In formal language theory, a context-sensitive language is a language that can be defined by a context-sensitive grammar. Context-sensitive is one of the four types of grammars in the Chomsky hierarchy.

In formal language theory, a context-free grammar (CFG) is a formal grammar whose production rules are of the form
In formal language theory, a context-free language (CFL) is a language generated by a context-free grammar (CFG).
In theoretical computer science and formal language theory, a regular language is a formal language that can be defined by a regular expression, in the strict sense in theoretical computer science.
In mathematics and computer science, the right quotient of a language with respect to language is the language consisting of strings w such that wx is in for some string x in . Formally:
In mathematics, subadditivity is a property of a function that states, roughly, that evaluating the function for the sum of two elements of the domain always returns something less than or equal to the sum of the function's values at each element. There are numerous examples of subadditive functions in various areas of mathematics, particularly norms and square roots. Additive maps are special cases of subadditive functions.

Szemerédi's regularity lemma is one of the most powerful tools in extremal graph theory, particularly in the study of large dense graphs. It states that the vertices of every large enough graph can be partitioned into a bounded number of parts so that the edges between different parts behave almost randomly.
In the theory of formal languages, the pumping lemma for regular languages is a lemma that describes an essential property of all regular languages. Informally, it says that all sufficiently long strings in a regular language may be pumped—that is, have a middle section of the string repeated an arbitrary number of times—to produce a new string that is also part of the language.
In computer science, in particular in formal language theory, the pumping lemma for context-free languages, also known as the Bar-Hillel lemma, is a lemma that gives a property shared by all context-free languages and generalizes the pumping lemma for regular languages.
In the theory of formal languages, Ogden's lemma is a generalization of the pumping lemma for context-free languages.
Indexed grammars are a generalization of context-free grammars in that nonterminals are equipped with lists of flags, or index symbols. The language produced by an indexed grammar is called an indexed language.
In formal language theory, a grammar describes how to form strings from a language's alphabet that are valid according to the language's syntax. A grammar does not describe the meaning of the strings or what can be done with them in whatever context—only their form. A formal grammar is defined as a set of production rules for such strings in a formal language.
In mathematics, the ping-pong lemma, or table-tennis lemma, is any of several mathematical statements that ensure that several elements in a group acting on a set freely generates a free subgroup of that group.
In computer science, more specifically in automata and formal language theory, nested words are a concept proposed by Alur and Madhusudan as a joint generalization of words, as traditionally used for modelling linearly ordered structures, and of ordered unranked trees, as traditionally used for modelling hierarchical structures. Finite-state acceptors for nested words, so-called nested word automata, then give a more expressive generalization of finite automata on words. The linear encodings of languages accepted by finite nested word automata gives the class of visibly pushdown languages. The latter language class lies properly between the regular languages and the deterministic context-free languages. Since their introduction in 2004, these concepts have triggered much research in that area.
Controlled grammars are a class of grammars that extend, usually, the context-free grammars with additional controls on the derivations of a sentence in the language. A number of different kinds of controlled grammars exist, the four main divisions being Indexed grammars, grammars with prescribed derivation sequences, grammars with contextual conditions on rule application, and grammars with parallelism in rule application. Because indexed grammars are so well established in the field, this article will address only the latter three kinds of controlled grammars.
Parikh's theorem in theoretical computer science says that if one looks only at the number of occurrences of each terminal symbol in a context-free language, without regard to their order, then the language is indistinguishable from a regular language. It is useful for deciding that strings with a given number of terminals are not accepted by a context-free grammar. It was first proved by Rohit Parikh in 1961 and republished in 1966.
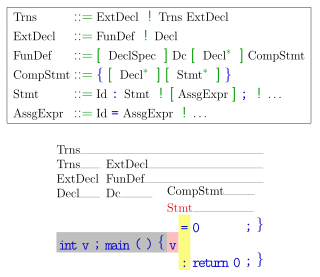
In formal language theory, an LL grammar is a context-free grammar that can be parsed by an LL parser, which parses the input from Left to right, and constructs a Leftmost derivation of the sentence. A language that has an LL grammar is known as an LL language. These form subsets of deterministic context-free grammars (DCFGs) and deterministic context-free languages (DCFLs), respectively. One says that a given grammar or language "is an LL grammar/language" or simply "is LL" to indicate that it is in this class.
Roth's theorem on arithmetic progressions is a result in additive combinatorics concerning the existence of arithmetic progressions in subsets of the natural numbers. It was first proven by Klaus Roth in 1953. Roth's Theorem is a special case of Szemerédi's Theorem for the case .
In abstract algebra, Kaplansky's theorem on projective modules, first proven by Irving Kaplansky, states that a projective module over a local ring is free; where a not-necessary-commutative ring is called local if for each element x, either x or 1 − x is a unit element. The theorem can also be formulated so to characterize a local ring.
In mathematics, the hypergraph regularity method is a powerful tool in extremal graph theory that refers to the combined application of the hypergraph regularity lemma and the associated counting lemma. It is a generalization of the graph regularity method, which refers to the use of Szemerédi's regularity and counting lemmas.
















