theory of plates is a two-dimensional mathematical model that is used to determine the stresses and deformations in thin plates subjected to forces and moments. This theory is an extension of Euler-Bernoulli beam theory and was developed in 1888 by Love using assumptions proposed by Kirchhoff. The theory assumes that a mid-surface plane can be used to represent a three-dimensional plate in two-dimensional form.
The conjugate residual method is an iterative numeric method used for solving systems of linear equations. It's a Krylov subspace method very similar to the much more popular conjugate gradient method, with similar construction and convergence properties.
A phonovoltaic (pV) cell converts vibrational (phonons) energy into a direct current much like the photovoltaic effect in a photovoltaic (PV) cell converts light (photon) into power. That is, it uses a p-n junction to separate the electrons and holes generated as valence electrons absorb optical phonons more energetic than the band gap, and then collects them in the metallic contacts for use in a circuit. The pV cell is an application of heat transfer physics and competes with other thermal energy harvesting devices like the thermoelectric generator.
The streamline upwind Petrov–Galerkin pressure-stabilizing Petrov–Galerkin formulation for incompressible Navier–Stokes equations can be used for finite element computations of high Reynolds number incompressible flow using equal order of finite element space by introducing additional stabilization terms in the Navier–Stokes Galerkin formulation.
In probability theory and statistics, the Dirichlet negative multinomial distribution is a multivariate distribution on the non-negative integers. It is a multivariate extension of the beta negative binomial distribution. It is also a generalization of the negative multinomial distribution (NM(k, p)) allowing for heterogeneity or overdispersion to the probability vector. It is used in quantitative marketing research to flexibly model the number of household transactions across multiple brands.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.