XPath 2.0 is a version of the XPath language defined by the World Wide Web Consortium, W3C. It became a recommendation on 23 January 2007.[1] As a W3C Recommendation it was superseded by XPath 3.0 on 10 April 2014.
XPath is used primarily for selecting parts of an XML document. For this purpose the XML document is modelled as a tree of nodes. XPath allows nodes to be selected by means of a hierarchic navigation path through the document tree.
The language is significantly larger than its predecessor, XPath 1.0, and some of the basic concepts such as the data model and type system have changed. The two language versions are therefore described in separate articles.
XPath 2.0 is used as a sublanguage of XSLT 2.0, and it is also a subset of XQuery 1.0. All three languages share the same data model (the XDM), type system, and function library, and were developed together and published on the same day.
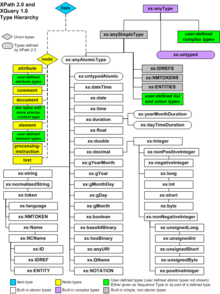
Every value in XPath 2.0 is a sequence of items. The items may be nodes or atomic values. An individual node or atomic value is considered to be a sequence of length one. Sequences may not be nested.
Nodes are of seven kinds, corresponding to different constructs in the syntax of XML: elements, attributes, text nodes, comments, processing instructions, namespace nodes, and document nodes. (The document node replaces the root node of XPath 1.0, because the XPath 2.0 model allows trees to be rooted at other kinds of node, notably elements.)
Nodes may be typed or untyped. A node acquires a type as a result of validation against an XML Schema. If an element or attribute is successfully validated against a particular complex type or simple type defined in a schema, the name of that type is attached as an annotation to the node, and determines the outcome of operations applied to that node: for example, when sorting, nodes that are annotated as integers will be sorted as integers.
Atomic values may belong to any of the 19 primitive types defined in the XML Schema specification (for example, string, boolean, double, float, decimal, dateTime, QName, and so on). They may also belong to a type derived from one of these primitive types: either a built-in derived type such as integer or Name, or a user-defined derived type defined in a user-written schema.
The type system of XPath 2.0 is noteworthy for the fact that it mixes strong typing and weak typing within a single language.
Operations such as arithmetic and boolean comparison require atomic values as their operands. If an operand returns a node (for example, @price * 1.2), then the node is automatically atomized to extract the atomic value. If the input document has been validated against a schema, then the node will typically have a type annotation, and this determines the type of the resulting atomic value (in this example, the price attribute might have the type decimal). If no schema is in use, the node will be untyped, and the type of the resulting atomic value will be untypedAtomic. Typed atomic values are checked to ensure that they have an appropriate type for the context where they are used: for example, it is not possible to multiply a date by a number. Untyped atomic values, by contrast, follow a weak typing discipline: they are automatically converted to a type appropriate to the operation where they are used: for example with an arithmetic operation an untyped atomic value is converted to the type double.
Path expressions
The location paths of XPath 1.0 are referred to in XPath 2.0 as path expressions. Informally, a path expression is a sequence of steps separated by the "/" operator, for example a/b/c (which is short for child::a/child::b/child::c). More formally, however, "/" is simply a binary operator that applies the expression on its right-hand side to each item in turn selected by the expression on the left hand side. So in this example, the expression a selects all the element children of the context node that are named <a>; the expression child::b is then applied to each of these nodes, selecting all the <b> children of the <a> elements; and the expression child::c is then applied to each node in this sequence, which selects all the <c> children of these <b> elements.
The "/" operator is generalized in XPath 2.0 to allow any kind of expression to be used as an operand: in XPath 1.0, the right-hand side was always an axis step. For example, a function call can be used on the right-hand side. The typing rules for the operator require that the result of the first operand is a sequence of nodes. The right hand operand can return either nodes or atomic values (but not a mixture). If the result consists of nodes, then duplicates are eliminated and the nodes are returned in document order, an ordering defined in terms of the relative positions of the nodes in the original XML tree.
In many cases the operands of "/" will be axis steps: these are largely unchanged from XPath 1.0, and are described in the article on XPath 1.0.
Other operators
Other operators available in XPath 2.0 include the following:
Operators
Effect
+, -, *, div, mod, idiv
Arithmetic on numbers, dates, and durations
=,!=, <, >, <=, >=
General comparison: compare arbitrary sequences. The result is true if any pair of items, one from each sequence, satisfies the comparison
eq, ne, lt, gt, le, ge
Value comparison: compare single items
is
Compare node identity: true if both operands are the same node
<<, >>
Compare node position, based on document order
union, intersect, except
Compare sequences of nodes, treating them as sets, returning the set union, intersection, or difference
and, or
boolean conjunction and disjunction. Negation is achieved using the not() function.
to
defines an integer range, for example 1 to 10
instance of
determines whether a value is an instance of a given type
cast as
converts a value to a given type
castable as
tests whether a value is convertible to a given type
Conditional expressions may be written using the syntax if (A) then B else C.
XPath 2.0 also offers a for expression, which is a small subset of the FLWOR expression from XQuery. The expression for$xinXreturnY evaluates the expression Y for each value in the result of expression X in turn, referring to that value using the variable reference $x.
Function library
The function library in XPath 2.0 is greatly extended from the function library in XPath 1.0. (Bold items are available in XPath 1.0)
Because of the changes in the data model and type system, not all expressions have exactly the same effect in XPath 2.0 as in 1.0. The main difference is that XPath 1.0 was more relaxed about type conversion, for example comparing two strings ("4" > "4.0") was quite possible but would do a numeric comparison; in XPath 2.0 this is defined to compare the two values as strings using a context-defined collating sequence.
To ease transition, XPath 2.0 defines a mode of execution in which the semantics are modified to be as close as possible to XPath 1.0 behavior. When using XSLT 2.0, this mode is activated by setting version="1.0" as an attribute on the xsl:stylesheet element. This still doesn't offer 100% compatibility, but any remaining differences are only likely to be encountered in unusual cases.
Support
This section needs expansion. You can help by adding to it. (December 2009)
Support for XPath 2.0 is still limited.
Related Research Articles
Extensible Markup Language (XML) is a markup language and file format for storing, transmitting, and reconstructing arbitrary data. It defines a set of rules for encoding documents in a format that is both human-readable and machine-readable. The World Wide Web Consortium's XML 1.0 Specification of 1998 and several other related specifications—all of them free open standards—define XML.
XSLT is a language originally designed for transforming XML documents into other XML documents, or other formats such as HTML for web pages, plain text or XSL Formatting Objects, which may subsequently be converted to other formats, such as PDF, PostScript and PNG. Support for JSON and plain-text transformation was added in later updates to the XSLT 1.0 specification.
XSD, a recommendation of the World Wide Web Consortium (W3C), specifies how to formally describe the elements in an Extensible Markup Language (XML) document. It can be used by programmers to verify each piece of item content in a document, to assure it adheres to the description of the element it is placed in.
Saxon is an XSLT and XQuery processor created by Michael Kay and now developed and maintained by his company, Saxonica. There are open-source and also closed-source commercial versions. Versions exist for Java, JavaScript and .NET.
An XML schema is a description of a type of XML document, typically expressed in terms of constraints on the structure and content of documents of that type, above and beyond the basic syntactical constraints imposed by XML itself. These constraints are generally expressed using some combination of grammatical rules governing the order of elements, Boolean predicates that the content must satisfy, data types governing the content of elements and attributes, and more specialized rules such as uniqueness and referential integrity constraints.
The identity transform is a data transformation that copies the source data into the destination data without change.
XML documents have a hierarchical structure and can conceptually be interpreted as a tree structure, called an XML tree.
The XQuery and XPath Data Model (XDM) is the data model shared by the XPath 2.0, XSLT 2.0, XQuery, and XForms programming languages. It is defined in a W3C recommendation. Originally, it was based on the XPath 1.0 data model which in turn is based on the XML Information Set.
The Oxygen XML Editor is a multi-platform XML editor, XSLT/XQuery debugger and profiler with Unicode support. It is a Java application so it can run in Windows, Mac OS X, and Linux. It also has a version that can run as an Eclipse plugin.
XProc is a W3C Recommendation to define an XML transformation language to define XML Pipelines.
XMLStarlet is a set of command line utilities (toolkit) to query, transform, validate, and edit XML documents and files using a simple set of shell commands in a way similar to how it is done with UNIX grep, sed, awk, diff, patch, join, etc commands.
XPath is an expression language designed to support the query or transformation of XML documents. It was defined by the World Wide Web Consortium (W3C) and can be used to compute values from the content of an XML document. Support for XPath exists in applications that support XML, such as web browsers, and many programming languages.
XQuery is a query and functional programming language that queries and transforms collections of structured and unstructured data, usually in the form of XML, text and with vendor-specific extensions for other data formats. The language is developed by the XML Query working group of the W3C. The work is closely coordinated with the development of XSLT by the XSL Working Group; the two groups share responsibility for XPath, which is a subset of XQuery.
A processing instruction (PI) is an SGML and XML node type, which may occur anywhere in a document, intended to carry instructions to the application.
XQuery API for Java (XQJ) refers to the common Java API for the W3C XQuery 1.0 specification.
An XML transformation language is a programming language designed specifically to transform an input XML document into an output document which satisfies some specific goal.
Zorba is an open source query processor written in C++, implementing
Stylus Studio is an integrated development environment (IDE) for the Extensible Markup Language (XML). It consists of a variety of tools and visual designers to edit and transform XML documents and legacy data such as electronic data interchange (EDI), comma-separated values (CSV) and relational data.
JSONiq is a query and functional programming language that is designed to declaratively query and transform collections of hierarchical and heterogeneous data in format of JSON, XML, as well as unstructured, textual data.
XPath 3 is the latest version of the XML Path Language, a query language for selecting nodes in XML documents. It supersedes XPath 1.0 and XPath 2.0.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.