| 1. | Sampling mechanism. It consists of a pair  , where the seed Z is a random variable without unknown parameters, while the explaining function , where the seed Z is a random variable without unknown parameters, while the explaining function  is a function mapping from samples of Z to samples of the random variable X we are interested in. The parameter vector is a function mapping from samples of Z to samples of the random variable X we are interested in. The parameter vector  is a specification of the random parameter is a specification of the random parameter  . Its components are the parameters of the X distribution law. The Integral Transform Theorem ensures the existence of such a mechanism for each (scalar or vector) X when the seed coincides with the random variable U uniformly distributed in . Its components are the parameters of the X distribution law. The Integral Transform Theorem ensures the existence of such a mechanism for each (scalar or vector) X when the seed coincides with the random variable U uniformly distributed in  . . | Example. | For X following a Pareto distribution with parameters a and k, i.e. 
a sampling mechanism  for X with seed U reads: for X with seed U reads: 
or, equivalently,  |
|
| 2. | Master equations. The actual connection between the model and the observed data is tossed in terms of a set of relations between statistics on the data and unknown parameters that come as a corollary of the sampling mechanisms. We call these relations master equations. Pivoting around the statistic  , the general form of a master equation is: , the general form of a master equation is:  . .
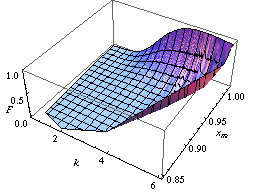
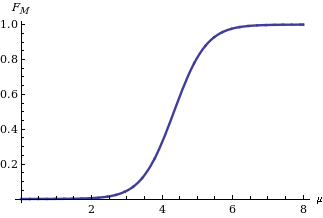
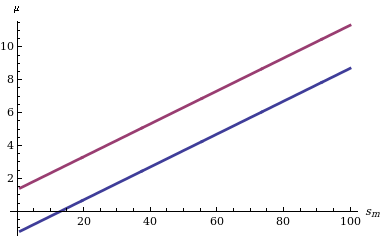
With these relations we may inspect the values of the parameters that could have generated a sample with the observed statistic from a particular setting of the seeds representing the seed of the sample. Hence, to the population of sample seeds corresponds a population of parameters. In order to ensure this population clean properties, it is enough to draw randomly the seed values and involve either sufficient statistics or, simply, well-behaved statistics w.r.t. the parameters, in the master equations. For example, the statistics  and and  prove to be sufficient for parameters a and k of a Pareto random variable X. Thanks to the (equivalent form of the) sampling mechanism prove to be sufficient for parameters a and k of a Pareto random variable X. Thanks to the (equivalent form of the) sampling mechanism  we may read them as we may read them as  
respectively. |
| 3. | Parameter population. Having fixed a set of master equations, you may map sample seeds into parameters either numerically through a population bootstrap, or analytically through a twisting argument. Hence from a population of seeds you obtain a population of parameters. Compatibility denotes parameters of compatible populations, i.e. of populations that could have generated a sample giving rise to the observed statistics. You may formalize this notion as follows: |