
In particle physics, Rutherford scattering is the elastic scattering of charged particles by the Coulomb interaction. It is a physical phenomenon explained by Ernest Rutherford in 1911 that led to the development of the planetary Rutherford model of the atom and eventually the Bohr model. Rutherford scattering was first referred to as Coulomb scattering because it relies only upon the static electric (Coulomb) potential, and the minimum distance between particles is set entirely by this potential. The classical Rutherford scattering process of alpha particles against gold nuclei is an example of "elastic scattering" because neither the alpha particles nor the gold nuclei are internally excited. The Rutherford formula further neglects the recoil kinetic energy of the massive target nucleus.
Big O notation is a mathematical notation that describes the limiting behavior of a function when the argument tends towards a particular value or infinity. Big O is a member of a family of notations invented by German mathematicians Paul Bachmann, Edmund Landau, and others, collectively called Bachmann–Landau notation or asymptotic notation. The letter O was chosen by Bachmann to stand for Ordnung, meaning the order of approximation.
In statistics, the Lehmann–Scheffé theorem is a prominent statement, tying together the ideas of completeness, sufficiency, uniqueness, and best unbiased estimation. The theorem states that any estimator that is unbiased for a given unknown quantity and that depends on the data only through a complete, sufficient statistic is the unique best unbiased estimator of that quantity. The Lehmann–Scheffé theorem is named after Erich Leo Lehmann and Henry Scheffé, given their two early papers.
A randomized algorithm is an algorithm that employs a degree of randomness as part of its logic or procedure. The algorithm typically uses uniformly random bits as an auxiliary input to guide its behavior, in the hope of achieving good performance in the "average case" over all possible choices of random determined by the random bits; thus either the running time, or the output are random variables.
In physics, circular motion is a movement of an object along the circumference of a circle or rotation along a circular arc. It can be uniform, with a constant rate of rotation and constant tangential speed, or non-uniform with a changing rate of rotation. The rotation around a fixed axis of a three-dimensional body involves the circular motion of its parts. The equations of motion describe the movement of the center of mass of a body, which remains at a constant distance from the axis of rotation. In circular motion, the distance between the body and a fixed point on its surface remains the same, i.e., the body is assumed rigid.
In mathematical statistics, the Fisher information is a way of measuring the amount of information that an observable random variable X carries about an unknown parameter θ of a distribution that models X. Formally, it is the variance of the score, or the expected value of the observed information.
In mathematics, a Sobolev space is a vector space of functions equipped with a norm that is a combination of Lp-norms of the function together with its derivatives up to a given order. The derivatives are understood in a suitable weak sense to make the space complete, i.e. a Banach space. Intuitively, a Sobolev space is a space of functions possessing sufficiently many derivatives for some application domain, such as partial differential equations, and equipped with a norm that measures both the size and regularity of a function.
In computer science, a disjoint-set data structure, also called a union–find data structure or merge–find set, is a data structure that stores a collection of disjoint (non-overlapping) sets. Equivalently, it stores a partition of a set into disjoint subsets. It provides operations for adding new sets, merging sets, and finding a representative member of a set. The last operation makes it possible to find out efficiently if any two elements are in the same or different sets.

The Schönhage–Strassen algorithm is an asymptotically fast multiplication algorithm for large integers, published by Arnold Schönhage and Volker Strassen in 1971. It works by recursively applying fast Fourier transform (FFT) over the integers modulo 2n+1. The run-time bit complexity to multiply two n-digit numbers using the algorithm is in big O notation.
In statistics a minimum-variance unbiased estimator (MVUE) or uniformly minimum-variance unbiased estimator (UMVUE) is an unbiased estimator that has lower variance than any other unbiased estimator for all possible values of the parameter.
In statistics, the score test assesses constraints on statistical parameters based on the gradient of the likelihood function—known as the score—evaluated at the hypothesized parameter value under the null hypothesis. Intuitively, if the restricted estimator is near the maximum of the likelihood function, the score should not differ from zero by more than sampling error. While the finite sample distributions of score tests are generally unknown, they have an asymptotic χ2-distribution under the null hypothesis as first proved by C. R. Rao in 1948, a fact that can be used to determine statistical significance.
In statistics, the Bayesian information criterion (BIC) or Schwarz information criterion is a criterion for model selection among a finite set of models; models with lower BIC are generally preferred. It is based, in part, on the likelihood function and it is closely related to the Akaike information criterion (AIC).

In mathematics, the axis–angle representation parameterizes a rotation in a three-dimensional Euclidean space by two quantities: a unit vector e indicating the direction (geometry) of an axis of rotation, and an angle of rotation θ describing the magnitude and sense of the rotation about the axis. Only two numbers, not three, are needed to define the direction of a unit vector e rooted at the origin because the magnitude of e is constrained. For example, the elevation and azimuth angles of e suffice to locate it in any particular Cartesian coordinate frame.

A two-dimensional elastic membrane under tension can support transverse vibrations. The properties of an idealized drumhead can be modeled by the vibrations of a circular membrane of uniform thickness, attached to a rigid frame. Due to the phenomenon of resonance, at certain vibration frequencies, its resonant frequencies, the membrane can store vibrational energy, the surface moving in a characteristic pattern of standing waves. This is called a normal mode. A membrane has an infinite number of these normal modes, starting with a lowest frequency one called the fundamental mode.

In mathematics, potential flow around a circular cylinder is a classical solution for the flow of an inviscid, incompressible fluid around a cylinder that is transverse to the flow. Far from the cylinder, the flow is unidirectional and uniform. The flow has no vorticity and thus the velocity field is irrotational and can be modeled as a potential flow. Unlike a real fluid, this solution indicates a net zero drag on the body, a result known as d'Alembert's paradox.
In quantum computing, the quantum phase estimation algorithm is a quantum algorithm to estimate the phase corresponding to an eigenvalue of a given unitary operator. Because the eigenvalues of a unitary operator always have unit modulus, they are characterized by their phase, and therefore the algorithm can be equivalently described as retrieving either the phase or the eigenvalue itself. The algorithm was initially introduced by Alexei Kitaev in 1995.
In coding theory, generalized minimum-distance (GMD) decoding provides an efficient algorithm for decoding concatenated codes, which is based on using an errors-and-erasures decoder for the outer code.
Matrix completion is the task of filling in the missing entries of a partially observed matrix, which is equivalent to performing data imputation in statistics. A wide range of datasets are naturally organized in matrix form. One example is the movie-ratings matrix, as appears in the Netflix problem: Given a ratings matrix in which each entry represents the rating of movie by customer , if customer has watched movie and is otherwise missing, we would like to predict the remaining entries in order to make good recommendations to customers on what to watch next. Another example is the document-term matrix: The frequencies of words used in a collection of documents can be represented as a matrix, where each entry corresponds to the number of times the associated term appears in the indicated document.
In mathematics, and in particular in mathematical analysis, the Gagliardo–Nirenberg interpolation inequality is a result in the theory of Sobolev spaces that relates the -norms of different weak derivatives of a function through an interpolation inequality. The theorem is of particular importance in the framework of elliptic partial differential equations and was originally formulated by Emilio Gagliardo and Louis Nirenberg in 1958. The Gagliardo-Nirenberg inequality has found numerous applications in the investigation of nonlinear partial differential equations, and has been generalized to fractional Sobolev spaces by Haim Brezis and Petru Mironescu in the late 2010s.
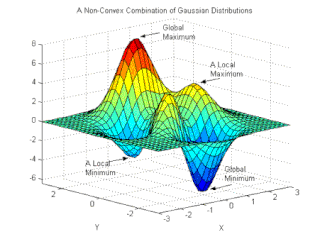
Stochastic gradient Langevin dynamics (SGLD) is an optimization and sampling technique composed of characteristics from Stochastic gradient descent, a Robbins–Monro optimization algorithm, and Langevin dynamics, a mathematical extension of molecular dynamics models. Like stochastic gradient descent, SGLD is an iterative optimization algorithm which uses minibatching to create a stochastic gradient estimator, as used in SGD to optimize a differentiable objective function. Unlike traditional SGD, SGLD can be used for Bayesian learning as a sampling method. SGLD may be viewed as Langevin dynamics applied to posterior distributions, but the key difference is that the likelihood gradient terms are minibatched, like in SGD. SGLD, like Langevin dynamics, produces samples from a posterior distribution of parameters based on available data. First described by Welling and Teh in 2011, the method has applications in many contexts which require optimization, and is most notably applied in machine learning problems.





















