Related Research Articles

The Chomsky hierarchy in the fields of formal language theory, computer science, and linguistics, is a containment hierarchy of classes of formal grammars. A formal grammar describes how to form strings from a language's vocabulary that are valid according to the language's syntax. The linguist Noam Chomsky theorized that four different classes of formal grammars existed that could generate increasingly complex languages. Each class can also completely generate the language of all inferior classes.

In formal language theory, a context-free grammar (CFG) is a formal grammar whose production rules can be applied to a nonterminal symbol regardless of its context. In particular, in a context-free grammar, each production rule is of the form
In formal language theory, a context-free language (CFL), also called a Chomsky type-2 language, is a language generated by a context-free grammar (CFG).
In computer science, an LALR parser is part of the compiling process where human readable text is converted into a structured representation to be read by computers. An LALR parser is a software tool to process (parse) text into a very specific internal representation that other programs, such as compilers, can work with. This process happens according to a set of production rules specified by a formal grammar for a computer language.
In computer science, LR parsers are a type of bottom-up parser that analyse deterministic context-free languages in linear time. There are several variants of LR parsers: SLR parsers, LALR parsers, canonical LR(1) parsers, minimal LR(1) parsers, and generalized LR parsers. LR parsers can be generated by a parser generator from a formal grammar defining the syntax of the language to be parsed. They are widely used for the processing of computer languages.
In computer science, a Simple LR or SLR parser is a type of LR parser with small parse tables and a relatively simple parser generator algorithm. As with other types of LR(1) parser, an SLR parser is quite efficient at finding the single correct bottom-up parse in a single left-to-right scan over the input stream, without guesswork or backtracking. The parser is mechanically generated from a formal grammar for the language.
A canonical LR parser is a type of bottom-up parsing algorithm used in computer science to analyze and process programming languages. It is based on the LR parsing technique, which stands for "left-to-right, rightmost derivation in reverse."

Richard Edwin Stearns is an American computer scientist who, with Juris Hartmanis, received the 1993 ACM Turing Award "in recognition of their seminal paper which established the foundations for the field of computational complexity theory". In 1994 he was inducted as a Fellow of the Association for Computing Machinery.
In computer science, an ambiguous grammar is a context-free grammar for which there exists a string that can have more than one leftmost derivation or parse tree. Every non-empty context-free language admits an ambiguous grammar by introducing e.g. a duplicate rule. A language that only admits ambiguous grammars is called an inherently ambiguous language. Deterministic context-free grammars are always unambiguous, and are an important subclass of unambiguous grammars; there are non-deterministic unambiguous grammars, however.
An operator precedence grammar is a kind of grammar for formal languages.
This is a list of notable lexer generators and parser generators for various language classes.
In automata theory, a deterministic pushdown automaton is a variation of the pushdown automaton. The class of deterministic pushdown automata accepts the deterministic context-free languages, a proper subset of context-free languages.
In formal language theory, deterministic context-free languages (DCFL) are a proper subset of context-free languages. They are the context-free languages that can be accepted by a deterministic pushdown automaton. DCFLs are always unambiguous, meaning that they admit an unambiguous grammar. There are non-deterministic unambiguous CFLs, so DCFLs form a proper subset of unambiguous CFLs.
In computer science, SYNTAX is a system used to generate lexical and syntactic analyzers (parsers) for all kinds of context-free grammars (CFGs) as well as some classes of contextual grammars. It has been developed at INRIA in France for several decades, mostly by Pierre Boullier, but has become free software since 2007 only. SYNTAX is distributed under the CeCILL license.

In computing, a compiler is a computer program that transforms source code written in a programming language or computer language, into another computer language. The most common reason for transforming source code is to create an executable program.
A lookahead LR parser (LALR) generator is a software tool that reads a context-free grammar (CFG) and creates an LALR parser which is capable of parsing files written in the context-free language defined by the CFG. LALR parsers are desirable because they are very fast and small in comparison to other types of parsers.

Information and Computation is a closed-access computer science journal published by Elsevier. The journal was founded in 1957 under its former name Information and Control and given its current title in 1987. As of July 2022, the current editor-in-chief is David Peleg. The journal publishes 12 issues a year.
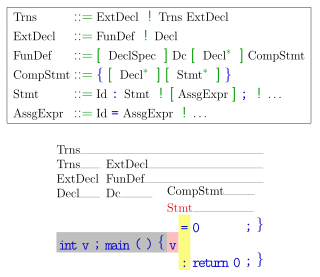
In formal language theory, an LL grammar is a context-free grammar that can be parsed by an LL parser, which parses the input from Left to right, and constructs a Leftmost derivation of the sentence. A language that has an LL grammar is known as an LL language. These form subsets of deterministic context-free grammars (DCFGs) and deterministic context-free languages (DCFLs), respectively. One says that a given grammar or language "is an LL grammar/language" or simply "is LL" to indicate that it is in this class.
A shift-reduce parser is a class of efficient, table-driven bottom-up parsing methods for computer languages and other notations formally defined by a grammar. The parsing methods most commonly used for parsing programming languages, LR parsing and its variations, are shift-reduce methods. The precedence parsers used before the invention of LR parsing are also shift-reduce methods. All shift-reduce parsers have similar outward effects, in the incremental order in which they build a parse tree or call specific output actions.

JFLAP is interactive educational software written in Java for experimenting with topics in the computer science area of formal languages and automata theory, primarily intended for use at the undergraduate level or as an advanced topic for high school. JFLAP allows one to create and simulate structures, such as programming a finite state machine, and experiment with proofs, such as converting a nondeterministic finite automaton (NFA) to a deterministic finite automaton (DFA).
References
- ↑ Chomsky, Noam (1962). "Context Free Grammars and Pushdown Storage". Quarterly Progress Report, MIT Research Laboratory in Electronics. 65: 187–194.
- ↑ Evey, R.J. (1963). "Application of Pushdown-Store Machines". 1963 AFIPS Proceedings of the Fall Joint Computer Conference: 215–227.
- ↑ Schützenberger, Marcel Paul (1963). "On Context-Free Languages and Push-Down Automata". Information and Control. 6 (3): 246–264. doi: 10.1016/s0019-9958(63)90306-1 .
- ↑ A. Salomaa; D. Wood; S. Yu, eds. (2001). A Half-Century of Automata Theory . World Scientific Publishing. pp. 38–39.
- ↑ Knuth, D. E. (July 1965). "On the translation of languages from left to right". Information and Control. 8 (6): 607–639. doi: 10.1016/S0019-9958(65)90426-2 .
- ↑ Franklin L. DeRemer (1969). "Practical Translators for LR(k) languages" (PDF). MIT, PhD Dissertation. Archived from the original (PDF) on 2012-04-05.
- ↑ X. Chen, Measuring and extending LR(1) parsing, University of Hawaii PhD dissertation, 2009.