Sperm microtubule associated protein 1 is a protein which in humans is encoded by the SPMAP1 gene. The protein is derived from Homo sapiens chromosome 17.[5] The SPMAP1 gene consists of a 6,302 base sequence. Its mRNA has three exons and no alternative splice sites. The protein has 154 amino acids, with no abnormal amino acid levels.[6] SPMAP1 has a domain of unknown function (DUF4542) and is 17.6kDa in weight.[7][8] SPMAP1 does not belong to any other families nor does it have any isoforms.[9] The protein has orthologs with high percent similarity in mammals and reptiles. The protein has additional distantly related orthologs across the metazoan kingdom, culminating with the sponge family.[10]
Like most proteins, SPMAP1 is known to be highly expressed in the testes.[11] The protein has also been known to have elevated levels in cancer.[11] The protein has been shown to be expressed in proximity to or within intermediate filaments and the nucleolus.[11] Additionally, SPMAP1 has transcription factors which are also active in hematopoietic stem cells, the immune system, and the cardiovascular system, among others.[12] The gene is over-expressed in many cancer types, including kidney renal clear cell carcinoma and lung squamous cell carcinoma.[13] Motif and transcription factor analysis points towards SPMAP1 playing a role in proliferation, specially in immune cell proliferation.
Gene
Background
The SPMAP1 gene consists of 6,303 bases. It has three exons and two large introns. The gene has no alternative splice sites.[14] The 5' UTR sequence of SPMAP1 is highly conserved in primates. No non-mammalian 5' UTR matches were able to be determined.[15][16]SPMAP1 has 11 Alu repeats.[17]
Enhancers
GeneCards determined that SPMAP1 has five enhancer sequences. The role of the sequences may provide insight into the function of SPMAP1. Four of the five enhancers are active in the thymus. All five enhancers are active in the H1 hESC. Additionally, all five enhancers are active in iPS DF 19.11 derived from foreskin fibroblasts.[18]
Transcription factors
The SPMAP1 promoter has many transcription factors binding sites.[19] SPMAP1's transcription factors are commonly found in hematopoietic cells, connective tissue, cardiovascular tissue, and the immune system. The presence of Krueppel Like Transcription Factors suggests a role for SPMAP1 in proliferation or apoptosis. The presence of SMAD indicates an involvement in the TGF-β pathway, while the presence of Myc related transcription factors indicates a potential proliferation function of the protein. Additionally, other SPMAP1 transcription factors, like RBPJ-Kappa are involved in proliferation and signalling.
Variants
Numerous SNPs were found in the 5' UTR, 3' UTR, and coding region of SPMAP1.[20] Few SNPs were found in highly conserved regions. In all, four SNPs were found in the highly conserved amino acids. One SNP was found in the start codon sequence. Of these five, three had a SNP on the third position of the codon. Due to the wobble hypothesis, three of the five SNPs would have no effect on the overall protein structure.
mRNA
SPMAP1 does not have any miRNA binding sites.[21] Its mRNA has low abundance (0.44%).[22] The mRNA sequence has three hexaloops, none of which are significant.[23]
Protein
Primary structure
SPMAP1 is a 17.6kDa protein.[8] Distant orthologs are 5 to 6 kDa larger, but some of the discrepancies come from an added NLS sequence, which Homo sapiens does not have There are no positive or negative charge clusters. There are no transmembrane components. The isoelectric point is 9.80 / 17564.67 pI/Mw.[24] SPMAP1 is hydrophobic and soluble.
Secondary structure and phosphorylation sites
Secondary and tertiary structure
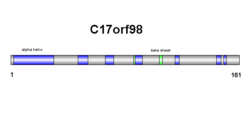
Secondary structure of SPMAP1 consists of both beta sheets and alpha helices (see diagram on right). Results are confirmed in the tertiary structure, however, alpha helix and beta sheet numbers differ slightly (see diagram on right).
Motifs and binding sites
There are no N-terminal signal peptides. Cleavage motifs were not found. There are no ER membrane retention signals, nor peroxisomal targeting signal. SKL2 is not present, thus a secondary peroxisome signal is not present. There are no vacuolar targeting signals. There are no RNA binding motifs or actinin type actin binding motifs. There are no N-myristoylation pattern or prenylation patterns.[25]
SWISS-MODEL 3D structure of SPMAP1
Kinase finder at Cuckoo determined kinase binding sites for SPMAP1. There are many Serine/Threonine, and Tyrosine kinase phosphorylation sites.[26] Serine and Threonine kinase binding sites are the most prevalent above the statistically significant threshold. There are no SUMOylation sites.[27]SPMAP1 gene has six sites on the sequence of possible O-GlcNAc sites.[28] Highly conserved O-GlcNAc amino acid sites are 24, 32, 117, and 142. O-GlcNAc post-translational modification occurs on Ser/Thr residues, specifically on oncogenes, tumor suppressors, and proteins involved in growth factor signaling.[29]
SPMAP1 has a Caspase3/7 motif, where either Caspase 3 or 7 would cleave.[30] This supports the idea that SPMAP1 is involved in proliferation, as a proapoptotic caspase would want to destroy any protein driving proliferation. The protein also has a motif where peptidyl-prolyl cis-trans isomerase NIMA interacting 1 (Pin1) binds.[30] Pin1 upregulation is involved in cancer and immune disorders.[31] This supports the claim that SPMAP1 is involved in cancer, immune cells, and perhaps cancers of the immune system. Additionally, SPMAP1 protein has an IBM site, where inhibitors of apoptosis (IAPs) bind.[30] This again supports the idea of SPMAP1 being involved in inhibiting apoptosis, and logically, driving cancer. Furthermore, SPMAP1 has motifs where GRB2's SH2 domain binds. GRB2 is an adapter protein involved in the RAS signaling pathway, a pathway that when deregulated drives uncontrolled proliferation.
Amino acid sequence
A duplication may have occurred at positions 59–71.
Protein abundance in Homo sapiens whole organism is quite low. No data is available for other species.[36] Allen Brain Atlas yields no brain atlas for SPMAP1.[37]
Subcellular localization
SPMAP1 protein has been found to be expressed in the intermediate filaments and the nucleoli.[38] A SPMAP1 antibody is available from Sigma-Aldrich.[39] Additionally, SPMAP1 localizes in the cytoplasm. Distantly related SPMAP1 orthologs in organisms such as Macrostomum lignano and Amphimedon queenslandica exhibit nuclear expression.[40]Nuclear localization signals are present in distantly related organisms in non-conserved sites. The results of the k-NN prediction is cytoplasmic localization.[41] SPMAP1 is not a signal peptide.[42] The protein is a soluble.[43]
Tissue
Like most proteins, SPMAP1 protein is highly expressed in the testes.[44] The protein is expressed on adult tissues as well as fetal tissue. The protein has been found to be mildly expressed in connective tissue.[45] Additionally, expression has been seen in the sperm, breast epithelial cells, and various cells of the immune system.[46]
Clinical significance
Cancer
Protein expression is elevated in many cancer patients. Specifically, protein expression has been shown to be high on colorectal, breast, prostate, and lung.[47] SPMAP1 is expressed in papillary thyroid cancer as well.[48] Additionally, mutations were found in SPMAP1 in endometrial, stomach, coloratura, and kidney cancer.[49] SPMAP1 expression is elevated in cancer patients with BRCA. In kidney renal clear cell carcinoma patients, SPMAP1 expression dramatically decreased compared to the non cancerous state.[13] In 80% of chromophobe renal cell carcinoma patients, at least one gene duplication SPMAP1 was present.[13]
Other conditions
Protein expression is lower in males with teratozoospermia as compared to those without.[50] Many Geo Profile experiments have been conducted with SPMAP1, however, none yield data showing significant change in expression.[51]
Evolution
SPMAP1 is a slow mutating protein. It resembles cytochrome c in its rate of divergence, as determined by the molecular clock equations.[52]
Unrooted SPMAP1 Phylogenetic Tree with 20 orthologs (see table below)
Paralogs
There are no known Homo sapiens paralogs for SPMAP1.[53]
Orthologs
SPMAP1 protein has additional distantly related orthologs across the metazoan kingdom. Its most distant relative is in the sponge family. There is no known ortholog in ctenophores, nematodes, bacteria, fungus, plants, or zebrafish.[10] There are only two fish with the SPMAP1 gene. Model organisms such as Caenorhabditis elegans, and Drosophila melanogaster, do not have the gene.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.