External links
- iHOP-Protein Information Database
- NextBio-Life Science Search Engine
- Entrez-Cross Database Query Search System
- TranscriptomeBrowser
This article includes a biology-related list of lists.
Lists of human genes are as follows:
Human chromosomes, each of which contains an incomplete list of genes located on that chromosome, are as follows:
The lists below constitute a complete list of all known human protein-coding genes:
1639 genes which encode proteins that are known or expected to function as human transcription factors:

In genetics, a promoter is a sequence of DNA to which proteins bind to initiate transcription of a single RNA transcript from the DNA downstream of the promoter. The RNA transcript may encode a protein (mRNA), or can have a function in and of itself, such as tRNA or rRNA. Promoters are located near the transcription start sites of genes, upstream on the DNA . Promoters can be about 100–1000 base pairs long, the sequence of which is highly dependent on the gene and product of transcription, type or class of RNA polymerase recruited to the site, and species of organism.

The human genome is a complete set of nucleic acid sequences for humans, encoded as DNA within the 23 chromosome pairs in cell nuclei and in a small DNA molecule found within individual mitochondria. These are usually treated separately as the nuclear genome and the mitochondrial genome. Human genomes include both protein-coding DNA sequences and various types of DNA that does not encode proteins. The latter is a diverse category that includes DNA coding for non-translated RNA, such as that for ribosomal RNA, transfer RNA, ribozymes, small nuclear RNAs, and several types of regulatory RNAs. It also includes promoters and their associated gene-regulatory elements, DNA playing structural and replicatory roles, such as scaffolding regions, telomeres, centromeres, and origins of replication, plus large numbers of transposable elements, inserted viral DNA, non-functional pseudogenes and simple, highly repetitive sequences. Introns make up a large percentage of non-coding DNA. Some of this non-coding DNA is non-functional junk DNA, such as pseudogenes, but there is no firm consensus on the total amount of junk DNA.
Non-coding DNA (ncDNA) sequences are components of an organism's DNA that do not encode protein sequences. Some non-coding DNA is transcribed into functional non-coding RNA molecules. Other functional regions of the non-coding DNA fraction include regulatory sequences that control gene expression; scaffold attachment regions; origins of DNA replication; centromeres; and telomeres. Some non-coding regions appear to be mostly nonfunctional such as introns, pseudogenes, intergenic DNA, and fragments of transposons and viruses.
Junk DNA is a DNA sequence that has no relevant biological function. Most organisms have some junk DNA in their genomes - mostly pseudogenes and fragments of transposons and viruses - but it is possible that some organisms have substantial amounts of junk DNA.

Transcription is the process of copying a segment of DNA into RNA. The segments of DNA transcribed into RNA molecules that can encode proteins are said to produce messenger RNA (mRNA). Other segments of DNA are copied into RNA molecules called non-coding RNAs (ncRNAs). mRNA comprises only 1–3% of total RNA samples. Less than 2% of the human genome can be transcribed into mRNA, while at least 80% of mammalian genomic DNA can be actively transcribed, with the majority of this 80% considered to be ncRNA.

Pseudogenes are nonfunctional segments of DNA that resemble functional genes. Most arise as superfluous copies of functional genes, either directly by gene duplication or indirectly by reverse transcription of an mRNA transcript. Pseudogenes are usually identified when genome sequence analysis finds gene-like sequences that lack regulatory sequences needed for transcription or translation, or whose coding sequences are obviously defective due to frameshifts or premature stop codons. Pseudogenes are a type of junk DNA.

A gene family is a set of several similar genes, formed by duplication of a single original gene, and generally with similar biochemical functions. One such family are the genes for human hemoglobin subunits; the ten genes are in two clusters on different chromosomes, called the α-globin and β-globin loci. These two gene clusters are thought to have arisen as a result of a precursor gene being duplicated approximately 500 million years ago.
In computational biology, gene prediction or gene finding refers to the process of identifying the regions of genomic DNA that encode genes. This includes protein-coding genes as well as RNA genes, but may also include prediction of other functional elements such as regulatory regions. Gene finding is one of the first and most important steps in understanding the genome of a species once it has been sequenced.
An intergenic region is a stretch of DNA sequences located between genes. Intergenic regions may contain functional elements and junk DNA. Intergenic regions should not be confused with intragenic regions, which are non-coding regions that are found within genes, especially within the genes of eukaryotic organisms.
The Encyclopedia of DNA Elements (ENCODE) is a public research project which aims "to build a comprehensive parts list of functional elements in the human genome."
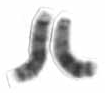
Chromosome 13 is one of the 23 pairs of chromosomes in humans. People normally have two copies of this chromosome. Chromosome 13 spans about 113 million base pairs and represents between 3.5 and 4% of the total DNA in cells.
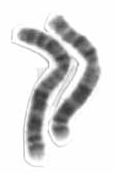
Chromosome 2 is one of the twenty-three pairs of chromosomes in humans. People normally have two copies of this chromosome. Chromosome 2 is the second-largest human chromosome, spanning more than 242 million base pairs and representing almost eight percent of the total DNA in human cells.
Cis-regulatory elements (CREs) or Cis-regulatory modules (CRMs) are regions of non-coding DNA which regulate the transcription of neighboring genes. CREs are vital components of genetic regulatory networks, which in turn control morphogenesis, the development of anatomy, and other aspects of embryonic development, studied in evolutionary developmental biology.

A nuclear gene is a gene whose physical DNA nucleotide sequence is located in the cell nucleus of a eukaryote. The term is used to distinguish nuclear genes from genes found in mitochondria or chloroplasts. The vast majority of genes in eukaryotes are nuclear.
In biology, the word gene can have several different meanings. The Mendelian gene is a basic unit of heredity and the molecular gene is a sequence of nucleotides in DNA that is transcribed to produce a functional RNA. There are two types of molecular genes: protein-coding genes and noncoding genes.
A conserved non-coding sequence (CNS) is a DNA sequence of noncoding DNA that is evolutionarily conserved. These sequences are of interest for their potential to regulate gene production.

Short interspersed nuclear elements (SINEs) are non-autonomous, non-coding transposable elements (TEs) that are about 100 to 700 base pairs in length. They are a class of retrotransposons, DNA elements that amplify themselves throughout eukaryotic genomes, often through RNA intermediates. SINEs compose about 13% of the mammalian genome.
The G-value paradox arises from the lack of correlation between the number of protein-coding genes among eukaryotes and their relative biological complexity. The microscopic nematode Caenorhabditis elegans, for example, is composed of only a thousand cells but has about the same number of genes as a human. Researchers suggest resolution of the paradox may lie in mechanisms such as alternative splicing and complex gene regulation that make the genes of humans and other complex eukaryotes relatively more productive.
This glossary of genetics is a list of definitions of terms and concepts commonly used in the study of genetics and related disciplines in biology, including molecular biology, cell biology, and evolutionary biology. It is intended as introductory material for novices; for more specific and technical detail, see the article corresponding to each term. For related terms, see Glossary of evolutionary biology.
This glossary of genetics is a list of definitions of terms and concepts commonly used in the study of genetics and related disciplines in biology, including molecular biology, cell biology, and evolutionary biology. It is split across two articles: