The Wiener index is named after Harry Wiener, who introduced it in 1947; at the time, Wiener called it the "path number".[2] It is the oldest topological index related to molecular branching.[3] Based on its success, many other topological indexes of chemical graphs, based on information in the distance matrix of the graph, have been developed subsequently to Wiener's work.[4]
The same quantity has also been studied in pure mathematics, under various names including the gross status,[5] the distance of a graph,[6] and the transmission.[7] The Wiener index is also closely related to the closeness centrality of a vertex in a graph, a quantity inversely proportional to the sum of all distances between the given vertex and all other vertices that has been frequently used in sociometry and the theory of social networks.[6]
Example
Butane (C4H10) has two different structural isomers: n-butane, with a linear structure of four carbon atoms, and isobutane, with a branched structure. The chemical graph for n-butane is a four-vertex path graph, and the chemical graph for isobutane is a tree with one central vertex connected to three leaves.
The two isomers of butane
n-Butane
Isobutane
The n-butane molecule has three pairs of vertices at distance one from each other, two pairs at distance two, and one pair at distance three, so its Wiener index is
The isobutane molecule has three pairs of vertices at distances one from each other (the three leaf-center pairs), and three pairs at distance two (the leaf-leaf pairs). Therefore, its Wiener index is
These numbers are instances of formulas for special cases of the Wiener index: it is for any -vertex path graph such as the graph of n-butane,[8] and for any -vertex star such as the graph of isobutane.[9]
Thus, even though these two molecules have the same chemical formula, and the same numbers of carbon-carbon and carbon-hydrogen bonds, their different structures give rise to different Wiener indices.
The Wiener index may be calculated directly using an algorithm for computing all pairwise distances in the graph. When the graph is unweighted (so the length of a path is just its number of edges), these distances may be calculated by repeating a breadth-first search algorithm, once for each starting vertex.[13] The total time for this approach is O(nm), where n is the number of vertices in the graph and m is its number of edges.
When the underlying graph is a tree (as is true for instance for the alkanes originally studied by Wiener), the Wiener index may be calculated more efficiently. If the graph is partitioned into two subtrees by removing a single edge e, then its Wiener index is the sum of the Wiener indices of the two subtrees, together with a third term representing the paths that pass through e. This third term may be calculated in linear time by computing the sum of distances of all vertices from e within each subtree and multiplying the two sums.[19] This divide and conquer algorithm can be generalized from trees to graphs of bounded treewidth, and leads to near-linear-time algorithms for such graphs.[20]
An alternative method for calculating the Wiener index of a tree, by Bojan Mohar and Tomaž Pisanski, works by generalizing the problem to graphs with weighted vertices, where the weight of a path is the product of its length with the weights of its two endpoints. If v is a leaf vertex of the tree then the Wiener index of the tree may be calculated by merging v with its parent (adding their weights together), computing the index of the resulting smaller tree, and adding a simple correction term for the paths that pass through the edge from v to its parent. By repeatedly removing leaves in this way, the Wiener index may be calculated in linear time.[13]
For graphs that are constructed as products of simpler graphs, the Wiener index of the product graph can often be computed by a simple formula that combines the indices of its factors.[21]Benzenoids (graphs formed by gluing regular hexagons edge-to-edge) can be embedded isometrically into the Cartesian product of three trees, allowing their Wiener indices to be computed in linear time by using the product formula together with the linear time tree algorithm.[22]
The double graph of a graph , denoted , has a known index in relation to itself. For the number of vertices in and the Wiener index :[23]
Inverse problem
Gutman & Yeh (1995) considered the problem of determining which numbers can be represented as the Wiener index of a graph.[24] They showed that all but two positive integers have such a representation; the two exceptions are the numbers 2 and 5, which are not the Wiener index of any graph. For graphs that must be bipartite, they found that again almost all integers can be represented, with a larger set of exceptions: none of the numbers in the set
can be represented as the Wiener index of a bipartite graph.
Gutman and Yeh conjectured, but were unable to prove, a similar description of the numbers that can be represented as Wiener indices of trees, with a set of 49 exceptional values:
12Entringer, R. C.; Jackson, D. E.; Snyder, D. A. (1976), "Distance in graphs", Czechoslovak Mathematical Journal, 26 (101): 283–296, doi:10.21136/CMJ.1976.101401, MR0543771 .
↑Šoltés, Ľubomír (1991), "Transmission in graphs: a bound and vertex removing", Mathematica Slovaca, 41 (1): 11–16, MR1094978 .
↑Stiel, Leonard I.; Thodos, George (1962), "The normal boiling points and critical constants of saturated aliphatic hydrocarbons", AIChE Journal, 8 (4): 527–529, Bibcode:1962AIChE...8..527S, doi:10.1002/aic.690080421 .
↑Rouvray, D. H.; Crafford, B. C. (1976), "The dependence of physical-chemical properties on topological factors", South African Journal of Science, 72: 47.
↑Bersohn, Malcom (1983), "A fast algorithm for calculation of the distance matrix of a molecule", Journal of Computational Chemistry, 4 (1): 110–113, doi:10.1002/jcc.540040115, S2CID122640545 .
↑Müller, W. R.; Szymanski, K.; Knop, J. V.; Trinajstić, N. (1987), "An algorithm for construction of the molecular distance matrix", Journal of Computational Chemistry, 8 (2): 170–173, doi:10.1002/jcc.540080209, S2CID122278769 .
↑Canfield, E. R.; Robinson, R. W.; Rouvray, D. H. (1985), "Determination of the Wiener molecular branching index for the general tree", Journal of Computational Chemistry, 6 (6): 598–609, doi:10.1002/jcc.540060613, MR0824918, S2CID121861478 .
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.
 n-Butane
n-Butane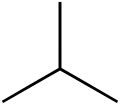 Isobutane
Isobutane








