
The median of a set of numbers is the value separating the higher half from the lower half of a data sample, a population, or a probability distribution. For a data set, it may be thought of as the “middle" value. The basic feature of the median in describing data compared to the mean is that it is not skewed by a small proportion of extremely large or small values, and therefore provides a better representation of the center. Median income, for example, may be a better way to describe the center of the income distribution because increases in the largest incomes alone have no effect on the median. For this reason, the median is of central importance in robust statistics.

In statistics, the standard deviation is a measure of the amount of variation of the values of a variable about its mean. A low standard deviation indicates that the values tend to be close to the mean of the set, while a high standard deviation indicates that the values are spread out over a wider range. The standard deviation is commonly used in the determination of what constitutes an outlier and what does not.

In probability and statistics, Student's t distribution is a continuous probability distribution that generalizes the standard normal distribution. Like the latter, it is symmetric around zero and bell-shaped.
In probability theory, Chebyshev's inequality provides an upper bound on the probability of deviation of a random variable from its mean. More specifically, the probability that a random variable deviates from its mean by more than is at most , where is any positive constant and is the standard deviation.
In statistics, point estimation involves the use of sample data to calculate a single value which is to serve as a "best guess" or "best estimate" of an unknown population parameter. More formally, it is the application of a point estimator to the data to obtain a point estimate.
In medicine and health-related fields, a reference range or reference interval is the range or the interval of values that is deemed normal for a physiological measurement in healthy persons. It is a basis for comparison for a physician or other health professional to interpret a set of test results for a particular patient. Some important reference ranges in medicine are reference ranges for blood tests and reference ranges for urine tests.
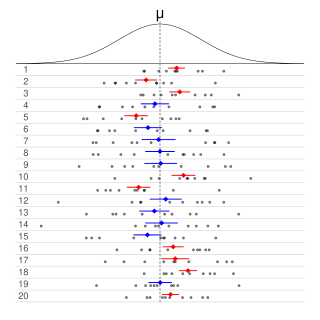
Informally, in frequentist statistics, a confidence interval (CI) is an interval which is expected to typically contain the parameter being estimated. More specifically, given a confidence level , a CI is a random interval which contains the parameter being estimated % of the time. The confidence level, degree of confidence or confidence coefficient represents the long-run proportion of CIs that theoretically contain the true value of the parameter; this is tantamount to the nominal coverage probability. For example, out of all intervals computed at the 95% level, 95% of them should contain the parameter's true value.
In statistics, an effect size is a value measuring the strength of the relationship between two variables in a population, or a sample-based estimate of that quantity. It can refer to the value of a statistic calculated from a sample of data, the value of a parameter for a hypothetical population, or to the equation that operationalizes how statistics or parameters lead to the effect size value. Examples of effect sizes include the correlation between two variables, the regression coefficient in a regression, the mean difference, or the risk of a particular event happening. Effect sizes are a complement tool for statistical hypothesis testing, and play an important role in power analyses to assess the sample size required for new experiments. Effect size are fundamental in meta-analyses which aim to provide the combined effect size based on data from multiple studies. The cluster of data-analysis methods concerning effect sizes is referred to as estimation statistics.
In statistical inference, specifically predictive inference, a prediction interval is an estimate of an interval in which a future observation will fall, with a certain probability, given what has already been observed. Prediction intervals are often used in regression analysis.
The standard error (SE) of a statistic is the standard deviation of its sampling distribution or an estimate of that standard deviation. If the statistic is the sample mean, it is called the standard error of the mean (SEM). The standard error is a key ingredient in producing confidence intervals.

In probability theory and statistics, the triangular distribution is a continuous probability distribution with lower limit a, upper limit b, and mode c, where a < b and a ≤ c ≤ b.
Sample size determination or estimation is the act of choosing the number of observations or replicates to include in a statistical sample. The sample size is an important feature of any empirical study in which the goal is to make inferences about a population from a sample. In practice, the sample size used in a study is usually determined based on the cost, time, or convenience of collecting the data, and the need for it to offer sufficient statistical power. In complex studies, different sample sizes may be allocated, such as in stratified surveys or experimental designs with multiple treatment groups. In a census, data is sought for an entire population, hence the intended sample size is equal to the population. In experimental design, where a study may be divided into different treatment groups, there may be different sample sizes for each group.
This glossary of statistics and probability is a list of definitions of terms and concepts used in the mathematical sciences of statistics and probability, their sub-disciplines, and related fields. For additional related terms, see Glossary of mathematics and Glossary of experimental design.
In statistics, a binomial proportion confidence interval is a confidence interval for the probability of success calculated from the outcome of a series of success–failure experiments. In other words, a binomial proportion confidence interval is an interval estimate of a success probability when only the number of experiments and the number of successes are known.
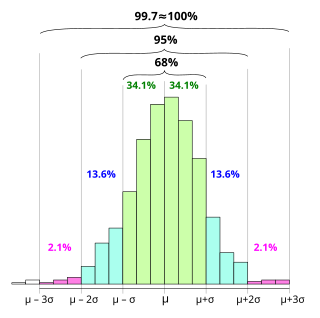
In statistics, the 68–95–99.7 rule, also known as the empirical rule, and sometimes abbreviated 3sr, is a shorthand used to remember the percentage of values that lie within an interval estimate in a normal distribution: approximately 68%, 95%, and 99.7% of the values lie within one, two, and three standard deviations of the mean, respectively.
In probability theory and statistics, the index of dispersion, dispersion index, coefficient of dispersion, relative variance, or variance-to-mean ratio (VMR), like the coefficient of variation, is a normalized measure of the dispersion of a probability distribution: it is a measure used to quantify whether a set of observed occurrences are clustered or dispersed compared to a standard statistical model.
In statistics, additive smoothing, also called Laplace smoothing or Lidstone smoothing, is a technique used to smooth count data, eliminating issues caused by certain values having 0 occurrences. Given a set of observation counts from a -dimensional multinomial distribution with trials, a "smoothed" version of the counts gives the estimator
In statistics, robust measures of scale are methods that quantify the statistical dispersion in a sample of numerical data while resisting outliers. The most common such robust statistics are the interquartile range (IQR) and the median absolute deviation (MAD). These are contrasted with conventional or non-robust measures of scale, such as sample standard deviation, which are greatly influenced by outliers.
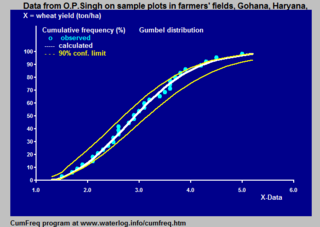
Cumulative frequency analysis is the analysis of the frequency of occurrence of values of a phenomenon less than a reference value. The phenomenon may be time- or space-dependent. Cumulative frequency is also called frequency of non-exceedance.
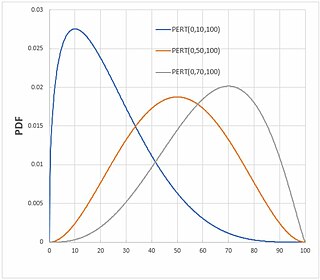
In probability and statistics, the PERT distributions are a family of continuous probability distributions defined by the minimum (a), most likely (b) and maximum (c) values that a variable can take. It is a transformation of the four-parameter beta distribution with an additional assumption that its expected value is

