
Parallel computing is a type of computation in which many calculations or the execution of processes are carried out simultaneously. Large problems can often be divided into smaller ones, which can then be solved at the same time. There are several different forms of parallel computing: bit-level, instruction-level, data, and task parallelism. Parallelism has long been employed in high-performance computing, but it's gaining broader interest due to the physical constraints preventing frequency scaling. As power consumption by computers has become a concern in recent years, parallel computing has become the dominant paradigm in computer architecture, mainly in the form of multi-core processors.

OpenMP is an application programming interface (API) that supports multi-platform shared memory multiprocessing programming in C, C++, and Fortran, on most platforms, instruction set architectures and operating systems, including Solaris, AIX, HP-UX, Linux, macOS, and Windows. It consists of a set of compiler directives, library routines, and environment variables that influence run-time behavior.
In computing, hardware acceleration is the use of computer hardware specially made to perform some functions more efficiently than is possible in software running on a general-purpose CPU. Any transformation of data or routine that can be computed, can be calculated purely in software running on a generic CPU, purely in custom-made hardware, or in some mix of both. An operation can be computed faster in application-specific hardware designed or programmed to compute the operation than specified in software and performed on a general-purpose computer processor. Each approach has advantages and disadvantages. The implementation of computing tasks in hardware to decrease latency and increase throughput is known as hardware acceleration.
Automatic parallelization, also auto parallelization, autoparallelization, or parallelization, the last one of which implies automation when used in context, refers to converting sequential code into multi-threaded or vectorized code in order to utilize multiple processors simultaneously in a shared-memory multiprocessor (SMP) machine. The goal of automatic parallelization is to relieve programmers from the hectic and error-prone manual parallelization process. Though the quality of automatic parallelization has improved in the past several decades, fully automatic parallelization of sequential programs by compilers remains a grand challenge due to its need for complex program analysis and the unknown factors during compilation.
Intel C++ Compiler, also known as icc or icl, is a group of C and C++ compilers from Intel available for Windows, Mac, Linux, FreeBSD and Intel-based Android devices.

Data parallelism is parallelization across multiple processors in parallel computing environments. It focuses on distributing the data across different nodes, which operate on the data in parallel. It can be applied on regular data structures like arrays and matrices by working on each element in parallel. It contrasts to task parallelism as another form of parallelism.
Task parallelism is a form of parallelization of computer code across multiple processors in parallel computing environments. Task parallelism focuses on distributing tasks—concurrently performed by processes or threads—across different processors. In contrast to data parallelism which involves running the same task on different components of data, task parallelism is distinguished by running many different tasks at the same time on the same data. A common type of task parallelism is pipelining which consists of moving a single set of data through a series of separate tasks where each task can execute independently of the others.
RapidMind Inc. was a privately held company founded and headquartered in Waterloo, Ontario, Canada, acquired by Intel in 2009. It provided a software product that aims to make it simpler for software developers to target multi-core processors and accelerators such as graphics processing units (GPUs).
The Sieve C++ Parallel Programming System is a C++ compiler and parallel runtime designed and released by Codeplay that aims to simplify the parallelization of code so that it may run efficiently on multi-processor or multi-core systems. It is an alternative to other well-known parallelisation methods such as OpenMP, the RapidMind Development Platform and Threading Building Blocks (TBB).

Parallel Extensions was the development name for a managed concurrency library developed by a collaboration between Microsoft Research and the CLR team at Microsoft. The library was released in version 4.0 of the .NET Framework. It is composed of two parts: Parallel LINQ (PLINQ) and Task Parallel Library (TPL). It also consists of a set of coordination data structures (CDS) – sets of data structures used to synchronize and co-ordinate the execution of concurrent tasks.
Intel Parallel Studio XE is a software development product developed by Intel that facilitates native code development on Windows, macOS and Linux in C++ and Fortran for parallel computing. Parallel programming enables software programs to take advantage of multi-core processors from Intel and other processor vendors.
Concurrent Collections is a programming model for software frameworks to expose parallelism in applications. The Concurrent Collections conception originated from tagged stream processing development with HP TStreams.
Software is said to exhibit scalable parallelism if it can make use of additional processors to solve larger problems, i.e. this term refers to software for which Gustafson's law holds. Consider a program whose execution time is dominated by one or more loops, each of that updates every element of an array --- for example, the following finite difference heat equation stencil calculation:
for t := 0 to T dofor i := 1 to N-1 do new(i) := * .25 // explicit forward-difference with R = 0.25 endfor i := 1 to N-1 do A(i) := new(i) endend
The following outline is provided as an overview of and topical guide to C++:
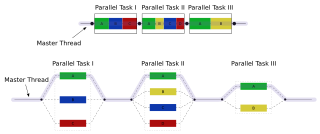
In parallel computing, the fork–join model is a way of setting up and executing parallel programs, such that execution branches off in parallel at designated points in the program, to "join" (merge) at a subsequent point and resume sequential execution. Parallel sections may fork recursively until a certain task granularity is reached. Fork–join can be considered a parallel design pattern. It was formulated as early as 1963.
