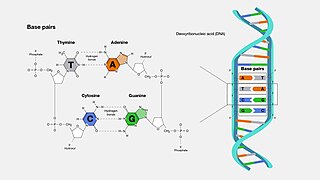
A base pair (bp) is a fundamental unit of double-stranded nucleic acids consisting of two nucleobases bound to each other by hydrogen bonds. They form the building blocks of the DNA double helix and contribute to the folded structure of both DNA and RNA. Dictated by specific hydrogen bonding patterns, "Watson–Crick" base pairs allow the DNA helix to maintain a regular helical structure that is subtly dependent on its nucleotide sequence. The complementary nature of this based-paired structure provides a redundant copy of the genetic information encoded within each strand of DNA. The regular structure and data redundancy provided by the DNA double helix make DNA well suited to the storage of genetic information, while base-pairing between DNA and incoming nucleotides provides the mechanism through which DNA polymerase replicates DNA and RNA polymerase transcribes DNA into RNA. Many DNA-binding proteins can recognize specific base-pairing patterns that identify particular regulatory regions of genes.

The genetic code is the set of rules used by living cells to translate information encoded within genetic material into proteins. Translation is accomplished by the ribosome, which links proteinogenic amino acids in an order specified by messenger RNA (mRNA), using transfer RNA (tRNA) molecules to carry amino acids and to read the mRNA three nucleotides at a time. The genetic code is highly similar among all organisms and can be expressed in a simple table with 64 entries.

Nucleotides are organic molecules composed of a nitrogenous base, a pentose sugar and a phosphate. They serve as monomeric units of the nucleic acid polymers – deoxyribonucleic acid (DNA) and ribonucleic acid (RNA), both of which are essential biomolecules within all life-forms on Earth. Nucleotides are obtained in the diet and are also synthesized from common nutrients by the liver.

Protein biosynthesis is a core biological process, occurring inside cells, balancing the loss of cellular proteins through the production of new proteins. Proteins perform a number of critical functions as enzymes, structural proteins or hormones. Protein synthesis is a very similar process for both prokaryotes and eukaryotes but there are some distinct differences.

Nucleotide bases are nitrogen-containing biological compounds that form nucleosides, which, in turn, are components of nucleotides, with all of these monomers constituting the basic building blocks of nucleic acids. The ability of nucleobases to form base pairs and to stack one upon another leads directly to long-chain helical structures such as ribonucleic acid (RNA) and deoxyribonucleic acid (DNA). Five nucleobases—adenine (A), cytosine (C), guanine (G), thymine (T), and uracil (U)—are called primary or canonical. They function as the fundamental units of the genetic code, with the bases A, G, C, and T being found in DNA while A, G, C, and U are found in RNA. Thymine and uracil are distinguished by merely the presence or absence of a methyl group on the fifth carbon (C5) of these heterocyclic six-membered rings. In addition, some viruses have aminoadenine (Z) instead of adenine. It differs in having an extra amine group, creating a more stable bond to thymine.
In biology, translation is the process in living cells in which proteins are produced using RNA molecules as templates. The generated protein is a sequence of amino acids. This sequence is determined by the sequence of nucleotides in the RNA. The nucleotides are considered three at a time. Each such triple results in addition of one specific amino acid to the protein being generated. The matching from nucleotide triple to amino acid is called the genetic code. The translation is performed by a large complex of functional RNA and proteins called ribosomes. The entire process is called gene expression.
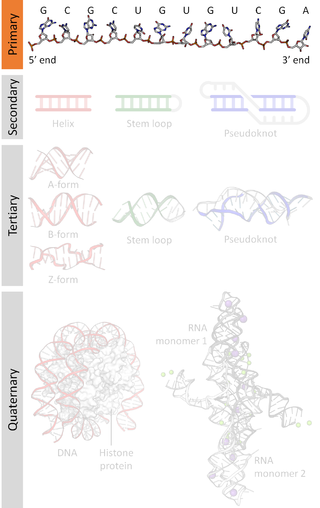
A nucleic acid sequence is a succession of bases within the nucleotides forming alleles within a DNA or RNA (GACU) molecule. This succession is denoted by a series of a set of five different letters that indicate the order of the nucleotides. By convention, sequences are usually presented from the 5' end to the 3' end. For DNA, with its double helix, there are two possible directions for the notated sequence; of these two, the sense strand is used. Because nucleic acids are normally linear (unbranched) polymers, specifying the sequence is equivalent to defining the covalent structure of the entire molecule. For this reason, the nucleic acid sequence is also termed the primary structure.

In biochemistry, a ribonucleotide is a nucleotide containing ribose as its pentose component. It is considered a molecular precursor of nucleic acids. Nucleotides are the basic building blocks of DNA and RNA. Ribonucleotides themselves are basic monomeric building blocks for RNA. Deoxyribonucleotides, formed by reducing ribonucleotides with the enzyme ribonucleotide reductase (RNR), are essential building blocks for DNA. There are several differences between DNA deoxyribonucleotides and RNA ribonucleotides. Successive nucleotides are linked together via phosphodiester bonds.

Transfer RNA is an adaptor molecule composed of RNA, typically 76 to 90 nucleotides in length. In a cell, it provides the physical link between the genetic code in messenger RNA (mRNA) and the amino acid sequence of proteins, carrying the correct sequence of amino acids to be combined by the protein-synthesizing machinery, the ribosome. Each three-nucleotide codon in mRNA is complemented by a three-nucleotide anticodon in tRNA. As such, tRNAs are a necessary component of translation, the biological synthesis of new proteins in accordance with the genetic code.

The Nirenberg and Matthaei experiment was a scientific experiment performed in May 1961 by Marshall W. Nirenberg and his post-doctoral fellow, J. Heinrich Matthaei, at the National Institutes of Health (NIH). The experiment deciphered the first of the 64 triplet codons in the genetic code by using nucleic acid homopolymers to translate specific amino acids.
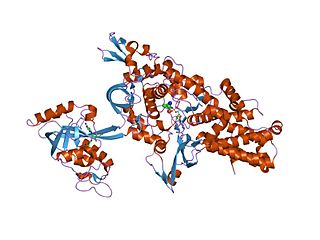
An aminoacyl-tRNA synthetase, also called tRNA-ligase, is an enzyme that attaches the appropriate amino acid onto its corresponding tRNA. It does so by catalyzing the transesterification of a specific cognate amino acid or its precursor to one of all its compatible cognate tRNAs to form an aminoacyl-tRNA. In humans, the 20 different types of aa-tRNA are made by the 20 different aminoacyl-tRNA synthetases, one for each amino acid of the genetic code.

Marshall Warren Nirenberg was an American biochemist and geneticist. He shared a Nobel Prize in Physiology or Medicine in 1968 with Har Gobind Khorana and Robert W. Holley for "breaking the genetic code" and describing how it operates in protein synthesis. In the same year, together with Har Gobind Khorana, he was awarded the Louisa Gross Horwitz Prize from Columbia University.
Biosynthesis, i.e., chemical synthesis occurring in biological contexts, is a term most often referring to multi-step, enzyme-catalyzed processes where chemical substances absorbed as nutrients serve as enzyme substrates, with conversion by the living organism either into simpler or more complex products. Examples of biosynthetic pathways include those for the production of amino acids, lipid membrane components, and nucleotides, but also for the production of all classes of biological macromolecules, and of acetyl-coenzyme A, adenosine triphosphate, nicotinamide adenine dinucleotide and other key intermediate and transactional molecules needed for metabolism. Thus, in biosynthesis, any of an array of compounds, from simple to complex, are converted into other compounds, and so it includes both the catabolism and anabolism of complex molecules. Biosynthetic processes are often represented via charts of metabolic pathways. A particular biosynthetic pathway may be located within a single cellular organelle, while others involve enzymes that are located across an array of cellular organelles and structures.

Nucleic acid analogues are compounds which are analogous to naturally occurring RNA and DNA, used in medicine and in molecular biology research. Nucleic acids are chains of nucleotides, which are composed of three parts: a phosphate backbone, a pentose sugar, either ribose or deoxyribose, and one of four nucleobases. An analogue may have any of these altered. Typically the analogue nucleobases confer, among other things, different base pairing and base stacking properties. Examples include universal bases, which can pair with all four canonical bases, and phosphate-sugar backbone analogues such as PNA, which affect the properties of the chain . Nucleic acid analogues are also called xeno nucleic acids and represent one of the main pillars of xenobiology, the design of new-to-nature forms of life based on alternative biochemistries.
Ribosomal frameshifting, also known as translational frameshifting or translational recoding, is a biological phenomenon that occurs during translation that results in the production of multiple, unique proteins from a single mRNA. The process can be programmed by the nucleotide sequence of the mRNA and is sometimes affected by the secondary, 3-dimensional mRNA structure. It has been described mainly in viruses, retrotransposons and bacterial insertion elements, and also in some cellular genes.

An expanded genetic code is an artificially modified genetic code in which one or more specific codons have been re-allocated to encode an amino acid that is not among the 22 common naturally-encoded proteinogenic amino acids.
Amino acid activation refers to the attachment of an amino acid to its respective transfer RNA (tRNA). The reaction occurs in the cell cytosol and consists of two steps: first, the enzyme aminoacyl tRNA synthetase catalyzes the binding of adenosine triphosphate (ATP) to a corresponding amino acid, forming a reactive aminoacyl adenylate intermediate and releasing inorganic pyrophosphate (PPi). Subsequently, aminoacyl tRNA synthetase binds the AMP-amino acid to a tRNA molecule, releasing AMP and attaching the amino acid to the tRNA. The resulting aminoacyl-tRNA is said to be charged.
The RNA Tie Club was an informal scientific club, meant partly to be humorous, of select scientists who were interested in how proteins were synthesised from genes, specifically the genetic code. It was created by George Gamow upon a suggestion by James Watson in 1954 when the relationship between nucleic acids and amino acids in genetic information was unknown. The club consisted of 20 full members, each representing an amino acid, and four honorary members, representing the four nucleotides. The function of the club members was to think up possible solutions and share with the other members.
An alloprotein is a novel synthetic protein containing one or more "non-natural" amino acids. Non-natural in the context means an amino acid either not occurring in nature, or occurring in nature but not naturally occurring within proteins.
Degeneracy or redundancy of codons is the redundancy of the genetic code, exhibited as the multiplicity of three-base pair codon combinations that specify an amino acid. The degeneracy of the genetic code is what accounts for the existence of synonymous mutations.
