In computer science, an AVL tree is a self-balancing binary search tree. It was the first such data structure to be invented. In an AVL tree, the heights of the two child subtrees of any node differ by at most one; if at any time they differ by more than one, rebalancing is done to restore this property. Lookup, insertion, and deletion all take O(log n) time in both the average and worst cases, where is the number of nodes in the tree prior to the operation. Insertions and deletions may require the tree to be rebalanced by one or more tree rotations.

In computer science, a binary tree is a k-ary tree data structure in which each node has at most two children, which are referred to as the left child and the right child. A recursive definition using just set theory notions is that a (non-empty) binary tree is a tuple (L, S, R), where L and R are binary trees or the empty set and S is a singleton set containing the root. Some authors allow the binary tree to be the empty set as well.
In computer science, a B-tree is a self-balancing tree data structure that maintains sorted data and allows searches, sequential access, insertions, and deletions in logarithmic time. The B-tree generalizes the binary search tree, allowing for nodes with more than two children. Unlike other self-balancing binary search trees, the B-tree is well suited for storage systems that read and write relatively large blocks of data, such as databases and file systems.
In computer science, a red–black tree is a kind of self-balancing binary search tree. In addition to the search key and other user data, each node stores an extra bit representing "red" and "black" which helps to keep the tree balanced during insertions and deletions.

In computer science, a tree is a widely used abstract data type that represents a hierarchical tree structure with a set of connected nodes. Each node in the tree can be connected to many children, but must be connected to exactly one parent, except for the root node, which has no parent. These constraints mean there are no cycles or "loops", and also that each child can be treated like the root node of its own subtree, making recursion a useful technique for tree traversal. In contrast to linear data structures, many trees cannot be represented by relationships between neighboring nodes in a single straight line.
In computer science, tree traversal is a form of graph traversal and refers to the process of visiting each node in a tree data structure, exactly once. Such traversals are classified by the order in which the nodes are visited. The following algorithms are described for a binary tree, but they may be generalized to other trees as well.

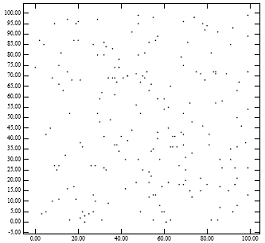
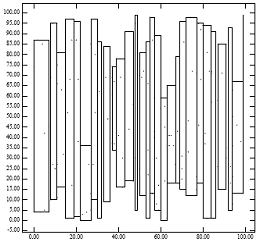
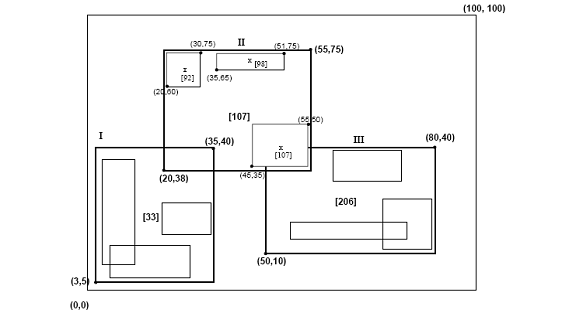
R-trees are tree data structures used for spatial access methods, i.e., for indexing multi-dimensional information such as geographical coordinates, rectangles or polygons. The R-tree was proposed by Antonin Guttman in 1984 and has found significant use in both theoretical and applied contexts. A common real-world usage for an R-tree might be to store spatial objects such as restaurant locations or the polygons that typical maps are made of: streets, buildings, outlines of lakes, coastlines, etc. and then find answers quickly to queries such as "Find all museums within 2 km of my current location", "retrieve all road segments within 2 km of my location" or "find the nearest gas station". The R-tree can also accelerate nearest neighbor search for various distance metrics, including great-circle distance.
Adaptive Huffman coding is an adaptive coding technique based on Huffman coding. It permits building the code as the symbols are being transmitted, having no initial knowledge of source distribution, that allows one-pass encoding and adaptation to changing conditions in data.
In computer science, a 2–3–4 tree is a self-balancing data structure that can be used to implement dictionaries. The numbers mean a tree where every node with children has either two, three, or four child nodes:
A B+ tree is an m-ary tree with a variable but often large number of children per node. A B+ tree consists of a root, internal nodes and leaves. The root may be either a leaf or a node with two or more children.
An R+ tree is a method for looking up data using a location, often coordinates, and often for locations on the surface of the earth. Searching on one number is a solved problem; searching on two or more, and asking for locations that are nearby in both x and y directions, requires craftier algorithms.
In data processing R*-trees are a variant of R-trees used for indexing spatial information. R*-trees have slightly higher construction cost than standard R-trees, as the data may need to be reinserted; but the resulting tree will usually have a better query performance. Like the standard R-tree, it can store both point and spatial data. It was proposed by Norbert Beckmann, Hans-Peter Kriegel, Ralf Schneider, and Bernhard Seeger in 1990.

In information visualization and computing, treemapping is a method for displaying hierarchical data using nested figures, usually rectangles.

In computer science, a k-d tree is a space-partitioning data structure for organizing points in a k-dimensional space. k-d trees are a useful data structure for several applications, such as searches involving a multidimensional search key and creating point clouds. k-d trees are a special case of binary space partitioning trees.

In mathematical analysis and computer science, functions which are Z-order, Lebesgue curve, Morton space-filling curve, Morton order or Morton code map multidimensional data to one dimension while preserving locality of the data points. It is named in France after Henri Lebesgue, who studied it in 1904, and named in US after Guy Macdonald Morton, who first applied the order to file sequencing in 1966. The z-value of a point in multidimensions is simply calculated by interleaving the binary representations of its coordinate values. Once the data are sorted into this ordering, any one-dimensional data structure can be used such as binary search trees, B-trees, skip lists or hash tables. The resulting ordering can equivalently be described as the order one would get from a depth-first traversal of a quadtree or octree.
In computer science tree data structures, an X-tree is an index tree structure based on the R-tree used for storing data in many dimensions. It appeared in 1996, and differs from R-trees (1984), R+-trees (1987) and R*-trees (1990) because it emphasizes prevention of overlap in the bounding boxes, which increasingly becomes a problem in high dimensions. In cases where nodes cannot be split without preventing overlap, the node split will be deferred, resulting in super-nodes. In extreme cases, the tree will linearize, which defends against worst-case behaviors observed in some other data structures.

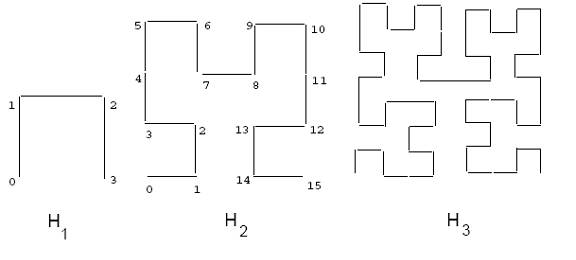
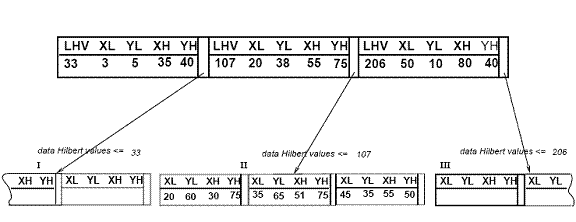
The Hilbert curve is a continuous fractal space-filling curve first described by the German mathematician David Hilbert in 1891, as a variant of the space-filling Peano curves discovered by Giuseppe Peano in 1890.
In computer science, the Bx tree is a query that is used to update efficient B+ tree-based index structures for moving objects.
In computer science, M-trees are tree data structures that are similar to R-trees and B-trees. It is constructed using a metric and relies on the triangle inequality for efficient range and k-nearest neighbor (k-NN) queries. While M-trees can perform well in many conditions, the tree can also have large overlap and there is no clear strategy on how to best avoid overlap. In addition, it can only be used for distance functions that satisfy the triangle inequality, while many advanced dissimilarity functions used in information retrieval do not satisfy this.
In computer science, a K-D-B-tree (k-dimensional B-tree) is a tree data structure for subdividing a k-dimensional search space. The aim of the K-D-B-tree is to provide the search efficiency of a balanced k-d tree, while providing the block-oriented storage of a B-tree for optimizing external memory accesses.