Related Research Articles
In computer science, an array is a data structure consisting of a collection of elements, each identified by at least one array index or key. An array is stored such that the position of each element can be computed from its index tuple by a mathematical formula. The simplest type of data structure is a linear array, also called one-dimensional array.

In computer science, an AVL tree is a self-balancing binary search tree. It was the first such data structure to be invented. In an AVL tree, the heights of the two child subtrees of any node differ by at most one; if at any time they differ by more than one, rebalancing is done to restore this property. Lookup, insertion, and deletion all take O(log n) time in both the average and worst cases, where is the number of nodes in the tree prior to the operation. Insertions and deletions may require the tree to be rebalanced by one or more tree rotations.

In computer science, binary search, also known as half-interval search, logarithmic search, or binary chop, is a search algorithm that finds the position of a target value within a sorted array. Binary search compares the target value to the middle element of the array. If they are not equal, the half in which the target cannot lie is eliminated and the search continues on the remaining half, again taking the middle element to compare to the target value, and repeating this until the target value is found. If the search ends with the remaining half being empty, the target is not in the array.

In computer science, a binary search tree (BST), also called an ordered or sorted binary tree, is a rooted binary tree data structure with the key of each internal node being greater than all the keys in the respective node's left subtree and less than the ones in its right subtree. The time complexity of operations on the binary search tree is directly proportional to the height of the tree.

In computing, a hash table, also known as hash map, is a data structure that implements an associative array or dictionary. It is an abstract data type that maps keys to values. A hash table uses a hash function to compute an index, also called a hash code, into an array of buckets or slots, from which the desired value can be found. During lookup, the key is hashed and the resulting hash indicates where the corresponding value is stored.

In computer science, a heap is a specialized tree-based data structure which is essentially an almost complete tree that satisfies the heap property: in a max heap, for any given node C, if P is a parent node of C, then the key of P is greater than or equal to the key of C. In a min heap, the key of P is less than or equal to the key of C. The node at the "top" of the heap is called the root node.

Insertion sort is a simple sorting algorithm that builds the final sorted array (or list) one item at a time by comparisons. It is much less efficient on large lists than more advanced algorithms such as quicksort, heapsort, or merge sort. However, insertion sort provides several advantages:
In computer science, a linked list is a linear collection of data elements whose order is not given by their physical placement in memory. Instead, each element points to the next. It is a data structure consisting of a collection of nodes which together represent a sequence. In its most basic form, each node contains: data, and a reference to the next node in the sequence. This structure allows for efficient insertion or removal of elements from any position in the sequence during iteration. More complex variants add additional links, allowing more efficient insertion or removal of nodes at arbitrary positions. A drawback of linked lists is that access time is linear. Faster access, such as random access, is not feasible. Arrays have better cache locality compared to linked lists.
In computer science, a priority queue is an abstract data-type similar to a regular queue or stack data structure. Each element in a priority queue has an associated priority. In a priority queue, elements with high priority are served before elements with low priority. In some implementations, if two elements have the same priority, they are served in the same order that they were enqueued in. In other implementations, the order of elements with the same priority is undefined.
A splay tree is a binary search tree with the additional property that recently accessed elements are quick to access again. Like self-balancing binary search trees, a splay tree performs basic operations such as insertion, look-up and removal in O(log n) amortized time. For random access patterns drawn from a non-uniform random distribution, their amortized time can be faster than logarithmic, proportional to the entropy of the access pattern. For many patterns of non-random operations, also, splay trees can take better than logarithmic time, without requiring advance knowledge of the pattern. According to the unproven dynamic optimality conjecture, their performance on all access patterns is within a constant factor of the best possible performance that could be achieved by any other self-adjusting binary search tree, even one selected to fit that pattern. The splay tree was invented by Daniel Sleator and Robert Tarjan in 1985.

A binary heap is a heap data structure that takes the form of a binary tree. Binary heaps are a common way of implementing priority queues. The binary heap was introduced by J. W. J. Williams in 1964, as a data structure for heapsort.
In computer science, an associative array, map, symbol table, or dictionary is an abstract data type that stores a collection of pairs, such that each possible key appears at most once in the collection. In mathematical terms, an associative array is a function with finite domain. It supports 'lookup', 'remove', and 'insert' operations.
In computer science, a set is an abstract data type that can store unique values, without any particular order. It is a computer implementation of the mathematical concept of a finite set. Unlike most other collection types, rather than retrieving a specific element from a set, one typically tests a value for membership in a set.

In computer science, the treap and the randomized binary search tree are two closely related forms of binary search tree data structures that maintain a dynamic set of ordered keys and allow binary searches among the keys. After any sequence of insertions and deletions of keys, the shape of the tree is a random variable with the same probability distribution as a random binary tree; in particular, with high probability its height is proportional to the logarithm of the number of keys, so that each search, insertion, or deletion operation takes logarithmic time to perform.

In computer science, a self-balancing binary search tree (BST) is any node-based binary search tree that automatically keeps its height small in the face of arbitrary item insertions and deletions. These operations when designed for a self-balancing binary search tree, contain precautionary measures against boundlessly increasing tree height, so that these abstract data structures receive the attribute "self-balancing".
A van Emde Boas tree, also known as a vEB tree or van Emde Boas priority queue, is a tree data structure which implements an associative array with m-bit integer keys. It was invented by a team led by Dutch computer scientist Peter van Emde Boas in 1975. It performs all operations in O(log m) time, or equivalently in O(log log M) time, where M = 2m is the largest element that can be stored in the tree. The parameter M is not to be confused with the actual number of elements stored in the tree, by which the performance of other tree data-structures is often measured.
In computer science, a scapegoat tree is a self-balancing binary search tree, invented by Arne Andersson in 1989 and again by Igal Galperin and Ronald L. Rivest in 1993. It provides worst-case lookup time and amortized insertion and deletion time.
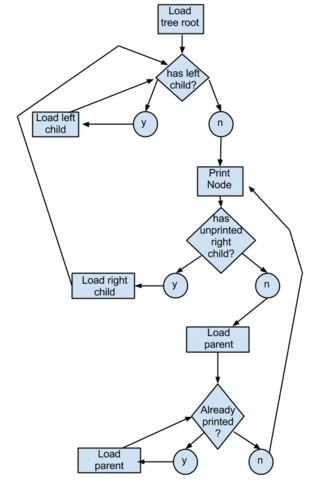
A tree sort is a sort algorithm that builds a binary search tree from the elements to be sorted, and then traverses the tree (in-order) so that the elements come out in sorted order. Its typical use is sorting elements online: after each insertion, the set of elements seen so far is available in sorted order.
In computer science, a search data structure is any data structure that allows the efficient retrieval of specific items from a set of items, such as a specific record from a database.
In computer science, input enhancement is the principle that processing a given input to a problem and altering it in a specific way will increase runtime efficiency or space efficiency, or both. The altered input is usually stored and accessed to simplify the problem. By exploiting the structure and properties of the inputs, input enhancement creates various speed-ups in the efficiency of the algorithm.
References
- ↑ Donald Knuth, The Art of Computer Programming , vol. 3. Addison-Wesley
- ↑ Operating System Concepts by Peter B. Galvin. WILEY-INDIA Pvt. limited. ISBN 978-81-265-2051-0.