Bra–ket notation, also called Dirac notation, is a notation for linear algebra and linear operators on complex vector spaces together with their dual space both in the finite-dimensional and infinite-dimensional case. It is specifically designed to ease the types of calculations that frequently come up in quantum mechanics. Its use in quantum mechanics is quite widespread.
The Riesz representation theorem, sometimes called the Riesz–Fréchet representation theorem after Frigyes Riesz and Maurice René Fréchet, establishes an important connection between a Hilbert space and its continuous dual space. If the underlying field is the real numbers, the two are isometrically isomorphic; if the underlying field is the complex numbers, the two are isometrically anti-isomorphic. The (anti-) isomorphism is a particular natural isomorphism.
In mathematics, weak topology is an alternative term for certain initial topologies, often on topological vector spaces or spaces of linear operators, for instance on a Hilbert space. The term is most commonly used for the initial topology of a topological vector space with respect to its continuous dual. The remainder of this article will deal with this case, which is one of the concepts of functional analysis.
Distributions, also known as Schwartz distributions or generalized functions, are objects that generalize the classical notion of functions in mathematical analysis. Distributions make it possible to differentiate functions whose derivatives do not exist in the classical sense. In particular, any locally integrable function has a distributional derivative.
In mathematics, particularly linear algebra, an orthonormal basis for an inner product space with finite dimension is a basis for whose vectors are orthonormal, that is, they are all unit vectors and orthogonal to each other. For example, the standard basis for a Euclidean space is an orthonormal basis, where the relevant inner product is the dot product of vectors. The image of the standard basis under a rotation or reflection is also orthonormal, and every orthonormal basis for arises in this fashion.
The Fock space is an algebraic construction used in quantum mechanics to construct the quantum states space of a variable or unknown number of identical particles from a single particle Hilbert space H. It is named after V. A. Fock who first introduced it in his 1932 paper "Konfigurationsraum und zweite Quantelung".
In physics, an operator is a function over a space of physical states onto another space of physical states. The simplest example of the utility of operators is the study of symmetry. Because of this, they are useful tools in classical mechanics. Operators are even more important in quantum mechanics, where they form an intrinsic part of the formulation of the theory.
In mathematics, the Hodge star operator or Hodge star is a linear map defined on the exterior algebra of a finite-dimensional oriented vector space endowed with a nondegenerate symmetric bilinear form. Applying the operator to an element of the algebra produces the Hodge dual of the element. This map was introduced by W. V. D. Hodge.
In mathematics, a positive-definite function is, depending on the context, either of two types of function.
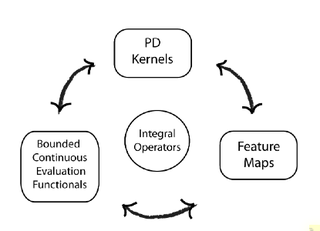
In functional analysis, a reproducing kernel Hilbert space (RKHS) is a Hilbert space of functions in which point evaluation is a continuous linear functional. Roughly speaking, this means that if two functions and in the RKHS are close in norm, i.e., is small, then and are also pointwise close, i.e., is small for all . The converse does not need to be true. Informally, this can be shown by looking at the supremum norm: the sequence of functions converges pointwise, but does not converge uniformly i.e. does not converge with respect to the supremum norm.
In functional analysis, a branch of mathematics, it is sometimes possible to generalize the notion of the determinant of a square matrix of finite order (representing a linear transformation from a finite-dimensional vector space to itself) to the infinite-dimensional case of a linear operator S mapping a function space V to itself. The corresponding quantity det(S) is called the functional determinant of S.

Wigner's theorem, proved by Eugene Wigner in 1931, is a cornerstone of the mathematical formulation of quantum mechanics. The theorem specifies how physical symmetries such as rotations, translations, and CPT transformations are represented on the Hilbert space of states.
In mathematics, a holomorphic vector bundle is a complex vector bundle over a complex manifold X such that the total space E is a complex manifold and the projection map π : E → X is holomorphic. Fundamental examples are the holomorphic tangent bundle of a complex manifold, and its dual, the holomorphic cotangent bundle. A holomorphic line bundle is a rank one holomorphic vector bundle.
In cryptography, learning with errors (LWE) is a mathematical problem that is widely used to create secure encryption algorithms. It is based on the idea of representing secret information as a set of equations with errors. In other words, LWE is a way to hide the value of a secret by introducing noise to it. In more technical terms, it refers to the computational problem of inferring a linear -ary function over a finite ring from given samples some of which may be erroneous. The LWE problem is conjectured to be hard to solve, and thus to be useful in cryptography.

In probability theory and directional statistics, a wrapped Cauchy distribution is a wrapped probability distribution that results from the "wrapping" of the Cauchy distribution around the unit circle. The Cauchy distribution is sometimes known as a Lorentzian distribution, and the wrapped Cauchy distribution may sometimes be referred to as a wrapped Lorentzian distribution.
In mathematics, the Witten zeta function, is a function associated to a root system that encodes the degrees of the irreducible representations of the corresponding Lie group. These zeta functions were introduced by Don Zagier who named them after Edward Witten's study of their special values. Note that in, Witten zeta functions do not appear as explicit objects in their own right.
Least-squares support-vector machines (LS-SVM) for statistics and in statistical modeling, are least-squares versions of support-vector machines (SVM), which are a set of related supervised learning methods that analyze data and recognize patterns, and which are used for classification and regression analysis. In this version one finds the solution by solving a set of linear equations instead of a convex quadratic programming (QP) problem for classical SVMs. Least-squares SVM classifiers were proposed by Johan Suykens and Joos Vandewalle. LS-SVMs are a class of kernel-based learning methods.
Coherent states have been introduced in a physical context, first as quasi-classical states in quantum mechanics, then as the backbone of quantum optics and they are described in that spirit in the article Coherent states. However, they have generated a huge variety of generalizations, which have led to a tremendous amount of literature in mathematical physics. In this article, we sketch the main directions of research on this line. For further details, we refer to several existing surveys.
In algebra and number theory, a distribution is a function on a system of finite sets into an abelian group which is analogous to an integral: it is thus the algebraic analogue of a distribution in the sense of generalised function.
Regularized least squares (RLS) is a family of methods for solving the least-squares problem while using regularization to further constrain the resulting solution.





























































