Protein YIF1A is a Yip1 domain family proteins that in humans is encoded by the YIF1A gene.

UPF0687 protein C20orf27 is a protein that in humans is encoded by the C20orf27 gene. It is expressed in the majority of the human tissues. One study on this protein revealed its role in regulating cell cycle, apoptosis, and tumorigenesis via promoting the activation of NFĸB pathway.

C8orf48 is a protein that in humans is encoded by the C8orf48 gene. C8orf48 is a nuclear protein specifically predicted to be located in the nuclear lamina. C8orf48 has been found to interact with proteins that are involved in the regulation of various cellular responses like gene expression, protein secretion, cell proliferation, and inflammatory responses. This protein has been linked to breast cancer and papillary thyroid carcinoma.

Uncharacterized protein C2orf73 is a protein that in humans is encoded by the C2orf73 gene. The protein is predicted to be localized to the nucleus.

Transmembrane protein 255A is a protein that is encoded by the TMEM255A gene. TMEM255A is often referred to as family with sequence similarity 70, member A (FAM70A). The TMEM255A protein is transmembrane and is predicted to be located the nuclear envelope of eukaryote organisms.
Proline-rich protein 30 is a protein in humans that is encoded for by the PRR30 gene. PRR30 is a member in the family of Proline-rich proteins characterized by their intrinsic lack of structure. Copy number variations in the PRR30 gene have been associated with an increased risk for neurofibromatosis.

C16orf82 is a protein that, in humans, is encoded by the C16orf82 gene. C16orf82 encodes a 2285 nucleotide mRNA transcript which is translated into a 154 amino acid protein using a non-AUG (CUG) start codon. The gene has been shown to be largely expressed in the testis, tibial nerve, and the pituitary gland, although expression has been seen throughout a majority of tissue types. The function of C16orf82 is not fully understood by the scientific community.
SHLD1 or shieldin complex subunit 1 is a gene on chromosome 20. The C20orf196 gene encodes an mRNA that is 1,763 base pairs long, and a protein that is 205 amino acids long.
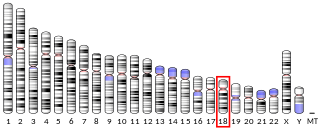
Chromosome 18 open reading frame 63 is a protein which in humans is encoded by the C18orf63 gene. This protein is not yet well understood by the scientific community. Research has been conducted suggesting that C18orf63 could be a potential biomarker for early stage pancreatic cancer and breast cancer.

Chromosome 1 open reading frame 112, is a protein that in humans is encoded by the C1orf112 gene, and is located at position 1q24.2. C1orf112 encodes for seventeen variants of mRNA, fifteen of which are functional proteins. C1orf112 has a determined precursor molecular weight of 96.6 kDa and an isoelectric point of 5.62. C1orf112 has been experimentally determined to localize to the mitochondria, although it does not contain a mitochondrial targeting sequence.
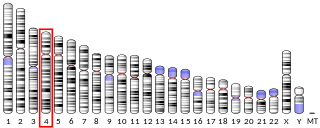
Cilia- and flagella-associated protein 299 (CFAP299) is a protein that in humans is encoded by the CFAP299 gene. CFAP299 is predicted to play a role in spermatogenesis and cell apoptosis.
C2orf16 is a protein that in humans is encoded by the C2orf16 gene. Isoform 2 of this protein is 1,984 amino acids long. The gene contains 1 exon and is located at 2p23.3. Aliases for C2orf16 include Open Reading Frame 16 on Chromosome 2 and P-S-E-R-S-H-H-S Repeats Containing Sequence.

C7orf50 is a gene in humans that encodes a protein known as C7orf50. This gene is ubiquitously expressed in the kidneys, brain, fat, prostate, spleen, among 22 other tissues and demonstrates low tissue specificity. C7orf50 is conserved in chimpanzees, Rhesus monkeys, dogs, cows, mice, rats, and chickens, along with 307 other organisms from mammals to fungi. This protein is predicted to be involved with the import of ribosomal proteins into the nucleus to be assembled into ribosomal subunits as a part of rRNA processing. Additionally, this gene is predicted to be a microRNA (miRNA) protein coding host gene, meaning that it may contain miRNA genes in its introns and/or exons.
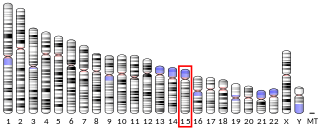
In humans, the immunoglobulin super family containing leucine-rich repeat (ISLR) protein is encoded by the ISLR gene. Current RNA-seq studies show that the protein is highly expressed in the endometrium and ovary and shows expression among 25 other tissues. The protein is seen localized in the cytoplasm, plasma membrane, extracellular exosome, and platelet alpha granule lumen. Furthermore, the protein is known to play a role in platelet degranulation, cell adhesion, and response to elevated platelet cytosolic Ca2+.
Serum amyloid A-like 1 is a protein in humans encoded by the SAAL1 gene.

OCEL1, also called Occludin//ELL Domain Containing 1, is a protein encoding gene located at chromosome 19p13.11 in the human genome. Other aliases for the gene include FLJ22709, FWP009, and S863-9. The function of OCEL1 has not yet been identified.
Family with sequence 98, member C or FAM98C is a gene that encodes for FAM98C has two aliases FLJ44669 and hypothetical protein LOC147965. FAM98C has two paralogs in humans FAM98A and FAM98B. FAM98C can be characterized for being a Leucine-rich protein. The function of FAM98C is still not defined. FAM98C has orthologs in mammals, reptiles, and amphibians and has a distant orhtologs in Rhinatrema bivittatum and Nanorana parkeri.
Solute carrier family 66 member 3 is a gene in humans that encodes the protein SLC66A3. The function of the SLC66A3 protein is not yet well understood but belongs to a family of five evolutionarily related proteins, the SLC66 lysosomal amino acid transporters. SLC66A3 is localized to the endoplasmic reticulum and has four transmembrane domains.

CCDC188 or coiled-coil domain containing protein is a protein that in humans is encoded by the CCDC188 gene.

C13orf42 is a protein which, in humans, is encoded by the gene chromosome 13 open reading frame 42 (C13orf42). RNA sequencing data shows low expression of the C13orf42 gene in a variety of tissues. The C13orf42 protein is predicted to be localized in the mitochondria, nucleus, and cytosol. Tertiary structure predictions for C13orf42 indicate multiple alpha helices.