Related Research Articles
In computing, a compiler is a computer program that translates computer code written in one programming language into another language. The name "compiler" is primarily used for programs that translate source code from a high-level programming language to a low-level programming language to create an executable program.
Natural language processing (NLP) is an interdisciplinary subfield of linguistics and computer science. It is primarily concerned with processing natural language datasets, such as text corpora or speech corpora, using either rule-based or probabilistic machine learning approaches. The goal is a computer capable of "understanding" the contents of documents, including the contextual nuances of the language within them. The technology can then accurately extract information and insights contained in the documents as well as categorize and organize the documents themselves.

A programming language is a system of notation for writing computer programs. Most programming languages are text-based formal languages, but they may also be graphical. They are a kind of computer language.
Extensible Markup Language (XML) is a markup language and file format for storing, transmitting, and reconstructing arbitrary data. It defines a set of rules for encoding documents in a format that is both human-readable and machine-readable. The World Wide Web Consortium's XML 1.0 Specification of 1998 and several other related specifications—all of them free open standards—define XML.
In computer science, a compiler-compiler or compiler generator is a programming tool that creates a parser, interpreter, or compiler from some form of formal description of a programming language and machine.
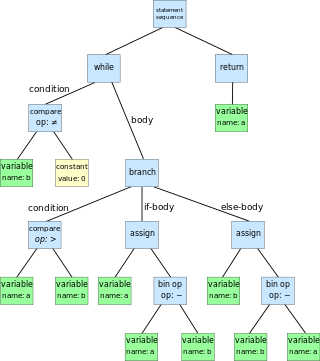
In computer science, an abstract syntax tree (AST), or just syntax tree, is a tree representation of the abstract syntactic structure of text written in a formal language. Each node of the tree denotes a construct occurring in the text.

Syntax highlighting is a feature of text editors that is used for programming, scripting, or markup languages, such as HTML. The feature displays text, especially source code, in different colours and fonts according to the category of terms. This feature facilitates writing in a structured language such as a programming language or a markup language as both structures and syntax errors are visually distinct. This feature is also employed in many programming related contexts, either in the form of colorful books or online websites to make understanding code snippets easier for readers. Highlighting does not affect the meaning of the text itself; it is intended only for human readers.
Parsing, syntax analysis, or syntactic analysis is the process of analyzing a string of symbols, either in natural language, computer languages or data structures, conforming to the rules of a formal grammar. The term parsing comes from Latin pars (orationis), meaning part.
In computing, RELAX NG is a schema language for XML—a RELAX NG schema specifies a pattern for the structure and content of an XML document. A RELAX NG schema is itself an XML document but RELAX NG also offers a popular compact, non-XML syntax. Compared to other XML schema languages RELAX NG is considered relatively simple.
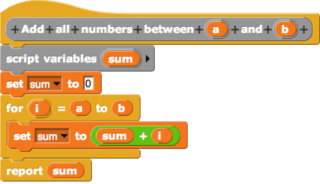
In computing, a visual programming language or block coding is a programming language that lets users create programs by manipulating program elements graphically rather than by specifying them textually. A VPL allows programming with visual expressions, spatial arrangements of text and graphic symbols, used either as elements of syntax or secondary notation. For example, many VPLs are based on the idea of "boxes and arrows", where boxes or other screen objects are treated as entities, connected by arrows, lines or arcs which represent relations.
A lightweight markup language (LML), also termed a simple or humane markup language, is a markup language with simple, unobtrusive syntax. It is designed to be easy to write using any generic text editor and easy to read in its raw form. Lightweight markup languages are used in applications where it may be necessary to read the raw document as well as the final rendered output.

A source-code editor is a text editor program designed specifically for editing source code of computer programs. It may be a standalone application or it may be built into an integrated development environment (IDE).
A program transformation is any operation that takes a computer program and generates another program. In many cases the transformed program is required to be semantically equivalent to the original, relative to a particular formal semantics and in fewer cases the transformations result in programs that semantically differ from the original in predictable ways.

In computer science, the syntax of a computer language is the rules that define the combinations of symbols that are considered to be correctly structured statements or expressions in that language. This applies both to programming languages, where the document represents source code, and to markup languages, where the document represents data.
The DMS Software Reengineering Toolkit is a proprietary set of program transformation tools available for automating custom source program analysis, modification, translation or generation of software systems for arbitrary mixtures of source languages for large scale software systems. DMS was originally motivated by a theory for maintaining designs of software called Design Maintenance Systems. DMS and "Design Maintenance System" are registered trademarks of Semantic Designs.
GrammaTech is a software-development tools vendor based in Bethesda, Maryland with a research center based in Ithaca, New York. The company was founded in 1988 as a technology spin-off of Cornell University. GrammaTech is a provider of application security testing products and software research services.

In computing, a compiler is a computer program that transforms source code written in a programming language or computer language, into another computer language. The most common reason for transforming source code is to create an executable program.
JetBrains MPS is a language workbench developed by JetBrains. MPS is a tool to design domain-specific languages (DSL). It uses projectional editing which allows users to overcome the limits of language parsers, and build DSL editors, such as ones with tables and diagrams.
It implements language-oriented programming. MPS is an environment for language definition, a language workbench, and integrated development environment (IDE) for such languages.
The Sweble Wikitext parser is an open-source tool to parse the Wikitext markup language used by MediaWiki, the software behind Wikipedia. The initial development was done by Hannes Dohrn as a Ph.D. thesis project at the Open Source Research Group of professor Dirk Riehle at the University of Erlangen-Nuremberg from 2009 until 2011. The results were presented to the public for the first time at the WikiSym conference in 2011. Before that, the dissertation was inspected and approved by an independent scientific peer-review and was published at ACM Press.
(Ray) Tim Teitelbaum is an American computer scientist known for his early work on integrated development environments (IDEs), syntax-directed editing, and incremental computation. He is Professor Emeritus at Cornell University. As an educator and faculty member of the Cornell University Computer Science Department since 1973, he was recognized for his large-scale teaching of introductory programming, and for his mentoring of highly successful graduate students. As a businessman, he is known for having co-founded GrammaTech, Inc. and for having been its sole CEO from 1988 to 2019.
References
- ↑ Hansen, Wilfred J. (1971). "User engineering principles for interactive systems". Proceedings of the Fall Joint Computer Conference FJCC 39. AFIPS. pp. 5623–532.
- ↑ Donzeau Gouge, V.; Huet, G.; Kahn, G.; Lang, B. (July 1980). "Programming environments based on structured editors: The Mentor experience" (PDF). INRIA Research report no. 26.
- ↑ Teitelbaum, T.; T. Reps (September 1981). "The Cornell Program Synthesizer: A syntax-directed programming environment". Communications of the ACM. 24 (9): 563–573. doi: 10.1145/358746.358755 .
- ↑ Habermann, A. Nico; Notkin, David (1986). "Gandalf: Software Development Environments" (PDF). IEEE Trans. Softw. Eng. 12 (12): 1117–1127. doi:10.1109/TSE.1986.6313007. S2CID 11474349.
- ↑ Medina Mora, Raul (1982). Syntax-directed editing--towards integrating programming environments. Pittsburgh, PA: Carnegie Mellon University (PhD Dissertation).
- ↑ Kaiser, Gail Elaine (1985). Semantics for structure editing environments. Pittsburgh, PA: Carnegie Mellon University (PhD Dissertation).
- ↑ Reps, T. (1984). Generating Language-Based Environments. Cambridge, MA: The M.I.T. Press. (Awarded the 1983 ACM Doctoral Dissertation Award.).
- ↑ Reps, Thomas W.; Teitelbaum, Tim (1988). The Synthesizer Generator: A System for Constructing Language-Based Editors. Cambridge, MA: Springer-Verlag.
- ↑ Snelting, Gregor; Henhapl, Wolfgang (1986). "Unification in many-sorted algebras as a device for incremental semantic analysis". Proceedings of the 13th ACM SIGACT-SIGPLAN symposium on Principles of programming languages (POPL). New York, NY: ACM Press. pp. 229–235.
- ↑ Borras, P.; Clement, D.; Despeyrouz, Th.; Incerpi, J.; Kahn, G.; Lang, B.; Pascual, V. (1989). "CENTAUR: The System". "Proceedings of the ACM SIGSOFT/SIGPLAN Software Engineering Symposium on Practical Software Development Environments (PSDE). Vol. 24. New York, NY: ACM Press. pp. 14–24.
- ↑ Ballance, Robert A.; Graham, Susan L.; Van De Vanter, Michael L. (1990). "Pan language-based editing system for integrated development". SDE 4: Proceedings of the fourth ACM SIGSOFT symposium on Software development environments. Irvine, CA: ACM Press. pp. 77–93.
- ↑ Czarnecki, Krzysztof & Eisenecker, Ulrich (June 2000). Generative Programming: Methods, Tools, and Applications, Chapter 11 (Intentional Programming). Reading, MA: Addison-Wesley.