Related Research Articles
ISO/IEC 8859-3:1999, Information technology — 8-bit single-byte coded graphic character sets — Part 3: Latin alphabet No. 3, is part of the ISO/IEC 8859 series of ASCII-based standard character encodings, first edition published in 1988. It is informally referred to as Latin-3 or South European. It was designed to cover Turkish, Maltese and Esperanto, though the introduction of ISO/IEC 8859-9 superseded it for Turkish. The encoding was popular for users of Esperanto, but fell out of use as application support for Unicode became more common.
In computing, a code page is a character encoding and as such it is a specific association of a set of printable characters and control characters with unique numbers. Typically each number represents the binary value in a single byte.
ISO/IEC 8859-11:2001, Information technology — 8-bit single-byte coded graphic character sets — Part 11: Latin/Thai alphabet, is part of the ISO/IEC 8859 series of ASCII-based standard character encodings, first edition published in 2001. It is informally referred to as Latin/Thai. It is nearly identical to the national Thai standard TIS-620 (1990). The sole difference is that ISO/IEC 8859-11 allocates non-breaking space to code 0xA0, while TIS-620 leaves it undefined.
ISO/IEC 8859-6:1999, Information technology — 8-bit single-byte coded graphic character sets — Part 6: Latin/Arabic alphabet, is part of the ISO/IEC 8859 series of ASCII-based standard character encodings, first edition published in 1987. It is informally referred to as Latin/Arabic. It was designed to cover Arabic. Only nominal letters are encoded, no preshaped forms of the letters, so shaping processing is required for display. It does not include the extra letters needed to write most Arabic-script languages other than Arabic itself.
ISO/IEC 8859-9:1999, Information technology — 8-bit single-byte coded graphic character sets — Part 9: Latin alphabet No. 5, is part of the ISO/IEC 8859 series of ASCII-based standard character encodings, first edition published in 1989. It is designated ECMA-128 by Ecma International and TS 5881 as a Turkish standard. It is informally referred to as Latin-5 or Turkish. It was designed to cover the Turkish language, designed as being of more use than the ISO/IEC 8859-3 encoding. It is identical to ISO/IEC 8859-1 except for the replacement of six Icelandic characters with characters unique to the Turkish alphabet. And the uppercase of i is İ; the lowercase of I is ı.

Code page 850 is a code page used under DOS operating systems in Western Europe. Depending on the country setting and system configuration, code page 850 is the primary code page and default OEM code page in many countries, including various English-speaking locales, whilst other English-speaking locales default to the hardware code page 437.
The Kamenický encoding, named for the brothers Jiří and Marian Kamenický, was a code page for personal computers running DOS, very popular in Czechoslovakia around 1985–1995. Another name for this encoding is KEYBCS2, the name of the terminate-and-stay-resident utility which implemented the matching keyboard driver. It was also named KAMENICKY.

Code page 855 is a code page used under DOS to write Cyrillic script.
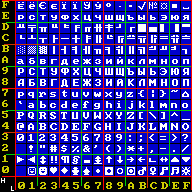
Code page 866 is a code page used under DOS and OS/2 in Russia to write Cyrillic script. It is based on the "alternative code page" developed in 1984 in IHNA AS USSR and published in 1986 by a research group at the Academy of Science of the USSR. The code page was widely used during the DOS era because it preserves all of the pseudographic symbols of code page 437 and maintains alphabetic order of Cyrillic letters. Initially this encoding was only available in the Russian version of MS-DOS 4.01 (1990), but with MS-DOS 6.22 it became available in any language version.
Windows-1250 is a code page used under Microsoft Windows to represent texts in Central European and Eastern European languages that use the Latin script. It is primarily used by Czech, though Czech has now moved to UTF-8 and mostly abandoned this legacy encoding. It is also used for Polish, Slovak, Hungarian, Slovene, Serbo-Croatian, Romanian, Rotokas and Albanian. It may also be used with the German language, though it's missing uppercase ẞ. German-language texts encoded with Windows-1250 and Windows-1252 are identical.
Mac OS Central European is a character encoding used on Apple Macintosh computers to represent texts in Central European and Southeastern European languages that use the Latin script. This encoding is also known as Code Page 10029. IBM assigns code page/CCSID 1282 to this encoding. This codepage contains diacritical letters that ISO 8859-2 does not have, and vice versa.
Code page 860 is a code page used under DOS in Portugal to write Portuguese and it is also suitable to write Spanish and Italian. In Brazil, however, the most widespread codepage – and that which DOS in Brazilian Portuguese used by default – was code page 850.
Code page 857 is a code page used under DOS in Turkey to write Turkish.

Code page 737 is a code page used under DOS to write the Greek language. It was much more popular than code page 869 although it lacks the letters ΐ and ΰ.
Code page 869 is a code page used under DOS to write Greek and may also be used to get Greek letters for other uses such as math. It is also called DOS Greek 2. It was designed to include all characters from ISO 8859-7.
Windows code pages are sets of characters or code pages used in Microsoft Windows from the 1980s and 1990s. Windows code pages were gradually superseded when Unicode was implemented in Windows, although they are still supported both within Windows and other platforms, and still apply when Alt code shortcuts are used.
Code page 862 is a code page used under DOS in Israel for Hebrew.
Code page 775 is a code page used under DOS to write the Estonian, Lithuanian and Latvian languages. In Lithuania, this code page is standardised as LST 1590-1, alongside the related Code page 778.
Code page 912 is a code page used under IBM AIX and DOS to write the Albanian, Bosnian, Croatian, Czech, English, German, Hungarian, Polish, Romanian, Serbian, Slovak, and Slovene languages. It is an extension of ISO/IEC 8859-2.
Code page 856, is a code page used under DOS for Hebrew in Israel.
References
- ↑ Character Sets, Internet Assigned Numbers Authority (IANA), 2018-12-12
- 1 2 "OEM 852". Go Global Developer Center. Microsoft. Retrieved 11 Nov 2011.
- ↑ "Code Pages Supported by Windows: OEM Code Pages". Go Global Developer Center. Microsoft. Archived from the original on 2 November 2011. Retrieved 11 Oct 2011.
- 1 2 "Code Page 852 DOS Latin 2". Developing International Software. Microsoft. Retrieved 11 Nov 2011.
- ↑ "CCSID 852 information document". Archived from the original on 2016-03-27.
- ↑ "CCSID 9044 information document". Archived from the original on 2016-03-27.
- 1 2 Code Page CPGID 00852 (pdf) (PDF), IBM[ permanent dead link ]
- 1 2 Code Page CPGID 00852 (txt), IBM
- ↑ "The Czech and Slovak Character Encoding Mess Explained". luki.sdf-eu.org. Retrieved 2022-02-27.
- ↑ The Czech and Slovak Character Encoding Mess Explained / Kamenicky
- ↑ "cp852_DOSLatin2 to Unicode table" (TXT). The Unicode Consortium. Retrieved 11 Nov 2011.
- ↑ International Components for Unicode (ICU), ibm-852_P100-1995.ucm, 2002-12-03
| Early telecommunications | |
|---|---|
| ISO/IEC 8859 |
|
| Bibliographic use | |
| National standards | |
| ISO/IEC 2022 | |
| Mac OS Code pages ("scripts") | |
| DOS code pages | |
| IBM AIX code pages | |
| Windows code pages | |
| EBCDIC code pages | |
| DEC terminals (VTx) | |
| Platform specific |
|
| Unicode / ISO/IEC 10646 | |
| TeX typesetting system | |
| Miscellaneous code pages | |
| Control character | |
| Related topics | |