In information theory, data compression, source coding, or bit-rate reduction is the process of encoding information using fewer bits than the original representation. Any particular compression is either lossy or lossless. Lossless compression reduces bits by identifying and eliminating statistical redundancy. No information is lost in lossless compression. Lossy compression reduces bits by removing unnecessary or less important information. Typically, a device that performs data compression is referred to as an encoder, and one that performs the reversal of the process (decompression) as a decoder.

MP3 is a coding format for digital audio developed largely by the Fraunhofer Society in Germany under the lead of Karlheinz Brandenburg. It was designed to greatly reduce the amount of data required to represent audio, yet still sound like a faithful reproduction of the original uncompressed audio to most listeners; for example, compared to CD-quality digital audio, MP3 compression can commonly achieve a 75–95% reduction in size, depending on the bit rate. In popular usage, MP3 often refers to files of sound or music recordings stored in the MP3 file format (.mp3) on consumer electronic devices.
MPEG-1 is a standard for lossy compression of video and audio. It is designed to compress VHS-quality raw digital video and CD audio down to about 1.5 Mbit/s without excessive quality loss, making video CDs, digital cable/satellite TV and digital audio broadcasting (DAB) practical.
Linear predictive coding (LPC) is a method used mostly in audio signal processing and speech processing for representing the spectral envelope of a digital signal of speech in compressed form, using the information of a linear predictive model.
MPEG-1 Audio Layer II or MPEG-2 Audio Layer II is a lossy audio compression format defined by ISO/IEC 11172-3 alongside MPEG-1 Audio Layer I and MPEG-1 Audio Layer III (MP3). While MP3 is much more popular for PC and Internet applications, MP2 remains a dominant standard for audio broadcasting.

A compression artifact is a noticeable distortion of media caused by the application of lossy compression. Lossy data compression involves discarding some of the media's data so that it becomes small enough to be stored within the desired disk space or transmitted (streamed) within the available bandwidth. If the compressor cannot store enough data in the compressed version, the result is a loss of quality, or introduction of artifacts. The compression algorithm may not be intelligent enough to discriminate between distortions of little subjective importance and those objectionable to the user.

Audio system measurements are used to quantify audio system performance. These measurements are made for several purposes. Designers take measurements to specify the performance of a piece of equipment. Maintenance engineers make them to ensure equipment is still working to specification, or to ensure that the cumulative defects of an audio path are within limits considered acceptable. Audio system measurements often accommodate psychoacoustic principles to measure the system in a way that relates to human hearing.
Harmonic and Individual Lines and Noise (HILN) is a parametric codec for audio. The basic premise of the encoder is that most audio, and particularly speech, can be synthesized from only sinusoids and noise. The encoder describes individual sinusoids with amplitude and frequency, harmonic tones by fundamental frequency, amplitude and the spectral envelope of the partials, and the noise by amplitude and spectral envelope. This type of encoder is capable of encoding audio to between 6 and 16 kilobits per second for a typical audio bandwidth of 8 kHz. The framelength of this encoder is 32 ms.

Spectral band replication (SBR) is a technology to enhance audio or speech codecs, especially at low bit rates and is based on harmonic redundancy in the frequency domain.
Noise shaping is a technique typically used in digital audio, image, and video processing, usually in combination with dithering, as part of the process of quantization or bit-depth reduction of a signal. Its purpose is to increase the apparent signal-to-noise ratio of the resultant signal. It does this by altering the spectral shape of the error that is introduced by dithering and quantization; such that the noise power is at a lower level in frequency bands at which noise is considered to be less desirable and at a correspondingly higher level in bands where it is considered to be more desirable. A popular noise shaping algorithm used in image processing is known as ‘Floyd Steinberg dithering’; and many noise shaping algorithms used in audio processing are based on an ‘Absolute threshold of hearing’ model.
Code-excited linear prediction (CELP) is a linear predictive speech coding algorithm originally proposed by Manfred R. Schroeder and Bishnu S. Atal in 1985. At the time, it provided significantly better quality than existing low bit-rate algorithms, such as residual-excited linear prediction (RELP) and linear predictive coding (LPC) vocoders. Along with its variants, such as algebraic CELP, relaxed CELP, low-delay CELP and vector sum excited linear prediction, it is currently the most widely used speech coding algorithm. It is also used in MPEG-4 Audio speech coding. CELP is commonly used as a generic term for a class of algorithms and not for a particular codec.
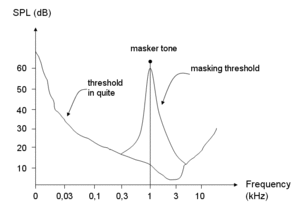
In audiology and psychoacoustics the concept of critical bands, introduced by Harvey Fletcher in 1933 and refined in 1940, describes the frequency bandwidth of the "auditory filter" created by the cochlea, the sense organ of hearing within the inner ear. Roughly, the critical band is the band of audio frequencies within which a second tone will interfere with the perception of the first tone by auditory masking.
In audio signal processing, pre-echo, sometimes called a forward echo, is a digital audio compression artifact where a sound is heard before it occurs. It is most noticeable in impulsive sounds from percussion instruments such as castanets or cymbals.

In digital audio using pulse-code modulation (PCM), bit depth is the number of bits of information in each sample, and it directly corresponds to the resolution of each sample. Examples of bit depth include Compact Disc Digital Audio, which uses 16 bits per sample, and DVD-Audio and Blu-ray Disc, which can support up to 24 bits per sample.
Perceptual Evaluation of Audio Quality (PEAQ) is a standardized algorithm for objectively measuring perceived audio quality, developed in 1994–1998 by a joint venture of experts within Task Group 6Q of the International Telecommunication Union's Radiocommunication Sector (ITU-R). It was originally released as ITU-R Recommendation BS.1387 in 1998 and last updated in 2023. It utilizes software to simulate perceptual properties of the human ear and then integrates multiple model output variables into a single metric.
In audio signal processing, auditory masking occurs when the perception of one sound is affected by the presence of another sound.
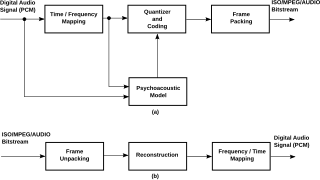
In signal processing, sub-band coding (SBC) is any form of transform coding that breaks a signal into a number of different frequency bands, typically by using a fast Fourier transform, and encodes each one independently. This decomposition is often the first step in data compression for audio and video signals.
Psychoacoustics is the branch of psychophysics involving the scientific study of the perception of sound by the human auditory system. It is the branch of science studying the psychological responses associated with sound including noise, speech, and music. Psychoacoustics is an interdisciplinary field including psychology, acoustics, electronic engineering, physics, biology, physiology, and computer science.

Audio forensics is the field of forensic science relating to the acquisition, analysis, and evaluation of sound recordings that may ultimately be presented as admissible evidence in a court of law or some other official venue.
Temporal envelope (ENV) and temporal fine structure (TFS) are changes in the amplitude and frequency of sound perceived by humans over time. These temporal changes are responsible for several aspects of auditory perception, including loudness, pitch and timbre perception and spatial hearing.