
A finite-state machine (FSM) or finite-state automaton, finite automaton, or simply a state machine, is a mathematical model of computation. It is an abstract machine that can be in exactly one of a finite number of states at any given time. The FSM can change from one state to another in response to some inputs; the change from one state to another is called a transition. An FSM is defined by a list of its states, its initial state, and the inputs that trigger each transition. Finite-state machines are of two types—deterministic finite-state machines and non-deterministic finite-state machines. For any non-deterministic finite-state machine, an equivalent deterministic one can be constructed.
In theoretical computer science, a nondeterministic Turing machine (NTM) is a theoretical model of computation whose governing rules specify more than one possible action when in some given situations. That is, an NTM's next state is not completely determined by its action and the current symbol it sees, unlike a deterministic Turing machine.
In the theory of computation, a branch of theoretical computer science, a pushdown automaton (PDA) is a type of automaton that employs a stack.

A Turing machine is a mathematical model of computation describing an abstract machine that manipulates symbols on a strip of tape according to a table of rules. Despite the model's simplicity, it is capable of implementing any computer algorithm.
In computer science, an abstract machine is a theoretical model that allows for a detailed and precise analysis of how a computer system functions. It is similar to a mathematical function in that it receives inputs and produces outputs based on predefined rules. Abstract machines vary from literal machines in that they are expected to perform correctly and independently of hardware. Abstract machines are "machines" because they allow step-by-step execution of programmes; they are "abstract" because they ignore many aspects of actual (hardware) machines. A typical abstract machine consists of a definition in terms of input, output, and the set of allowable operations used to turn the former into the latter. They can be used for purely theoretical reasons as well as models for real-world computer systems. In the theory of computation, abstract machines are often used in thought experiments regarding computability or to analyse the complexity of algorithms. This use of abstract machines is fundamental to the field of computational complexity theory, such as finite state machines, Mealy machines, push-down automata, and Turing machines.
Automata theory is the study of abstract machines and automata, as well as the computational problems that can be solved using them. It is a theory in theoretical computer science with close connections to mathematical logic. The word automata comes from the Greek word αὐτόματος, which means "self-acting, self-willed, self-moving". An automaton is an abstract self-propelled computing device which follows a predetermined sequence of operations automatically. An automaton with a finite number of states is called a finite automaton (FA) or finite-state machine (FSM). The figure on the right illustrates a finite-state machine, which is a well-known type of automaton. This automaton consists of states and transitions. As the automaton sees a symbol of input, it makes a transition to another state, according to its transition function, which takes the previous state and current input symbol as its arguments.
In the theory of computation, a tag system is a deterministic model of computation published by Emil Leon Post in 1943 as a simple form of a Post canonical system. A tag system may also be viewed as an abstract machine, called a Post tag machine —briefly, a finite-state machine whose only tape is a FIFO queue of unbounded length, such that in each transition the machine reads the symbol at the head of the queue, deletes a constant number of symbols from the head, and appends to the tail a symbol-string that depends solely on the first symbol read in this transition.

Theoretical computer science is a subfield of computer science and mathematics that focuses on the abstract and mathematical foundations of computation.

In mathematics, an expression is a written arrangement of symbols following the context-dependent, syntactic conventions of mathematical notation. Symbols can denote numbers (constants), variables, operations, and functions. Other symbols include punctuation marks and brackets, used for grouping where there is not a well-defined order of operations.

In the theory of computation, a branch of theoretical computer science, a deterministic finite automaton (DFA)—also known as deterministic finite acceptor (DFA), deterministic finite-state machine (DFSM), or deterministic finite-state automaton (DFSA)—is a finite-state machine that accepts or rejects a given string of symbols, by running through a state sequence uniquely determined by the string. Deterministic refers to the uniqueness of the computation run. In search of the simplest models to capture finite-state machines, Warren McCulloch and Walter Pitts were among the first researchers to introduce a concept similar to finite automata in 1943.
The X-machine (XM) is a theoretical model of computation introduced by Samuel Eilenberg in 1974. The X in "X-machine" represents the fundamental data type on which the machine operates; for example, a machine that operates on databases would be a database-machine. The X-machine model is structurally the same as the finite-state machine, except that the symbols used to label the machine's transitions denote relations of type X→X. Crossing a transition is equivalent to applying the relation that labels it, and traversing a path in the machine corresponds to applying all the associated relations, one after the other.
Unconventional computing is computing by any of a wide range of new or unusual methods.
A Turing machine is a hypothetical computing device, first conceived by Alan Turing in 1936. Turing machines manipulate symbols on a potentially infinite strip of tape according to a finite table of rules, and they provide the theoretical underpinnings for the notion of a computer algorithm.

In computational complexity theory and circuit complexity, a Boolean circuit is a mathematical model for combinational digital logic circuits. A formal language can be decided by a family of Boolean circuits, one circuit for each possible input length.

Spiking neural networks (SNNs) are artificial neural networks (ANN) that more closely mimic natural neural networks. These models leverage timing of discrete spikes as the main information carrier.
Biological computers use biologically derived molecules — such as DNA and/or proteins — to perform digital or real computations.
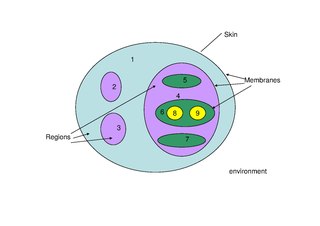
Membrane computing is an area within computer science that seeks to discover new computational models from the study of biological cells, particularly of the cellular membranes. It is a sub-task of creating a cellular model.
Membrane systems have been inspired from the structure and the functioning of the living cells. They were introduced and studied by Gh.Paun under the name of P systems [24]; some applications of the membrane systems are presented in [15]. Membrane systems are essentially models of distributed, parallel and nondeterministic systems. Here we motivate and present the mobile membranes. Mobile membranes represent a variant of membrane systems inspired by the biological movements given by endocytosis and exocytosis. They have the expressive power of both P systems and process calculi with mobility such as mobile ambients [11] and brane calculi [10]. Computations with mobile membranes can be defined over specific configurations, while they represent also a rule-based formalism.
Natural computing, also called natural computation, is a terminology introduced to encompass three classes of methods: 1) those that take inspiration from nature for the development of novel problem-solving techniques; 2) those that are based on the use of computers to synthesize natural phenomena; and 3) those that employ natural materials to compute. The main fields of research that compose these three branches are artificial neural networks, evolutionary algorithms, swarm intelligence, artificial immune systems, fractal geometry, artificial life, DNA computing, and quantum computing, among others.
In computational learning theory, induction of regular languages refers to the task of learning a formal description of a regular language from a given set of example strings. Although E. Mark Gold has shown that not every regular language can be learned this way, approaches have been investigated for a variety of subclasses. They are sketched in this article. For learning of more general grammars, see Grammar induction.
