
A semantic network, or frame network is a knowledge base that represents semantic relations between concepts in a network. This is often used as a form of knowledge representation. It is a directed or undirected graph consisting of vertices, which represent concepts, and edges, which represent semantic relations between concepts, mapping or connecting semantic fields. A semantic network may be instantiated as, for example, a graph database or a concept map. Typical standardized semantic networks are expressed as semantic triples.
Word-sense disambiguation is the process of identifying which sense of a word is meant in a sentence or other segment of context. In human language processing and cognition, it is usually subconscious.
David Courtenay Marr was a British neuroscientist and physiologist. Marr integrated results from psychology, artificial intelligence, and neurophysiology into new models of visual processing. His work was influential in computational neuroscience and led to a resurgence of interest in the discipline.
Semantic memory refers to general world knowledge that humans have accumulated throughout their lives. This general knowledge is intertwined in experience and dependent on culture. New concepts are learned by applying knowledge learned from things in the past.
Latent semantic analysis (LSA) is a technique in natural language processing, in particular distributional semantics, of analyzing relationships between a set of documents and the terms they contain by producing a set of concepts related to the documents and terms. LSA assumes that words that are close in meaning will occur in similar pieces of text. A matrix containing word counts per document is constructed from a large piece of text and a mathematical technique called singular value decomposition (SVD) is used to reduce the number of rows while preserving the similarity structure among columns. Documents are then compared by cosine similarity between any two columns. Values close to 1 represent very similar documents while values close to 0 represent very dissimilar documents.
Semantic similarity is a metric defined over a set of documents or terms, where the idea of distance between items is based on the likeness of their meaning or semantic content as opposed to lexicographical similarity. These are mathematical tools used to estimate the strength of the semantic relationship between units of language, concepts or instances, through a numerical description obtained according to the comparison of information supporting their meaning or describing their nature. The term semantic similarity is often confused with semantic relatedness. Semantic relatedness includes any relation between two terms, while semantic similarity only includes "is a" relations. For example, "car" is similar to "bus", but is also related to "road" and "driving".
Neurophilosophy or the philosophy of neuroscience is the interdisciplinary study of neuroscience and philosophy that explores the relevance of neuroscientific studies to the arguments traditionally categorized as philosophy of mind. The philosophy of neuroscience attempts to clarify neuroscientific methods and results using the conceptual rigor and methods of philosophy of science.
In linguistics, statistical semantics applies the methods of statistics to the problem of determining the meaning of words or phrases, ideally through unsupervised learning, to a degree of precision at least sufficient for the purpose of information retrieval.

Distributional semantics is a research area that develops and studies theories and methods for quantifying and categorizing semantic similarities between linguistic items based on their distributional properties in large samples of language data. The basic idea of distributional semantics can be summed up in the so-called distributional hypothesis: linguistic items with similar distributions have similar meanings.
Hierarchical temporal memory (HTM) is a biologically constrained machine intelligence technology developed by Numenta. Originally described in the 2004 book On Intelligence by Jeff Hawkins with Sandra Blakeslee, HTM is primarily used today for anomaly detection in streaming data. The technology is based on neuroscience and the physiology and interaction of pyramidal neurons in the neocortex of the mammalian brain.
Sparse distributed memory (SDM) is a mathematical model of human long-term memory introduced by Pentti Kanerva in 1988 while he was at NASA Ames Research Center.
Pentti Kanerva is an American neuroscientist and the originator of the sparse distributed memory model. He is responsible for relating the properties of long-term memory to mathematical properties of high-dimensional spaces and compares artificial neural-net associative memory to conventional computer random-access memory and to the neurons in the brain. This theory has been applied to design and implement the random indexing approach to learning semantic relations from linguistic data. Kanerva was also the first to use a computer clipboard to preserve deleted texts. The operation would later come to be known as cut, copy, and paste.
Random indexing is a dimensionality reduction method and computational framework for distributional semantics, based on the insight that very-high-dimensional vector space model implementations are impractical, that models need not grow in dimensionality when new items are encountered, and that a high-dimensional model can be projected into a space of lower dimensionality without compromising L2 distance metrics if the resulting dimensions are chosen appropriately.
The following outline is provided as an overview of and topical guide to natural-language processing:
In natural language processing, a word embedding is a representation of a word. The embedding is used in text analysis. Typically, the representation is a real-valued vector that encodes the meaning of the word in such a way that the words that are closer in the vector space are expected to be similar in meaning. Word embeddings can be obtained using language modeling and feature learning techniques, where words or phrases from the vocabulary are mapped to vectors of real numbers.
Word2vec is a technique in natural language processing (NLP) for obtaining vector representations of words. These vectors capture information about the meaning of the word based on the surrounding words. The word2vec algorithm estimates these representations by modeling text in a large corpus. Once trained, such a model can detect synonymous words or suggest additional words for a partial sentence. Word2vec was developed by Tomáš Mikolov and colleagues at Google and published in 2013.
A distributional–relational database, or word-vector database, is a database management system (DBMS) that uses distributional word-vector representations to enrich the semantics of structured data.
Semantic spaces in the natural language domain aim to create representations of natural language that are capable of capturing meaning. The original motivation for semantic spaces stems from two core challenges of natural language: Vocabulary mismatch and ambiguity of natural language.
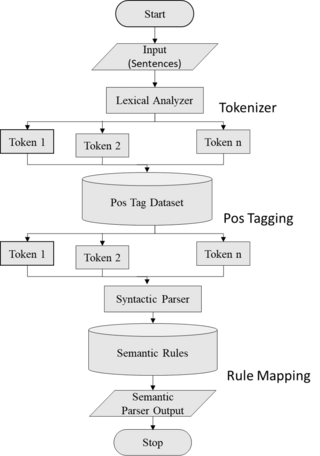
Semantic parsing is the task of converting a natural language utterance to a logical form: a machine-understandable representation of its meaning. Semantic parsing can thus be understood as extracting the precise meaning of an utterance. Applications of semantic parsing include machine translation, question answering, ontology induction, automated reasoning, and code generation. The phrase was first used in the 1970s by Yorick Wilks as the basis for machine translation programs working with only semantic representations. Semantic parsing is one of the important tasks in computational linguistics and natural language processing.
The usage-based linguistics is a linguistics approach within a broader functional/cognitive framework, that emerged since the late 1980s, and that assumes a profound relation between linguistic structure and usage. It challenges the dominant focus, in 20th century linguistics, on considering language as an isolated system removed from its use in human interaction and human cognition. Rather, usage-based models posit that linguistic information is expressed via context-sensitive mental processing and mental representations, which have the cognitive ability to succinctly account for the complexity of actual language use at all levels. Broadly speaking, a usage-based model of language accounts for language acquisition and processing, synchronic and diachronic patterns, and both low-level and high-level structure in language, by looking at actual language use.

