In database design, object-oriented programming and design, has-a (has_a or has a) is a composition relationship where one object (often called the constituted object, or part/constituent/member object) "belongs to" (is part or member of) another object (called the composite type), and behaves according to the rules of ownership. In simple words, has-a relationship in an object is called a member field of an object. Multiple has-a relationships will combine to form a possessive hierarchy.
"Has-a" is to be contrasted with an is-a (is_a or is a) relationship which constitutes a taxonomic hierarchy (subtyping).
The decision whether the most logical relationship for an object and its subordinate is not always clearly has-a or is-a. Confusion over such decisions have necessitated the creation of these metalinguistic terms. A good example of the has-a relationship is containers in the C++STL.
To summarize the relations, we have
hypernym-hyponym (supertype-subtype) relations between types (classes) defining a taxonomic hierarchy, where
for an inheritance relation: a hyponym (subtype, subclass) has a type-of (is-a) relationship with its hypernym (supertype, superclass);
holonym-meronym (whole/entity/container-part/constituent/member) relations between types (classes) defining a possessive hierarchy, where
for an aggregation (i.e. without ownership) relation:
a holonym (whole) has a has-a relationship with its meronym (part),
In databases has-a relationships are usually represented in an Entity–relationship model. As you can see by the diagram on the right an account can have multiple characters. This shows that account has a "has-a" relationship with character.
UML class diagram
UML class diagram Misuses of composition and aggregation
In object-oriented programming this relationship can be represented with a Unified Modeling Language Class diagram. This has-a relationship is also known as composition. As you can see from the Class Diagram on the right a car "has-a" carburetor, or a car is "composed of" a carburetor. When the diamond is coloured black it signifies composition, i.e. the object on the side closest to the diamond is made up of or contains the other object. While the white diamond signifies aggregation, which means that the object closest to the diamond can have or possess the other object.
C++
Another way to distinguish between composition and aggregation in modeling the real world, is to consider the relative lifetime of the contained object. For example, if a Car object contains a Chassis object, a Chassis will most likely not be replaced during the lifetime of the Car. It will have the same lifetime as the car itself; so the relationship is one of composition. On the other hand, if the Car object contains a set of Tire objects, these Tire objects may wear out and get replaced several times. Or if the Car becomes unusable, some Tires may be salvaged and assigned to another Car. At any rate, the Tire objects have different lifetimes than the Car object; therefore the relationship is one of aggregation.
If one were to make a C++ software Class to implement the relationships described above, the Car object would contain a complete Chassis object in a data member. This Chassis object would be instantiated in the constructor of the Car class (or defined as the data type of the data member and its properties assigned in the constructor.) And since it would be a wholly contained data member of the Car class, the Chassis object would no longer exist if a Car class object was to be deleted.
On the other hand, the Car class data members that point to Tire objects would most likely be C++ pointers. Tire objects could be instantiated and deleted externally, or even assigned to data members of a different Car object. Tire objects would have an independent lifetime separate from when the Car object was deleted.
In object-oriented programming, a class defines the shared aspects of objects created from the class. The capabilities of a class differ between programming languages, but generally the shared aspects consist of state (variables) and behavior (methods) that are each either associated with an particular object or with all objects of that class.
A generalization is a form of abstraction whereby common properties of specific instances are formulated as general concepts or claims. Generalizations posit the existence of a domain or set of elements, as well as one or more common characteristics shared by those elements. As such, they are the essential basis of all valid deductive inferences, where the process of verification is necessary to determine whether a generalization holds true for any given situation.
WordNet is a lexical database of semantic relations between words that links words into semantic relations including synonyms, hyponyms, and meronyms. The synonyms are grouped into synsets with short definitions and usage examples. It can thus be seen as a combination and extension of a dictionary and thesaurus. While it is accessible to human users via a web browser, its primary use is in automatic text analysis and artificial intelligence applications. It was first created in the English language and the English WordNet database and software tools have been released under a BSD style license and are freely available for download from that WordNet website. There are now WordNets in more than 200 languages.
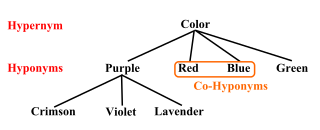
Hypernymy and hyponymy are the semantic relations between a generic term (hypernym) and a specific instance of it (hyponym). The hypernym is also called a supertype, umbrella term, or blanket term. The hyponym is a subtype of the hypernym. The semantic field of the hyponym is included within that of the hypernym. For example, pigeon, crow, and hen are all hyponyms of bird and animal; bird and animal are both hypernyms of pigeon, crow, and hen.
In programming language theory, subtyping is a form of type polymorphism. A subtype is a datatype that is related to another datatype by some notion of substitutability, meaning that program elements, written to operate on elements of the supertype, can also operate on elements of the subtype.
In linguistics, meronymy is a semantic relation between a meronym denoting a part and a holonym denoting a whole. In simpler terms, a meronym is in a part-of relationship with its holonym. For example, finger is a meronym of hand, which is its holonym. Similarly, engine is a meronym of car, which is its holonym. Fellow meronyms are called comeronyms.
In knowledge representation and ontology components, including for object-oriented programming and design, is-a is a subsumptive relationship between abstractions, wherein one class A is a subclass of another class B . In other words, type A is a subtype of type B when A's specification implies B's specification. That is, any object that satisfies A's specification also satisfies B's specification, because B's specification is weaker.
The Liskov substitution principle (LSP) is a particular definition of a subtyping relation, called strong behavioral subtyping, that was initially introduced by Barbara Liskov in a 1987 conference keynote address titled Data abstraction and hierarchy. It is based on the concept of "substitutability" – a principle in object-oriented programming stating that an object may be replaced by a sub-object without breaking the program. It is a semantic rather than merely syntactic relation, because it intends to guarantee semantic interoperability of types in a hierarchy, object types in particular. Barbara Liskov and Jeannette Wing described the principle succinctly in a 1994 paper as follows:
Subtype Requirement: Let be a property provable about objects of type T. Then should be true for objects of type S where S is a subtype of T.
In computer science, object composition and object aggregation are closely related ways to combine objects or data types into more complex ones. In conversation the distinction between composition and aggregation is often ignored. Common kinds of compositions are objects used in object-oriented programming, tagged unions, sets, sequences, and various graph structures. Object compositions relate to, but are not the same as, data structures.
In software engineering, a class diagram in the Unified Modeling Language (UML) is a type of static structure diagram that describes the structure of a system by showing the system's classes, their attributes, operations, and the relationships among objects.
In object-oriented programming, inheritance is the mechanism of basing an object or class upon another object or class, retaining similar implementation. Also defined as deriving new classes from existing ones such as super class or base class and then forming them into a hierarchy of classes. In most class-based object-oriented languages like C++, an object created through inheritance, a "child object", acquires all the properties and behaviors of the "parent object", with the exception of: constructors, destructors, overloaded operators and friend functions of the base class. Inheritance allows programmers to create classes that are built upon existing classes, to specify a new implementation while maintaining the same behaviors, to reuse code and to independently extend original software via public classes and interfaces. The relationships of objects or classes through inheritance give rise to a directed acyclic graph.
In information science and ontology, a classification scheme is an arrangement of classes or groups of classes. The activity of developing the schemes bears similarity to taxonomy, but with perhaps a more theoretical bent, as a single classification scheme can be applied over a wide semantic spectrum while taxonomies tend to be devoted to a single topic.
Glossary of Unified Modeling Language (UML) terms provides a compilation of terminology used in all versions of UML, along with their definitions. Any notable distinctions that may exist between versions are noted with the individual entry it applies to.
Gellish is an ontology language for data storage and communication, designed and developed by Andries van Renssen since mid-1990s. It started out as an engineering modeling language but evolved into a universal and extendable conceptual data modeling language with general applications. Because it includes domain-specific terminology and definitions, it is also a semantic data modelling language and the Gellish modeling methodology is a member of the family of semantic modeling methodologies.
EXPRESS is a standard for generic data modeling language for product data. EXPRESS is formalized in the ISO Standard for the Exchange of Product model STEP, and standardized as ISO 10303-11.
The Gellish English Dictionary-Taxonomy is an example of an open-source “smart” electronic dictionary, in which concepts are arranged in a subtype-supertype hierarchy, thus forming a taxonomy. The dictionary-taxonomy is machine readable. It is compliant with the guidelines of ISO 16354. Apart from the fact that it is an English (business-technical) dictionary, it also defines the semantics of Gellish English, which is a computer-interpretable structured subset of the natural English language for data storage and data exchange. The dictionary-taxonomy differs from conventional dictionaries because of several additional capabilities. Therefore it is called "smart." This means that it satisfies the following criteria:
A meronomy or partonomy is a hierarchical taxonomy that deals with part–whole relationships. For example, a car has parts that include engine, body and wheels; and the body has parts that include doors and windows.
Generic data models are generalizations of conventional data models. They define standardised general relation types, together with the kinds of things that may be related by such a relation type.
Contemporary ontologies share many structural similarities, regardless of the ontology language in which they are expressed. Most ontologies describe individuals (instances), classes (concepts), attributes, and relations.
In knowledge representation, a class is a collection of individuals or individuals objects. A class can be defined either by extension, or by intension, using what is called in some ontology languages like OWL. According to the type–token distinction, the ontology is divided into individuals, who are real worlds objects, or events, and types, or classes, who are sets of real world objects. Class expressions or definitions gives the properties that the individuals must fulfill to be members of the class. Individuals that fulfill the property are called Instances.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.