An exon is any part of a gene that will form a part of the final mature RNA produced by that gene after introns have been removed by RNA splicing. The term exon refers to both the DNA sequence within a gene and to the corresponding sequence in RNA transcripts. In RNA splicing, introns are removed and exons are covalently joined to one another as part of generating the mature RNA. Just as the entire set of genes for a species constitutes the genome, the entire set of exons constitutes the exome.

In molecular biology, messenger ribonucleic acid (mRNA) is a single-stranded molecule of RNA that corresponds to the genetic sequence of a gene, and is read by a ribosome in the process of synthesizing a protein.

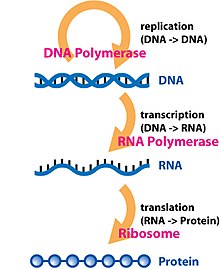
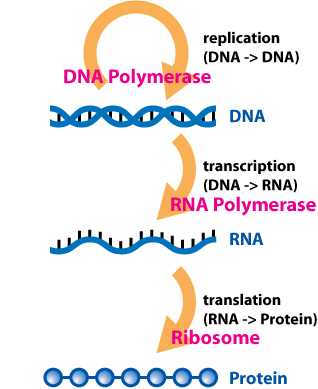
Protein biosynthesis is a core biological process, occurring inside cells, balancing the loss of cellular proteins through the production of new proteins. Proteins perform a number of critical functions as enzymes, structural proteins or hormones. Protein synthesis is a very similar process for both prokaryotes and eukaryotes but there are some distinct differences.
Non-coding DNA (ncDNA) sequences are components of an organism's DNA that do not encode protein sequences. Some non-coding DNA is transcribed into functional non-coding RNA molecules. Other functional regions of the non-coding DNA fraction include regulatory sequences that control gene expression; scaffold attachment regions; origins of DNA replication; centromeres; and telomeres. Some non-coding regions appear to be mostly nonfunctional, such as introns, pseudogenes, intergenic DNA, and fragments of transposons and viruses. Regions that are completely nonfunctional are called junk DNA.
The coding region of a gene, also known as the coding sequence (CDS), is the portion of a gene's DNA or RNA that codes for a protein. Studying the length, composition, regulation, splicing, structures, and functions of coding regions compared to non-coding regions over different species and time periods can provide a significant amount of important information regarding gene organization and evolution of prokaryotes and eukaryotes. This can further assist in mapping the human genome and developing gene therapy.
In molecular genetics, the three prime untranslated region (3′-UTR) is the section of messenger RNA (mRNA) that immediately follows the translation termination codon. The 3′-UTR often contains regulatory regions that post-transcriptionally influence gene expression.
In molecular biology, reading frames are defined as spans of DNA sequence between the start and stop codons. Usually, this is considered within a studied region of a prokaryotic DNA sequence, where only one of the six possible reading frames will be "open". Such an ORF may contain a start codon and by definition cannot extend beyond a stop codon. That start codon indicates where translation may start. The transcription termination site is located after the ORF, beyond the translation stop codon. If transcription were to cease before the stop codon, an incomplete protein would be made during translation.
The 5′ untranslated region is the region of a messenger RNA (mRNA) that is directly upstream from the initiation codon. This region is important for the regulation of translation of a transcript by differing mechanisms in viruses, prokaryotes and eukaryotes. While called untranslated, the 5′ UTR or a portion of it is sometimes translated into a protein product. This product can then regulate the translation of the main coding sequence of the mRNA. In many organisms, however, the 5′ UTR is completely untranslated, instead forming a complex secondary structure to regulate translation.

In genetics, a silencer is a DNA sequence capable of binding transcription regulation factors, called repressors. DNA contains genes and provides the template to produce messenger RNA (mRNA). That mRNA is then translated into proteins. When a repressor protein binds to the silencer region of DNA, RNA polymerase is prevented from transcribing the DNA sequence into RNA. With transcription blocked, the translation of RNA into proteins is impossible. Thus, silencers prevent genes from being expressed as proteins.

The start codon is the first codon of a messenger RNA (mRNA) transcript translated by a ribosome. The start codon always codes for methionine in eukaryotes and archaea and a N-formylmethionine (fMet) in bacteria, mitochondria and plastids.
Eukaryotic translation is the biological process by which messenger RNA is translated into proteins in eukaryotes. It consists of four phases: initiation, elongation, termination, and recapping.
The Kozak consensus sequence is a nucleic acid motif that functions as the protein translation initiation site in most eukaryotic mRNA transcripts. Regarded as the optimum sequence for initiating translation in eukaryotes, the sequence is an integral aspect of protein regulation and overall cellular health as well as having implications in human disease. It ensures that a protein is correctly translated from the genetic message, mediating ribosome assembly and translation initiation. A wrong start site can result in non-functional proteins. As it has become more studied, expansions of the nucleotide sequence, bases of importance, and notable exceptions have arisen. The sequence was named after the scientist who discovered it, Marilyn Kozak. Kozak discovered the sequence through a detailed analysis of DNA genomic sequences.
Gene structure is the organisation of specialised sequence elements within a gene. Genes contain most of the information necessary for living cells to survive and reproduce. In most organisms, genes are made of DNA, where the particular DNA sequence determines the function of the gene. A gene is transcribed (copied) from DNA into RNA, which can either be non-coding (ncRNA) with a direct function, or an intermediate messenger (mRNA) that is then translated into protein. Each of these steps is controlled by specific sequence elements, or regions, within the gene. Every gene, therefore, requires multiple sequence elements to be functional. This includes the sequence that actually encodes the functional protein or ncRNA, as well as multiple regulatory sequence regions. These regions may be as short as a few base pairs, up to many thousands of base pairs long.
Eukaryotic chromosome fine structure refers to the structure of sequences for eukaryotic chromosomes. Some fine sequences are included in more than one class, so the classification listed is not intended to be completely separate.

Directionality, in molecular biology and biochemistry, is the end-to-end chemical orientation of a single strand of nucleic acid. In a single strand of DNA or RNA, the chemical convention of naming carbon atoms in the nucleotide pentose-sugar-ring means that there will be a 5′ end, which frequently contains a phosphate group attached to the 5′ carbon of the ribose ring, and a 3′ end, which typically is unmodified from the ribose -OH substituent. In a DNA double helix, the strands run in opposite directions to permit base pairing between them, which is essential for replication or transcription of the encoded information.
A ribosome binding site, or ribosomal binding site (RBS), is a sequence of nucleotides upstream of the start codon of an mRNA transcript that is responsible for the recruitment of a ribosome during the initiation of translation. Mostly, RBS refers to bacterial sequences, although internal ribosome entry sites (IRES) have been described in mRNAs of eukaryotic cells or viruses that infect eukaryotes. Ribosome recruitment in eukaryotes is generally mediated by the 5' cap present on eukaryotic mRNAs.
The 5′ flanking region is a region of DNA that is adjacent to the 5′ end of the gene. The 5′ flanking region contains the promoter, and may contain enhancers or other protein binding sites. It is the region of DNA that is not transcribed into RNA. Not to be confused with the 5′ untranslated region, this region is not transcribed into RNA or translated into a functional protein. These regions primarily function in the regulation of gene transcription. 5′ flanking regions are categorized between prokaryotes and eukaryotes.

Red clover necrotic mosaic virus (RCNMV) contains several structural elements present within the 3′ and 5′ untranslated regions (UTR) of the genome that enhance translation. In eukaryotes transcription is a prerequisite for translation. During transcription the pre-mRNA transcript is processes where a 5′ cap is attached onto mRNA and this 5′ cap allows for ribosome assembly onto the mRNA as it acts as a binding site for the eukaryotic initiation factor eIF4F. Once eIF4F is bound to the mRNA this protein complex interacts with the poly(A) binding protein which is present within the 3′ UTR and results in mRNA circularization. This multiprotein-mRNA complex then recruits the ribosome subunits and scans the mRNA until it reaches the start codon. Transcription of viral genomes differs from eukaryotes as viral genomes produce mRNA transcripts that lack a 5’ cap site. Despite lacking a cap site viral genes contain a structural element within the 5’ UTR known as an internal ribosome entry site (IRES). IRES is a structural element that recruits the 40s ribosome subunit to the mRNA within close proximity of the start codon.
Translational regulation refers to the control of the levels of protein synthesized from its mRNA. This regulation is vastly important to the cellular response to stressors, growth cues, and differentiation. In comparison to transcriptional regulation, it results in much more immediate cellular adjustment through direct regulation of protein concentration. The corresponding mechanisms are primarily targeted on the control of ribosome recruitment on the initiation codon, but can also involve modulation of peptide elongation, termination of protein synthesis, or ribosome biogenesis. While these general concepts are widely conserved, some of the finer details in this sort of regulation have been proven to differ between prokaryotic and eukaryotic organisms.
The split gene theory is a theory of the origin of introns, long non-coding sequences in eukaryotic genes between the exons. The theory holds that the randomness of primordial DNA sequences would only permit small (< 600bp) open reading frames (ORFs), and that important intron structures and regulatory sequences are derived from stop codons. In this introns-first framework, the spliceosomal machinery and the nucleus evolved due to the necessity to join these ORFs into larger proteins, and that intronless bacterial genes are less ancestral than the split eukaryotic genes. The theory originated with Periannan Senapathy.