Fig.1. Google matrix of Wikipedia articles network, written in the bases of PageRank index; fragment of top 200 X 200 matrix elements is shown, total size N=3282257 (from )
A Google matrix is a particular stochastic matrix that is used by Google's PageRank algorithm. The matrix represents a graph with edges representing links between pages. The PageRank of each page can then be generated iteratively from the Google matrix using the power method. However, in order for the power method to converge, the matrix must be stochastic, irreducible and aperiodic.
In order to generate the Google matrix G, we must first generate an adjacency matrixA which represents the relations between pages or nodes.
Assuming there are N pages, we can fill out A by doing the following:
A matrix element is filled with 1 if node has a link to node , and 0 otherwise; this is the adjacency matrix of links.
A related matrix S corresponding to the transitions in a Markov chain of given network is constructed from A by dividing the elements of column "j" by a number of where is the total number of outgoing links from nodej to all other nodes. The columns having zero matrix elements, corresponding to dangling nodes, are replaced by a constant value 1/N. Such a procedure adds a link from every sink, dangling state to every other node.
Now by the construction the sum of all elements in any column of matrix S is equal to unity. In this way the matrix S is mathematically well defined and it belongs to the class of Markov chains and the class of Perron-Frobenius operators. That makes S suitable for the PageRank algorithm.
Construction of Google matrix G
Fig.2. Google matrix of Cambridge University network (2006), coarse-grained matrix elements are written in the bases of PageRank index, total size N=212710 is shown (from )
Then the final Google matrix G can be expressed via S as:
By the construction the sum of all non-negative elements inside each matrix column is equal to unity. The numerical coefficient is known as a damping factor.
Usually S is a sparse matrix and for modern directed networks it has only about ten nonzero elements in a line or column, thus only about 10N multiplications are needed to multiply a vector by matrixG.[2][3]
Examples of Google matrix
An example of the matrix construction via Eq.(1) within a simple network is given in the article CheiRank.
For the actual matrix, Google uses a damping factor around 0.85.[2][3][4] The term gives a surfer probability to jump randomly on any page. The matrix belongs to the class of Perron-Frobenius operators of Markov chains.[2] The examples of Google matrix structure are shown in Fig.1 for Wikipedia articles hyperlink network in 2009 at small scale and in Fig.2 for University of Cambridge network in 2006 at large scale.
Spectrum and eigenstates of G matrix
Fig3. The spectrum of eigenvalues of the Google matrix of University of Cambridge from Fig.2 at , blue points show eigenvalues of isolated subspaces, red points show eigenvalues of core component (from )
For there is only one maximal eigenvalue with the corresponding right eigenvector which has non-negative elements which can be viewed as stationary probability distribution.[2] These probabilities ordered by their decreasing values give the PageRank vector with the PageRank used by Google search to rank webpages. Usually one has for the World Wide Web that with . The number of nodes with a given PageRank value scales as with the exponent .[6][7] The left eigenvector at has constant matrix elements. With all eigenvalues move as except the maximal eigenvalue , which remains unchanged.[2] The PageRank vector varies with but other eigenvectors with remain unchanged due to their orthogonality to the constant left vector at . The gap between and other eigenvalue being gives a rapid convergence of a random initial vector to the PageRank approximately after 50 multiplications on matrix.
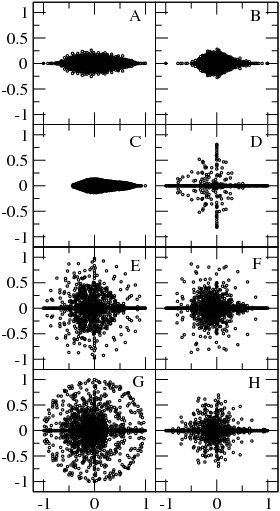
Fig4. Distribution of eigenvalues of Google matrices in the complex plane at for dictionary networks: Roget (A, N=1022), ODLIS (B, N=2909) and FOLDOC (C, N=13356); UK university WWW networks: University of Wales (Cardiff) (D, N=2778), Birmingham City University (E, N=10631), Keele University (Staffordshire) (F, N=11437), Nottingham Trent University (G, N=12660), Liverpool John Moores University (H, N=13578)(data for universities are for 2002) (from )
At the matrix has generally many degenerate eigenvalues (see e.g. [6][8]). Examples of the eigenvalue spectrum of the Google matrix of various directed networks is shown in Fig.3 from [5] and Fig.4 from.[8]
The Google matrix can be also constructed for the Ulam networks generated by the Ulam method [8] for dynamical maps. The spectral properties of such matrices are discussed in [9,10,11,12,13,15].[5][9] In a number of cases the spectrum is described by the fractal Weyl law [10,12].
Fig5. Distribution of eigenvalues in the complex plane for the Google matrix of the Linux Kernel version 2.6.32 with matrix size at , unit circle is shown by solid curve (from ) Fig.6 Coarse-grained probability distribution for the eigenstates of the Google matrix for Linux Kernel version 2.6.32. The horizontal lines show the first 64 eigenvectors ordered vertically by (from )
The Google matrix can be constructed also for other directed networks, e.g. for the procedure call network of the Linux Kernel software introduced in [15]. In this case the spectrum of is described by the fractal Weyl law with the fractal dimension (see Fig.5 from [9]). Numerical analysis shows that the eigenstates of matrix are localized (see Fig.6 from [9]). Arnoldi iteration method allows to compute many eigenvalues and eigenvectors for matrices of rather large size [13].[5][9]
Other examples of matrix include the Google matrix of brain [17] and business process management [18], see also.[1] Applications of Google matrix analysis to DNA sequences is described in [20]. Such a Google matrix approach allows also to analyze entanglement of cultures via ranking of multilingual Wikipedia articles abouts persons [21]
Historical notes
The Google matrix with damping factor was described by Sergey Brin and Larry Page in 1998 [22], see also articles on PageRank history [23],[24].
Serra-Capizzano, Stefano (2005). "Jordan Canonical Form of the Google Matrix: a Potential Contribution to the PageRank Computation". SIAM J. Matrix Anal. Appl. 27 (2): 305. doi:10.1137/s0895479804441407. hdl:11383/1494937.
Ulam, Stanislaw (1960). A Collection of Mathematical Problems. Interscience Tracts in Pure and Applied Mathematics. New York: Interscience. p.73.
Froyland G.; Padberg K. (2009). "Almost-invariant sets and invariant manifolds—Connecting probabilistic and geometric descriptions of coherent structures in flows". Physica D. 238 (16): 1507. Bibcode:2009PhyD..238.1507F. doi:10.1016/j.physd.2009.03.002.
Brin S.; Page L. (1998). "The anatomy of a large-scale hypertextual Web search engine". Computer Networks and ISDN Systems. 30 (1–7): 107. doi:10.1016/s0169-7552(98)00110-x. S2CID7587743.
Massimo, Franceschet (2010). "PageRank: Standing on the shoulders of giants". arXiv:1002.2858 [cs.IR].
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.