Related Research Articles

A primer is a short single-stranded nucleic acid used by all living organisms in the initiation of DNA synthesis. DNA polymerase enzymes are only capable of adding nucleotides to the 3’-end of an existing nucleic acid, requiring a primer be bound to the template before DNA polymerase can begin a complementary strand. DNA polymerase adds nucleotides after binding to the RNA primer and synthesizes the whole strand. Later, the RNA strands must be removed accurately and replace them with DNA nucleotides forming a gap region known as a nick that is filled in using an enzyme called ligase. The removal process of the RNA primer requires several enzymes, such as Fen1, Lig1, and others that work in coordination with DNA polymerase, to ensure the removal of the RNA nucleotides and the addition of DNA nucleotides. Living organisms use solely RNA primers, while laboratory techniques in biochemistry and molecular biology that require in vitro DNA synthesis usually use DNA primers, since they are more temperature stable. Primers can be designed in laboratory for specific reactions such as polymerase chain reaction (PCR). When designing PCR primers, there are specific measures that must be taken into consideration, like the melting temperature of the primers and the annealing temperature of the reaction itself. Moreover, the DNA binding sequence of the primer in vitro has to be specifically chosen, which is done using a method called basic local alignment search tool (BLAST) that scans the DNA and finds specific and unique regions for the primer to bind.

Protein biosynthesis is a core biological process, occurring inside cells, balancing the loss of cellular proteins through the production of new proteins. Proteins perform a number of critical functions as enzymes, structural proteins or hormones. Protein synthesis is a very similar process for both prokaryotes and eukaryotes but there are some distinct differences.

Ribonucleic acid (RNA) is a polymeric molecule that is essential for most biological functions, either by performing the function itself or by forming a template for production of proteins. RNA and deoxyribonucleic acid (DNA) are nucleic acids. The nucleic acids constitute one of the four major macromolecules essential for all known forms of life. RNA is assembled as a chain of nucleotides. Cellular organisms use messenger RNA (mRNA) to convey genetic information that directs synthesis of specific proteins. Many viruses encode their genetic information using an RNA genome.

The central dogma of molecular biology is an explanation of the flow of genetic information within a biological system. It is often stated as "DNA makes RNA, and RNA makes protein", although this is not its original meaning. It was first stated by Francis Crick in 1957, then published in 1958:
The Central Dogma. This states that once "information" has passed into protein it cannot get out again. In more detail, the transfer of information from nucleic acid to nucleic acid, or from nucleic acid to protein may be possible, but transfer from protein to protein, or from protein to nucleic acid is impossible. Information here means the precise determination of sequence, either of bases in the nucleic acid or of amino acid residues in the protein.
Transcription is the process of copying a segment of DNA into RNA. The segments of DNA transcribed into RNA molecules that can encode proteins are said to produce messenger RNA (mRNA). Other segments of DNA are copied into RNA molecules called non-coding RNAs (ncRNAs). mRNA comprises only 1–3% of total RNA samples. Less than 2% of the human genome can be transcribed into mRNA, while at least 80% of mammalian genomic DNA can be actively transcribed, with the majority of this 80% considered to be ncRNA.
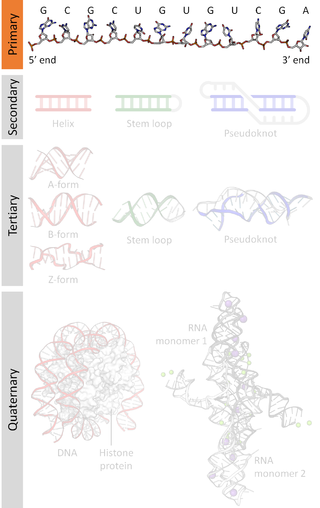
A nucleic acid sequence is a succession of bases within the nucleotides forming alleles within a DNA or RNA (GACU) molecule. This succession is denoted by a series of a set of five different letters that indicate the order of the nucleotides. By convention, sequences are usually presented from the 5' end to the 3' end. For DNA, with its double helix, there are two possible directions for the notated sequence; of these two, the sense strand is used. Because nucleic acids are normally linear (unbranched) polymers, specifying the sequence is equivalent to defining the covalent structure of the entire molecule. For this reason, the nucleic acid sequence is also termed the primary structure.
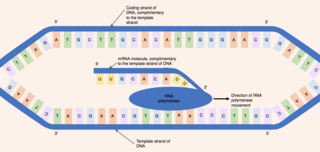
When referring to DNA transcription, the coding strand is the DNA strand whose base sequence is identical to the base sequence of the RNA transcript produced. It is this strand which contains codons, while the non-coding strand contains anticodons. During transcription, RNA Pol II binds to the non-coding template strand, reads the anti-codons, and transcribes their sequence to synthesize an RNA transcript with complementary bases.

In molecular biology, a reading frame is a way of dividing the sequence of nucleotides in a nucleic acid molecule into a set of consecutive, non-overlapping triplets. Where these triplets equate to amino acids or stop signals during translation, they are called codons.
A cDNA library is a combination of cloned cDNA fragments inserted into a collection of host cells, which constitute some portion of the transcriptome of the organism and are stored as a "library". cDNA is produced from fully transcribed mRNA found in the nucleus and therefore contains only the expressed genes of an organism. Similarly, tissue-specific cDNA libraries can be produced. In eukaryotic cells the mature mRNA is already spliced, hence the cDNA produced lacks introns and can be readily expressed in a bacterial cell. While information in cDNA libraries is a powerful and useful tool since gene products are easily identified, the libraries lack information about enhancers, introns, and other regulatory elements found in a genomic DNA library.

Antisense RNA (asRNA), also referred to as antisense transcript, natural antisense transcript (NAT) or antisense oligonucleotide, is a single stranded RNA that is complementary to a protein coding messenger RNA (mRNA) with which it hybridizes, and thereby blocks its translation into protein. The asRNAs have been found in both prokaryotes and eukaryotes, and can be classified into short and long non-coding RNAs (ncRNAs). The primary function of asRNA is regulating gene expression. asRNAs may also be produced synthetically and have found wide spread use as research tools for gene knockdown. They may also have therapeutic applications.

A primary transcript is the single-stranded ribonucleic acid (RNA) product synthesized by transcription of DNA, and processed to yield various mature RNA products such as mRNAs, tRNAs, and rRNAs. The primary transcripts designated to be mRNAs are modified in preparation for translation. For example, a precursor mRNA (pre-mRNA) is a type of primary transcript that becomes a messenger RNA (mRNA) after processing.
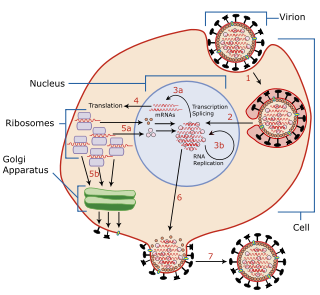
Viral replication is the formation of biological viruses during the infection process in the target host cells. Viruses must first get into the cell before viral replication can occur. Through the generation of abundant copies of its genome and packaging these copies, the virus continues infecting new hosts. Replication between viruses is greatly varied and depends on the type of genes involved in them. Most DNA viruses assemble in the nucleus while most RNA viruses develop solely in cytoplasm.

A heteroduplex is a double-stranded (duplex) molecule of nucleic acid originated through the genetic recombination of single complementary strands derived from different sources, such as from different homologous chromosomes or even from different organisms.
Baltimore classification is a system used to classify viruses based on their manner of messenger RNA (mRNA) synthesis. By organizing viruses based on their manner of mRNA production, it is possible to study viruses that behave similarly as a distinct group. Seven Baltimore groups are described that take into consideration whether the viral genome is made of deoxyribonucleic acid (DNA) or ribonucleic acid (RNA), whether the genome is single- or double-stranded, and whether the sense of a single-stranded RNA genome is positive or negative.
In molecular biology and genetics, the sense of a nucleic acid molecule, particularly of a strand of DNA or RNA, refers to the nature of the roles of the strand and its complement in specifying a sequence of amino acids. Depending on the context, sense may have slightly different meanings. For example, negative-sense strand of DNA is equivalent to the template strand, whereas the positive-sense strand is the non-template strand whose nucleotide sequence is equivalent to the sequence of the mRNA transcript.

Directionality, in molecular biology and biochemistry, is the end-to-end chemical orientation of a single strand of nucleic acid. In a single strand of DNA or RNA, the chemical convention of naming carbon atoms in the nucleotide pentose-sugar-ring means that there will be a 5′ end, which frequently contains a phosphate group attached to the 5′ carbon of the ribose ring, and a 3′ end, which typically is unmodified from the ribose -OH substituent. In a DNA double helix, the strands run in opposite directions to permit base pairing between them, which is essential for replication or transcription of the encoded information.
Bacterial transcription is the process in which a segment of bacterial DNA is copied into a newly synthesized strand of messenger RNA (mRNA) with use of the enzyme RNA polymerase.
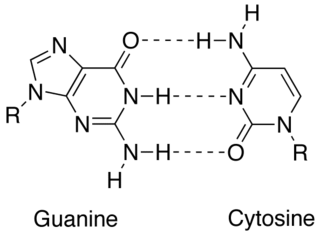
In molecular biology, complementarity describes a relationship between two structures each following the lock-and-key principle. In nature complementarity is the base principle of DNA replication and transcription as it is a property shared between two DNA or RNA sequences, such that when they are aligned antiparallel to each other, the nucleotide bases at each position in the sequences will be complementary, much like looking in the mirror and seeing the reverse of things. This complementary base pairing allows cells to copy information from one generation to another and even find and repair damage to the information stored in the sequences.
This glossary of genetics is a list of definitions of terms and concepts commonly used in the study of genetics and related disciplines in biology, including molecular biology, cell biology, and evolutionary biology. It is intended as introductory material for novices; for more specific and technical detail, see the article corresponding to each term. For related terms, see Glossary of evolutionary biology.
This glossary of genetics is a list of definitions of terms and concepts commonly used in the study of genetics and related disciplines in biology, including molecular biology, cell biology, and evolutionary biology. It is split across two articles:
References
- ↑ Polyak, Kornelia (2003). "Cancer Medicine 6 Overview: Gene Structure". US National Library of Medicine. Retrieved 17 September 2019.
- ↑ Nakayama, Tomohiro (2007). "Overlapping Genes in the Human Genome". International Journal of Biomedical Science. 3 (1): 14–19. PMC 3614620 . PMID 23675016.
- Merrill, Dr. Gary F. 'Transcription', lecture notes distributed in Biochemistry 451 General Biochemistry, Oregon State University, Weigend on 6 Jun. 2006.