Related Research Articles
In computer science, an array is a data structure consisting of a collection of elements, of same memory size, each identified by at least one array index or key. An array is stored such that the position of each element can be computed from its index tuple by a mathematical formula. The simplest type of data structure is a linear array, also called a one-dimensional array.

In computer science, heapsort is an efficient, comparison-based sorting algorithm that reorganizes an input array into a heap and then repeatedly removes the largest node from that heap, placing it at the end of the array.

In computer science, a heap is a tree-based data structure that satisfies the heap property: In a max heap, for any given node C, if P is the parent node of C, then the key of P is greater than or equal to the key of C. In a min heap, the key of P is less than or equal to the key of C. The node at the "top" of the heap is called the root node.

Insertion sort is a simple sorting algorithm that builds the final sorted array (or list) one item at a time by comparisons. It is much less efficient on large lists than more advanced algorithms such as quicksort, heapsort, or merge sort. However, insertion sort provides several advantages:
In computer science, a linked list is a linear collection of data elements whose order is not given by their physical placement in memory. Instead, each element points to the next. It is a data structure consisting of a collection of nodes which together represent a sequence. In its most basic form, each node contains data, and a reference to the next node in the sequence. This structure allows for efficient insertion or removal of elements from any position in the sequence during iteration. More complex variants add additional links, allowing more efficient insertion or removal of nodes at arbitrary positions. A drawback of linked lists is that data access time is linear in respect to the number of nodes in the list. Because nodes are serially linked, accessing any node requires that the prior node be accessed beforehand. Faster access, such as random access, is not feasible. Arrays have better cache locality compared to linked lists.
In computer science, radix sort is a non-comparative sorting algorithm. It avoids comparison by creating and distributing elements into buckets according to their radix. For elements with more than one significant digit, this bucketing process is repeated for each digit, while preserving the ordering of the prior step, until all digits have been considered. For this reason, radix sort has also been called bucket sort and digital sort.

In computer science, a sorting algorithm is an algorithm that puts elements of a list into an order. The most frequently used orders are numerical order and lexicographical order, and either ascending or descending. Efficient sorting is important for optimizing the efficiency of other algorithms that require input data to be in sorted lists. Sorting is also often useful for canonicalizing data and for producing human-readable output.
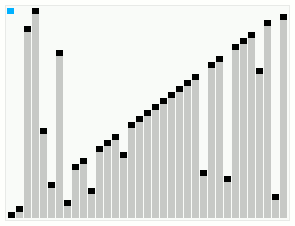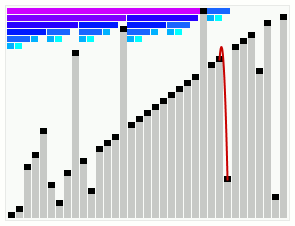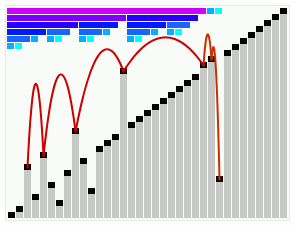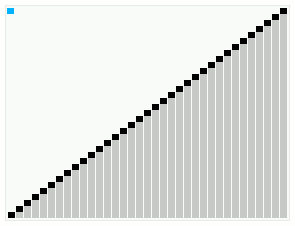
In computer science, smoothsort is a comparison-based sorting algorithm. A variant of heapsort, it was invented and published by Edsger Dijkstra in 1981. Like heapsort, smoothsort is an in-place algorithm with an upper bound of O(n log n) operations (see big O notation), but it is not a stable sort. The advantage of smoothsort is that it comes closer to O(n) time if the input is already sorted to some degree, whereas heapsort averages O(n log n) regardless of the initial sorted state.

In computer science, a self-balancing binary search tree (BST) is any node-based binary search tree that automatically keeps its height small in the face of arbitrary item insertions and deletions. These operations when designed for a self-balancing binary search tree, contain precautionary measures against boundlessly increasing tree height, so that these abstract data structures receive the attribute "self-balancing".

In mathematical analysis and computer science, functions which are Z-order, Lebesgue curve, Morton space-filling curve, Morton order or Morton code map multidimensional data to one dimension well preserving locality of the data points. It is named in France after Henri Lebesgue, who studied it in 1904, and named in the United States after Guy Macdonald Morton, who first applied the order to file sequencing in 1966. The z-value of a point in multidimensions is simply calculated by interleaving the binary representations of its coordinate values. Once the data are sorted into this ordering, any one-dimensional data structure can be used, such as simple one dimensional arrays, binary search trees, B-trees, skip lists or hash tables. The resulting ordering can equivalently be described as the order one would get from a depth-first traversal of a quadtree or octree.

Quicksort is an efficient, general-purpose sorting algorithm. Quicksort was developed by British computer scientist Tony Hoare in 1959 and published in 1961. It is still a commonly used algorithm for sorting. Overall, it is slightly faster than merge sort and heapsort for randomized data, particularly on larger distributions.
In computer science, an algorithm is said to be asymptotically optimal if, roughly speaking, for large inputs it performs at worst a constant factor worse than the best possible algorithm. It is a term commonly encountered in computer science research as a result of widespread use of big-O notation.

A beap, or bi-parental heap, is a data structure for a set that enables elements to be located, inserted, or deleted in sublinear time. In a beap, each element is stored in a node with up to two parents and up to two children, with the property that the value of a parent node is never greater than the value of either of its children.

In computer science, recursion is a method of solving a computational problem where the solution depends on solutions to smaller instances of the same problem. Recursion solves such recursive problems by using functions that call themselves from within their own code. The approach can be applied to many types of problems, and recursion is one of the central ideas of computer science.
The power of recursion evidently lies in the possibility of defining an infinite set of objects by a finite statement. In the same manner, an infinite number of computations can be described by a finite recursive program, even if this program contains no explicit repetitions.
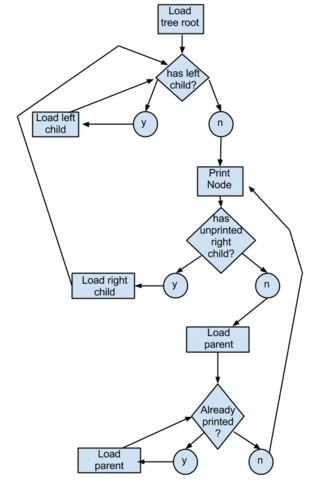
A tree sort is a sort algorithm that builds a binary search tree from the elements to be sorted, and then traverses the tree (in-order) so that the elements come out in sorted order. Its typical use is sorting elements online: after each insertion, the set of elements seen so far is available in sorted order.
In computer science, a succinct data structure is a data structure which uses an amount of space that is "close" to the information-theoretic lower bound, but still allows for efficient query operations. The concept was originally introduced by Jacobson to encode bit vectors, (unlabeled) trees, and planar graphs. Unlike general lossless data compression algorithms, succinct data structures retain the ability to use them in-place, without decompressing them first. A related notion is that of a compressed data structure, insofar as the size of the stored or encoded data similarly depends upon the specific content of the data itself.

Control tables are tables that control the control flow or play a major part in program control. There are no rigid rules about the structure or content of a control table—its qualifying attribute is its ability to direct control flow in some way through "execution" by a processor or interpreter. The design of such tables is sometimes referred to as table-driven design. In some cases, control tables can be specific implementations of finite-state-machine-based automata-based programming. If there are several hierarchical levels of control table they may behave in a manner equivalent to UML state machines
In computer science, a search data structure is any data structure that allows the efficient retrieval of specific items from a set of items, such as a specific record from a database.
In computer science, a weak heap is a data structure for priority queues, combining features of the binary heap and binomial heap. It can be stored in an array as an implicit binary tree like a binary heap, and has the efficiency guarantees of binomial heaps.
References
- ↑ "Thus, only a simple array is needed for the data.", p. 236; "We will draw no formal distinction between a pointer and an integer (index) in the range . A data structure is then implicit, if the only such integer which need be retained is N itself.", p. 238
- ↑ "... one might prefer to permit a constant number of pointers to be retained and still designate the structure as implicit.", p. 238
- ↑ "We will also suggest two structures which might be described as “semi-implicit,” in that a variable, but o(N), number of pointers (indices) is kept.", p. 238
- ↑ Knuth 1998, §6.2.1 ("Searching an ordered table"), subsection "History and bibliography".
- 1 2 3 Franceschini, Gianni; Munro, J. Ian (2006). Implicit dictionaries with O(1) modifications per update and fast search. Seventeenth Annual ACM-SIAM Symposium on Discrete Algorithms. Miami, FL, United States. pp. 404–413. doi:10.1145/1109557.1109603.

- Jacobson, G. J (1988). Succinct static data structures (Ph.D.). Pittsburgh, PA: Carnegie Mellon University.
- Knuth, Donald (1998). Sorting and searching. The Art of Computer Programming. Vol. 3 (2nd ed.). Reading, MA: Addison-Wesley Professional. ISBN 978-0-201-89685-5.
- Munro, J.Ian; Suwanda, Hendra (October 1980). "Implicit data structures for fast search and update". Journal of Computer and System Sciences . 21 (2): 236–250. doi: 10.1016/0022-0000(80)90037-9 .
- Williams, J. W. J. (June 1964). "Algorithm 232 - Heapsort". Communications of the ACM. 7 (6): 347–348. doi:10.1145/512274.512284.