While Hypertext Markup Language (HTML) has been in use since 1991, HTML 4.0 from December 1997 was the first standardized version where international characters were given reasonably complete treatment. When an HTML document includes special characters outside the range of seven-bit ASCII, two goals are worth considering: the information's integrity, and universal browser display.
A document type definition (DTD) is a set of markup declarations that define a document type for an SGML-family markup language.
The HyperText Markup Language or HTML is the standard markup language for documents designed to be displayed in a web browser. It can be assisted by technologies such as Cascading Style Sheets (CSS) and scripting languages such as JavaScript.
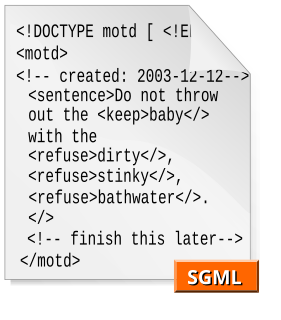
The Standard Generalized Markup Language is a standard for defining generalized markup languages for documents. ISO 8879 Annex A.1 states that generalized markup is "based on two postulates":
A Uniform Resource Identifier (URI) is a unique sequence of characters that identifies a logical or physical resource used by web technologies. URIs may be used to identify anything, including real-world objects, such as people and places, concepts, or information resources such as web pages and books. Some URIs provide a means of locating and retrieving information resources on a network ; these are Uniform Resource Locators (URLs). A URL provides the location of the resource. A URI identifies the resource by name at the specified location or URL. Other URIs provide only a unique name, without a means of locating or retrieving the resource or information about it, these are Uniform Resource Names (URNs). The web technologies that use URIs are not limited to web browsers. URIs are used to identify anything described using the Resource Description Framework (RDF), for example, concepts that are part of an ontology defined using the Web Ontology Language (OWL), and people who are described using the Friend of a Friend vocabulary would each have an individual URI.
Extensible Markup Language (XML) is a markup language and file format for storing, transmitting, and reconstructing arbitrary data. It defines a set of rules for encoding documents in a format that is both human-readable and machine-readable. The World Wide Web Consortium's XML 1.0 Specification of 1998 and several other related specifications—all of them free open standards—define XML.
DocBook is a semantic markup language for technical documentation. It was originally intended for writing technical documents related to computer hardware and software, but it can be used for any other sort of documentation.
Mathematical Markup Language (MathML) is a mathematical markup language, an application of XML for describing mathematical notations and capturing both its structure and content. It aims at integrating mathematical formulae into World Wide Web pages and other documents. It is part of HTML5 and is a ISO/IEC standard ISO/IEC 40314 since 2015.
XSD, a recommendation of the World Wide Web Consortium (W3C), specifies how to formally describe the elements in an Extensible Markup Language (XML) document. It can be used by programmers to verify each piece of item content in a document, to assure it adheres to the description of the element it is placed in.
YAML is a human-readable data-serialization language. It is commonly used for configuration files and in applications where data is being stored or transmitted. YAML targets many of the same communications applications as Extensible Markup Language (XML) but has a minimal syntax which intentionally differs from SGML. It uses both Python-style indentation to indicate nesting, and a more compact format that uses [...] for lists and {...} for maps thus JSON files are valid YAML 1.2.
XML Linking Language, or XLink, is an XML markup language and W3C specification that provides methods for creating internal and external links within XML documents, and associating metadata with those links.
XML Signature defines an XML syntax for digital signatures and is defined in the W3C recommendation XML Signature Syntax and Processing. Functionally, it has much in common with PKCS #7 but is more extensible and geared towards signing XML documents. It is used by various Web technologies such as SOAP, SAML, and others.
An XML schema is a description of a type of XML document, typically expressed in terms of constraints on the structure and content of documents of that type, above and beyond the basic syntactical constraints imposed by XML itself. These constraints are generally expressed using some combination of grammatical rules governing the order of elements, Boolean predicates that the content must satisfy, data types governing the content of elements and attributes, and more specialized rules such as uniqueness and referential integrity constraints.
In computer science, canonicalization is a process for converting data that has more than one possible representation into a "standard", "normal", or canonical form. This can be done to compare different representations for equivalence, to count the number of distinct data structures, to improve the efficiency of various algorithms by eliminating repeated calculations, or to make it possible to impose a meaningful sorting order.
In computer programming, whitespace is any character or series of characters that represent horizontal or vertical space in typography. When rendered, a whitespace character does not correspond to a visible mark, but typically does occupy an area on a page. For example, the common whitespace symbol U+0020 SPACE represents a blank space punctuation character in text, used as a word divider in Western scripts.
XML documents have a hierarchical structure and can conceptually be interpreted as a tree structure, called an XML tree.
A Canonical S-expression is a binary encoding form of a subset of general S-expression. It was designed for use in SPKI to retain the power of S-expressions and ensure canonical form for applications such as digital signatures while achieving the compactness of a binary form and maximizing the speed of parsing.
Extensible HyperText Markup Language (XHTML) is part of the family of XML markup languages. It mirrors or extends versions of the widely used HyperText Markup Language (HTML), the language in which Web pages are formulated.
XPath is an expression language designed to support the query or transformation of XML documents. It was defined by the World Wide Web Consortium (W3C) and can be used to compute values from the content of an XML document. Support for XPath exists in applications that support XML, such as web browsers, and many programming languages.
In computing, a polyglot markup is a document or script written in a valid form of multiple markup languages, which performs the same output, independent of the markup's parser, layout engine, or interpreter. In general, the polyglot markup is a common subset of two or more languages, that can be used as a robust or simplified profile.