A protease is an enzyme that helps proteolysis: protein catabolism by hydrolysis of peptide bonds. Proteases have evolved multiple times, and different classes of protease can perform the same reaction by completely different catalytic mechanisms. Proteases can be found in all forms of life and viruses.
Serine proteases are enzymes that cleave peptide bonds in proteins, in which serine serves as the nucleophilic amino acid at the (enzyme's) active site. They are found ubiquitously in both eukaryotes and prokaryotes. Serine proteases fall into two broad categories based on their structure: chymotrypsin-like (trypsin-like) or subtilisin-like. In humans, they are responsible for coordinating various physiological functions, including digestion, immune response, blood coagulation and reproduction.
Acetylation describes a reaction that introduces an acetyl functional group into a chemical compound. Deacetylation is the removal of an acetyl group.
A metalloproteinase, or metalloprotease, is any protease enzyme whose catalytic mechanism involves a metal. An example of this would be meltrin which plays a significant role in the fusion of muscle cells during embryo development, in a process known as myogenesis.
Phospholipase D (PLD) is an enzyme of the phospholipase superfamily. Phospholipases occur widely, and can be found in a wide range of organisms, including bacteria, yeast, plants, animals, and viruses. Phospholipase D’s principal substrate is phosphatidylcholine, which it hydrolyzes to produce the signal molecule phosphatidic acid (PA), and soluble choline. Plants contain numerous genes that encode various PLD isoenzymes, with molecular weights ranging from 90-125 kDa. Mammalian cells encode two isoforms of phospholipase D: PLD1 and PLD2. Phospholipase D is an important player in many physiological processes, including membrane trafficking, cytoskeletal reorganization, receptor-mediated endocytosis, exocytosis, and cell migration. Through these processes, it has been further implicated in the pathophysiology of multiple diseases: in particular the progression of Parkinson’s and Alzheimer’s, as well as various cancers.
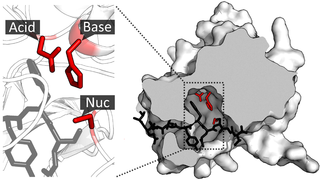
Serine hydrolases are one of the largest known enzyme classes comprising approximately ~200 enzymes or 1% of the genes in the human proteome. A defining characteristic of these enzymes is the presence of a nucleophilic serine in their active site, which is used for the hydrolysis of substrates. Catalysis proceeds by the formation of an acyl-enzyme intermediate through this serine, followed by water/hydroxide-induced saponification of the intermediate and regeneration of the enzyme. Unlike other non-catalytic serines, the nucleophilic serine of these hydrolases is typically activated by a proton relay involving a catalytic triad consisting of the serine, an acidic residue and a basic residue, although variations on this mechanism exist.

Acyl-CoA thioesterase 2, also known as ACOT2, is an enzyme which in humans is encoded by the ACOT2 gene.
Acyl-coenzyme A thioesterase 4 is an enzyme that in humans is encoded by the ACOT4 gene.

Acyl-coenzyme A thioesterase 11 also known as StAR-related lipid transfer protein 14 (STARD14) is an enzyme that in humans is encoded by the ACOT11 gene. This gene encodes a protein with acyl-CoA thioesterase activity towards medium (C12) and long-chain (C18) fatty acyl-CoA substrates which relies on its StAR-related lipid transfer domain. Expression of a similar murine protein in brown adipose tissue is induced by cold exposure and repressed by warmth. Expression of the mouse protein has been associated with obesity, with higher expression found in obesity-resistant mice compared with obesity-prone mice. Alternative splicing results in two transcript variants encoding different isoforms.
N-Acylphosphatidylethanolamines (NAPEs) are hormones released by the small intestine into the bloodstream when it processes fat. NAPEs travel to the hypothalamus in the brain and suppress appetite. This mechanism could be relevant for treating obesity.
N-acyl phosphatidylethanolamine phospholipase D (NAPE-PLD) is an enzyme that catalyzes the release of N-acylethanolamine (NAE) from N-acyl-phosphatidylethanolamine (NAPE). This is a major part of the process that converts ordinary lipids into chemical signals like anandamide and oleoylethanolamine. In humans, the NAPE-PLD protein is encoded by the NAPEPLD gene.

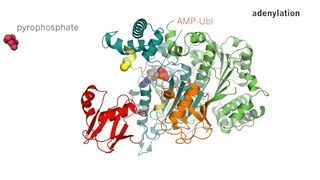
Threonine proteases are a family of proteolytic enzymes harbouring a threonine (Thr) residue within the active site. The prototype members of this class of enzymes are the catalytic subunits of the proteasome, however the acyltransferases convergently evolved the same active site geometry and mechanism.
Acyl-CoA thioesterase 6 is a protein that in humans is encoded by the ACOT6 gene. The protein, also known as C14orf42, is an enzyme with thioesterase activity.

Lysophospholipase-like 1 is a protein in humans that is encoded by the LYPLAL1 gene. The protein is a α/β-hydrolase of uncharacterized metabolic function. Genome-wide association studies in humans have linked the gene to fat distribution and waist-to-hip ratio. The protein's enzymatic function is unclear. LYPLAL1 was reported to act as a triglyceride lipase in adipose tissue and another study suggested that the protein may play a role in the depalmitoylation of calcium-activated potassium channels. However, LYPLAL1 does not depalmitoylate the oncogene Ras and a structural and enzymatic study concluded that LYPLAL1 is generally unable to act as a lipase and is instead an esterase that prefers short-chain substrates, such as acetyl groups. Structural comparisons have suggested that LYPLAL1 might be a protein deacetylase, but this has not been experimentally tested.

Acyl-CoA thioesterase 9 is a protein that is encoded by the human ACOT9 gene. It is a member of the acyl-CoA thioesterase superfamily, which is a group of enzymes that hydrolyze Coenzyme A esters. There is no known function, however it has been shown to act as a long-chain thioesterase at low concentrations, and a short-chain thioesterase at high concentrations.

Ketoacyl synthases (KSs) catalyze the condensation reaction of acyl-CoA or acyl-acyl ACP with malonyl-CoA to form 3-ketoacyl-CoA or with malonyl-ACP to form 3-ketoacyl-ACP. This reaction is a key step in the fatty acid synthesis cycle, as the resulting acyl chain is two carbon atoms longer than before. KSs exist as individual enzymes, as they do in type II fatty acid synthesis and type II polyketide synthesis, or as domains in large multidomain enzymes, such as type I fatty acid synthases (FASs) and polyketide synthases (PKSs). KSs are divided into five families: KS1, KS2, KS3, KS4, and KS5.

Acyl-CoA thioesterase 13 is a protein that in humans is encoded by the ACOT13 gene. This gene encodes a member of the thioesterase superfamily. In humans, the protein co-localizes with microtubules and is essential for sustained cell proliferation.
Acyl-CoA thioesterase 1 is a protein that in humans is encoded by the ACOT1 gene.