Related Research Articles

A supercomputer is a computer with a high level of performance as compared to a general-purpose computer. The performance of a supercomputer is commonly measured in floating-point operations per second (FLOPS) instead of million instructions per second (MIPS). Since 2017, there have existed supercomputers which can perform over 1017 FLOPS (a hundred quadrillion FLOPS, 100 petaFLOPS or 100 PFLOPS). For comparison, a desktop computer has performance in the range of hundreds of gigaFLOPS (1011) to tens of teraFLOPS (1013). Since November 2017, all of the world's fastest 500 supercomputers run on Linux-based operating systems. Additional research is being conducted in the United States, the European Union, Taiwan, Japan, and China to build faster, more powerful and technologically superior exascale supercomputers.
UNICOS is a range of Unix and after it Linux operating system (OS) variants developed by Cray for its supercomputers. UNICOS is the successor of the Cray Operating System (COS). It provides network clustering and source code compatibility layers for some other Unixes. UNICOS was originally introduced in 1985 with the Cray-2 system and later ported to other Cray models. The original UNICOS was based on UNIX System V Release 2, and had many Berkeley Software Distribution (BSD) features added to it.

A Beowulf cluster is a computer cluster of what are normally identical, commodity-grade computers networked into a small local area network with libraries and programs installed which allow processing to be shared among them. The result is a high-performance parallel computing cluster from inexpensive personal computer hardware.
Cray Inc., a subsidiary of Hewlett Packard Enterprise, is an American supercomputer manufacturer headquartered in Seattle, Washington. It also manufactures systems for data storage and analytics. Several Cray supercomputer systems are listed in the TOP500, which ranks the most powerful supercomputers in the world.

ASCI Red was the first computer built under the Accelerated Strategic Computing Initiative (ASCI), the supercomputing initiative of the United States government created to help the maintenance of the United States nuclear arsenal after the 1992 moratorium on nuclear testing.
SUNMOS is an operating system jointly developed by Sandia National Laboratories and the Computer Science Department at the University of New Mexico. The goal of the project, started in 1991, is to develop a highly portable, yet efficient, operating system for massively parallel-distributed memory systems.

EPCC, formerly the Edinburgh Parallel Computing Centre, is a supercomputing centre based at the University of Edinburgh. Since its foundation in 1990, its stated mission has been to accelerate the effective exploitation of novel computing throughout industry, academia and commerce.
Red Storm is a supercomputer architecture designed for the US Department of Energy’s National Nuclear Security Administration Advanced Simulation and Computing Program. Cray, Inc developed it based on the contracted architectural specifications provided by Sandia National Laboratories. The architecture was later commercially produced as the Cray XT3.

The Cray XT3 is a distributed memory massively parallel MIMD supercomputer designed by Cray Inc. with Sandia National Laboratories under the codename Red Storm. Cray turned the design into a commercial product in 2004. The XT3 derives much of its architecture from the previous Cray T3E system, and also from the Intel ASCI Red supercomputer.

Cray XMT is a scalable multithreaded shared memory supercomputer architecture by Cray, based on the third generation of the Tera MTA architecture, targeted at large graph problems. Presented in 2005, it supersedes the earlier unsuccessful Cray MTA-2. It uses the Threadstorm3 CPUs inside Cray XT3 blades. Designed to make use of commodity parts and existing subsystems for other commercial systems, it alleviated the shortcomings of Cray MTA-2's high cost of fully custom manufacture and support. It brought various substantial improvements over Cray MTA-2, most notably nearly tripling the peak performance, and vastly increased maximum CPU count to 8,192 and maximum memory to 128 TB, with a data TLB of maximal 512 TB.

The Cray XT5 is an updated version of the Cray XT4 supercomputer, launched on November 6, 2007. It includes a faster version of the XT4's SeaStar2 interconnect router called SeaStar2+, and can be configured either with XT4 compute blades, which have four dual-core AMD Opteron processor sockets, or XT5 blades, with eight sockets supporting dual or quad-core Opterons. The XT5 uses a 3-dimensional torus network topology.
The Cray CX1 is a deskside workstation designed by Cray Inc., based on the x86-64 processor architecture. It was launched on September 16, 2008, and was discontinued in early 2012. It comprises a single chassis blade server design that supports a maximum of eight modular single-width blades, giving up to 96 processor cores. Computational load can be run independently on each blade and/or combined using clustering techniques.
Compute Node Linux (CNL) is a runtime environment based on the Linux kernel for the Cray XT3, Cray XT4, Cray XT5, Cray XT6, Cray XE6 and Cray XK6 supercomputer systems based on SUSE Linux Enterprise Server. CNL forms part of the Cray Linux Environment. As of November 2011 systems running CNL were ranked 3rd, 6th and 8th among the fastest supercomputers in the world.
Jaguar or OLCF-2 was a petascale supercomputer built by Cray at Oak Ridge National Laboratory (ORNL) in Oak Ridge, Tennessee. The massively parallel Jaguar had a peak performance of just over 1,750 teraFLOPS. It had 224,256 x86-based AMD Opteron processor cores, and operated with a version of Linux called the Cray Linux Environment. Jaguar was a Cray XT5 system, a development from the Cray XT4 supercomputer.
Portals is a low-level network API for high-performance networking on high-performance computing systems developed by Sandia National Laboratories and the University of New Mexico. Portals is currently the lowest-level network programming interface on the commercially successful XT line of supercomputers from Cray.
The Cray XT6 is an updated version of the Cray XT5 supercomputer, launched on 16 November 2009. The dual- or quad-core AMD Opteron 2000-series processors of the XT5 are replaced in the XT6 with eight- or 12-core Opteron 6100 processors, giving up to 2,304 cores per cabinet. The XT6 includes the same SeaStar2+ interconnect router as the XT5, which is used to provide a 3-dimensional torus network topology between nodes. Each XT6 node has two processor sockets, one SeaStar2+ router and either 32 or 64 GB of DDR3 SDRAM memory. Four nodes form one X6 compute blade.
The Slurm Workload Manager, formerly known as Simple Linux Utility for Resource Management (SLURM), or simply Slurm, is a free and open-source job scheduler for Linux and Unix-like kernels, used by many of the world's supercomputers and computer clusters.

Compute Node Kernel (CNK) is the node level operating system for the IBM Blue Gene series of supercomputers.
Catamount is an operating system for supercomputers.
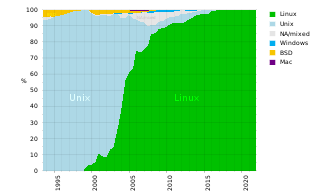
A supercomputer operating system is an operating system intended for supercomputers. Since the end of the 20th century, supercomputer operating systems have undergone major transformations, as fundamental changes have occurred in supercomputer architecture. While early operating systems were custom tailored to each supercomputer to gain speed, the trend has been moving away from in-house operating systems and toward some form of Linux, with it running all the supercomputers on the TOP500 list in November 2017. In 2021, top 10 computers run for instance Red Hat Enterprise Linux (RHEL), or some variant of it or other Linux distribution e.g. Ubuntu.
References
- ↑ Moreira, Jose; et al. (November 2006). "Designing a Highly-Scalable Operating System: The Blue Gene/L Story". Proceedings of the 2006 ACM/IEEE International Conference for High-Performance Computing, Networking, Storage, and Analysis (SC’06).
{{cite journal}}: Cite journal requires|journal=(help) - ↑ Wallace, D. (May 2007). "Compute Node Linux: Overview, progress to date, and roadmap". Proceedings of the 2007 Cray User Group Annual Technical Conference.
{{cite journal}}: Cite journal requires|journal=(help) - ↑ Riesen, Rolf; et al. (April 2009). "Designing and Implementing Lightweight Kernels for Capability Computing". Concurrency and Computation: Practice and Experience.
{{cite journal}}: Cite journal requires|journal=(help) - ↑ "Kitten Lightweight Kernel".
- ↑ Riesen, Rolf; et al. (June 2015). "What is a Lightweight Kernel?". Proceedings of the 5th International Workshop on Runtime and Operating Systems for Supercomputers. pp. 1–8. doi:10.1145/2768405.2768414. ISBN 9781450336062. S2CID 11698915 . Retrieved 19 October 2019.
- ↑ Kelly, S.; Brightwell, R. (May 2005). "Software Architecture of the Light Weight Kernel, Catamount". Proceedings of the 2005 Cray User Group Annual Technical Conference.
{{cite journal}}: Cite journal requires|journal=(help)