Related Research Articles

A Beowulf cluster is a computer cluster of what are normally identical, commodity-grade computers networked into a small local area network with libraries and programs installed which allow processing to be shared among them. The result is a high-performance parallel computing cluster from inexpensive personal computer hardware.
Checkpointing is a technique that provides fault tolerance for computing systems. It involves saving a snapshot of an application's state, so that it can restart from that point in case of failure. This is particularly important for long-running applications that are executed in failure-prone computing systems.
MOSIX is a proprietary distributed operating system. Although early versions were based on older UNIX systems, since 1999 it focuses on Linux clusters and grids. In a MOSIX cluster/grid there is no need to modify or to link applications with any library, to copy files or login to remote nodes, or even to assign processes to different nodes – it is all done automatically, like in an SMP.
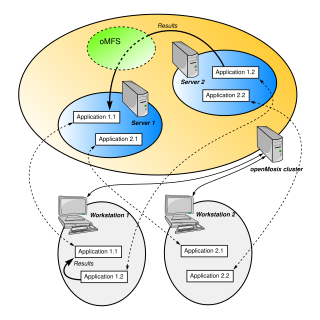
openMosix was a free cluster management system that provided single-system image (SSI) capabilities, e.g. automatic work distribution among nodes. It allowed program processes to migrate to machines in the node's network that would be able to run that process faster. It was particularly useful for running parallel applications having low to moderate input/output (I/O). It was released as a Linux kernel patch, but was also available on specialized Live CDs. openMosix development has been halted by its developers, but the LinuxPMI project is continuing development of the former openMosix code.
OpenSSI is an open-source single-system image clustering system. It allows a collection of computers to be treated as one large system, allowing applications running on any one machine access to the resources of all the machines in the cluster.
In computing, the Global File System 2 (GFS2) is a shared-disk file system for Linux computer clusters. GFS2 allows all members of a cluster to have direct concurrent access to the same shared block storage, in contrast to distributed file systems which distribute data throughout the cluster. GFS2 can also be used as a local file system on a single computer.
Kerrighed is an open source single-system image (SSI) cluster software project. The project started in October 1998 at the Paris research group The French National Institute for Research in Computer Science and Control. From 2006 to 2011, the project was mainly developed by Kerlabs. In January, 2012 the Linux clustering mission of Kerlabs was adopted by a new company: We Cluster, Inc. headquartered in Pacific Grove, California. January 18, 2012: Kerrighed 3.0 has been ported to Ubuntu 12.04 with Linux Kernel v3.2.

A diskless node is a workstation or personal computer without disk drives, which employs network booting to load its operating system from a server.
High-availability clusters are groups of computers that support server applications that can be reliably utilized with a minimum amount of down-time. They operate by using high availability software to harness redundant computers in groups or clusters that provide continued service when system components fail. Without clustering, if a server running a particular application crashes, the application will be unavailable until the crashed server is fixed. HA clustering remedies this situation by detecting hardware/software faults, and immediately restarting the application on another system without requiring administrative intervention, a process known as failover. As part of this process, clustering software may configure the node before starting the application on it. For example, appropriate file systems may need to be imported and mounted, network hardware may have to be configured, and some supporting applications may need to be running as well.
OS-level virtualization is an operating system (OS) virtualization paradigm in which the kernel allows the existence of multiple isolated user space instances, including containers, zones, virtual private servers (OpenVZ), partitions, virtual environments (VEs), virtual kernels, and jails. Such instances may look like real computers from the point of view of programs running in them. A computer program running on an ordinary operating system can see all resources of that computer. Programs running inside a container can only see the container's contents and devices assigned to the container.
GPFS is high-performance clustered file system software developed by IBM. It can be deployed in shared-disk or shared-nothing distributed parallel modes, or a combination of these. It is used by many of the world's largest commercial companies, as well as some of the supercomputers on the Top 500 List. For example, it is the filesystem of the Summit at Oak Ridge National Laboratory which was the #1 fastest supercomputer in the world in the November 2019 Top 500 List. Summit is a 200 Petaflops system composed of more than 9,000 POWER9 processors and 27,000 NVIDIA Volta GPUs. The storage filesystem is called Alpine.
In database computing, Oracle Real Application Clusters (RAC) — an option for the Oracle Database software produced by Oracle Corporation and introduced in 2001 with Oracle9i — provides software for clustering and high availability in Oracle database environments. Oracle Corporation includes RAC with the Enterprise Edition, provided the nodes are clustered using Oracle Clusterware.

OpenVZ is an operating-system-level virtualization technology for Linux. It allows a physical server to run multiple isolated operating system instances, called containers, virtual private servers (VPSs), or virtual environments (VEs). OpenVZ is similar to Solaris Containers and LXC.
The Parallel Virtual File System (PVFS) is an open-source parallel file system. A parallel file system is a type of distributed file system that distributes file data across multiple servers and provides for concurrent access by multiple tasks of a parallel application. PVFS was designed for use in large scale cluster computing. PVFS focuses on high performance access to large data sets. It consists of a server process and a client library, both of which are written entirely of user-level code. A Linux kernel module and pvfs-client process allow the file system to be mounted and used with standard utilities. The client library provides for high performance access via the message passing interface (MPI). PVFS is being jointly developed between The Parallel Architecture Research Laboratory at Clemson University and the Mathematics and Computer Science Division at Argonne National Laboratory, and the Ohio Supercomputer Center. PVFS development has been funded by NASA Goddard Space Flight Center, The DOE Office of Science Advanced Scientific Computing Research program, NSF PACI and HECURA programs, and other government and private agencies. PVFS is now known as OrangeFS in its newest development branch.
Apache Hadoop is a collection of open-source software utilities for reliable, scalable, distributed computing. It provides a software framework for distributed storage and processing of big data using the MapReduce programming model. Hadoop was originally designed for computer clusters built from commodity hardware, which is still the common use. It has since also found use on clusters of higher-end hardware. All the modules in Hadoop are designed with a fundamental assumption that hardware failures are common occurrences and should be automatically handled by the framework.
A diskless shared-root cluster is a way to manage several machines at the same time. Instead of each having its own operating system (OS) on its local disk, there is only one image of the OS available on a server, and all the nodes use the same image.
In computing, process migration is a specialized form of process management whereby processes are moved from one computing environment to another. This originated in distributed computing, but is now used more widely. On multicore machines process migration happens as a standard part of process scheduling, and it is quite easy to migrate a process within a given machine, since most resources do not need to be changed, only the execution context.
A clustered file system (CFS) is a file system which is shared by being simultaneously mounted on multiple servers. There are several approaches to clustering, most of which do not employ a clustered file system. Clustered file systems can provide features like location-independent addressing and redundancy which improve reliability or reduce the complexity of the other parts of the cluster. Parallel file systems are a type of clustered file system that spread data across multiple storage nodes, usually for redundancy or performance.

A computer cluster is a set of computers that work together so that they can be viewed as a single system. Unlike grid computers, computer clusters have each node set to perform the same task, controlled and scheduled by software. The newest manifestation of cluster computing is cloud computing.
NonStop Clusters (NSC) was an add-on package for SCO UnixWare that allowed creation of fault-tolerant single-system image clusters of machines running UnixWare. NSC was one of the first commercially available highly available clustering solutions for commodity hardware.
References
- ↑ Pfister, Gregory F. (1998), In search of clusters , Upper Saddle River, NJ: Prentice Hall PTR, ISBN 978-0-13-899709-0, OCLC 38300954
- ↑ Buyya, Rajkumar; Cortes, Toni; Jin, Hai (2001), "Single System Image" (PDF), International Journal of High Performance Computing Applications, 15 (2): 124, doi:10.1177/109434200101500205, S2CID 38921084
- ↑ Healy, Philip; Lynn, Theo; Barrett, Enda; Morrison, John P. (2016), "Single system image: A survey" (PDF), Journal of Parallel and Distributed Computing, 90–91: 35–51, doi:10.1016/j.jpdc.2016.01.004, hdl:10468/4932
- ↑ Coulouris, George F; Dollimore, Jean; Kindberg, Tim (2005), Distributed systems: concepts and design, Addison Wesley, p. 223, ISBN 978-0-321-26354-4
- ↑ Bolosky, William J.; Draves, Richard P.; Fitzgerald, Robert P.; Fraser, Christopher W.; Jones, Michael B.; Knoblock, Todd B.; Rashid, Rick (1997-05-05), "Operating System Directions for the Next Millennium", 6th Workshop on Hot Topics in Operating Systems (HotOS-VI), Cape Cod, MA, pp. 106–110, CiteSeerX 10.1.1.50.9538 , doi:10.1109/HOTOS.1997.595191, ISBN 978-0-8186-7834-9, S2CID 15380352
{{citation}}: CS1 maint: location missing publisher (link) - ↑ Prabhu, C.S.R. (2009), Grid And Cluster Computing, Phi Learning, p. 256, ISBN 978-81-203-3428-1
- ↑ Smith, Jonathan M. (1988), "A survey of process migration mechanisms" (PDF), ACM SIGOPS Operating Systems Review, 22 (3): 28–40, CiteSeerX 10.1.1.127.8095 , doi:10.1145/47671.47673, S2CID 6611633
- ↑ "AIX PS/2 OS".
- ↑ "Open-Sharedroot GitHub repository". GitHub .
- ↑ Pike, Rob; Presotto, Dave; Thompson, Ken; Trickey, Howard (1990), "Plan 9 from Bell Labs", In Proceedings of the Summer 1990 UKUUG Conference, p. 8,
Process migration is also deliberately absent from Plan 9.
{{citation}}: Missing or empty|title=(help)