Related Research Articles
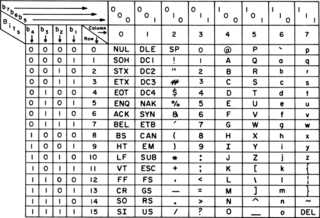
ASCII, an acronym for American Standard Code for Information Interchange, is a character encoding standard for electronic communication. ASCII codes represent text in computers, telecommunications equipment, and other devices. Because of technical limitations of computer systems at the time it was invented, ASCII has just 128 code points, of which only 95 are printable characters, which severely limited its scope. Modern computer systems have evolved to use Unicode, which has millions of code points, but the first 128 of these are the same as the ASCII set.

Character encoding is the process of assigning numbers to graphical characters, especially the written characters of human language, allowing them to be stored, transmitted, and transformed using digital computers. The numerical values that make up a character encoding are known as "code points" and collectively comprise a "code space", a "code page", or a "character map".
Multipurpose Internet Mail Extensions (MIME) is a standard that extends the format of email messages to support text in character sets other than ASCII, as well as attachments of audio, video, images, and application programs. Message bodies may consist of multiple parts, and header information may be specified in non-ASCII character sets. Email messages with MIME formatting are typically transmitted with standard protocols, such as the Simple Mail Transfer Protocol (SMTP), the Post Office Protocol (POP), and the Internet Message Access Protocol (IMAP).
Unicode, formally The Unicode Standard, is a text encoding standard maintained by the Unicode Consortium designed to support the use of text written in all of the world's major writing systems. Version 15.1 of the standard defines 149813 characters and 161 scripts used in various ordinary, literary, academic, and technical contexts.
Web pages authored using HyperText Markup Language (HTML) may contain multilingual text represented with the Unicode universal character set. Key to the relationship between Unicode and HTML is the relationship between the "document character set", which defines the set of characters that may be present in an HTML document and assigns numbers to them, and the "external character encoding", or "charset", used to encode a given document as a sequence of bytes.
UTF-8 is a variable-length character encoding standard used for electronic communication. Defined by the Unicode Standard, the name is derived from Unicode Transformation Format – 8-bit.

UTF-16 (16-bit Unicode Transformation Format) is a character encoding capable of encoding all 1,112,064 valid code points of Unicode (in fact this number of code points is dictated by the design of UTF-16). The encoding is variable-length, as code points are encoded with one or two 16-bit code units. UTF-16 arose from an earlier obsolete fixed-width 16-bit encoding now known as UCS-2 (for 2-byte Universal Character Set), once it became clear that more than 216 (65,536) code points were needed, including most emoji and important CJK characters such as for personal and place names.
8-bit clean is an attribute of computer systems, communication channels, and other devices and software, that process 8-bit character encodings without treating any byte as an in-band control code.
The byte-order mark (BOM) is a particular usage of the special Unicode character code, U+FEFFZERO WIDTH NO-BREAK SPACE, whose appearance as a magic number at the start of a text stream can signal several things to a program reading the text:
UTF-32 (32-bit Unicode Transformation Format) is a fixed-length encoding used to encode Unicode code points that uses exactly 32 bits (four bytes) per code point (but a number of leading bits must be zero as there are far fewer than 232 Unicode code points, needing actually only 21 bits). UTF-32 is a fixed-length encoding, in contrast to all other Unicode transformation formats, which are variable-length encodings. Each 32-bit value in UTF-32 represents one Unicode code point and is exactly equal to that code point's numerical value.
A text file is a kind of computer file that is structured as a sequence of lines of electronic text. A text file exists stored as data within a computer file system. In operating systems such as CP/M and DOS, where the operating system does not keep track of the file size in bytes, the end of a text file is denoted by placing one or more special characters, known as an end-of-file (EOF) marker, as padding after the last line in a text file. On modern operating systems such as Microsoft Windows and Unix-like systems, text files do not contain any special EOF character, because file systems on those operating systems keep track of the file size in bytes. Most text files need to have end-of-line delimiters, which are done in a few different ways depending on operating system. Some operating systems with record-orientated file systems may not use new line delimiters and will primarily store text files with lines separated as fixed or variable length records.
In computer programming, Base64 is a group of binary-to-text encoding schemes that transforms binary data into a sequence of printable characters, limited to a set of 64 unique characters. More specifically, the source binary data is taken 6 bits at a time, then this group of 6 bits is mapped to one of 64 unique characters.
The null character is a control character with the value zero. It is present in many character sets, including those defined by the Baudot and ITA2 codes, ISO/IEC 646, the C0 control code, the Universal Coded Character Set, and EBCDIC. It is available in nearly all mainstream programming languages. It is often abbreviated as NUL. In 8-bit codes, it is known as a null byte.
ISO/IEC 2022Information technology—Character code structure and extension techniques, is an ISO/IEC standard in the field of character encoding. It is equivalent to the ECMA standard ECMA-35, the ANSI standard ANSI X3.41 and the Japanese Industrial Standard JIS X 0202. Originating in 1971, it was most recently revised in 1994.
Quoted-Printable, or QP encoding, is a binary-to-text encoding system using printable ASCII characters to transmit 8-bit data over a 7-bit data path or, generally, over a medium which is not 8-bit clean. Historically, because of the wide range of systems and protocols that could be used to transfer messages, e-mail was often assumed to be non-8-bit-clean – however, modern SMTP servers are in most cases 8-bit clean and support 8BITMIME extension. It can also be used with data that contains non-permitted octets or line lengths exceeding SMTP limits. It is defined as a MIME content transfer encoding for use in e-mail.
Ascii85, also called Base85, is a form of binary-to-text encoding developed by Paul E. Rutter for the btoa utility. By using five ASCII characters to represent four bytes of binary data, it is more efficient than uuencode or Base64, which use four characters to represent three bytes of data.
Many email clients now offer some support for Unicode. Some clients will automatically choose between a legacy encoding and Unicode depending on the mail's content, either automatically or when the user requests it.
The Compatibility Encoding Scheme for UTF-16: 8-Bit (CESU-8) is a variant of UTF-8 that is described in Unicode Technical Report #26. A Unicode code point from the Basic Multilingual Plane (BMP), i.e. a code point in the range U+0000 to U+FFFF, is encoded in the same way as in UTF-8. A Unicode supplementary character, i.e. a code point in the range U+10000 to U+10FFFF, is first represented as a surrogate pair, like in UTF-16, and then each surrogate code point is encoded in UTF-8. Therefore, CESU-8 needs six bytes for each Unicode supplementary character while UTF-8 needs only four. Though not specified in the technical report, unpaired surrogates are also encoded as 3 bytes each, and CESU-8 is exactly the same as applying an older UCS-2 to UTF-8 converter to UTF-16 data.
This article compares Unicode encodings. Two situations are considered: 8-bit-clean environments, and environments that forbid use of byte values that have the high bit set. Originally such prohibitions were to allow for links that used only seven data bits, but they remain in some standards and so some standard-conforming software must generate messages that comply with the restrictions. Standard Compression Scheme for Unicode and Binary Ordered Compression for Unicode are excluded from the comparison tables because it is difficult to simply quantify their size.
A binary-to-text encoding is encoding of data in plain text. More precisely, it is an encoding of binary data in a sequence of printable characters. These encodings are necessary for transmission of data when the communication channel does not allow binary data or is not 8-bit clean. PGP documentation uses the term "ASCII armor" for binary-to-text encoding when referring to Base64.
References
- 1 2 "Breaking change: UTF-7 code paths are obsolete". docs.microsoft.com. Retrieved 8 January 2021.
- ↑ "8.2.2.3. Character encodings". HTML 5.1 Standard. W3C.
- ↑ "12.2.3.3 Character encodings". HTML Living Standard. WHATWG.
- ↑ "Using International Characters in Internet Mail". Internet Mail Consortium. 1 August 1998. Archived from the original on 7 September 2015.
- ↑ "Configuration Manual". Dovecot Documentation. 8 February 2023. Sec. "Mail Location Settings". Retrieved 28 February 2023.
Store mailbox names on disk using UTF-8 instead of modified UTF-7 (mUTF-7).
- ↑ "Internet Message Access Protocol - Version 4rev1". RFC Editor. Internet Society. Sec. 5.1.3 "Mailbox International Naming Convention". March 2003. Retrieved 28 February 2023.
In modified UTF-7, printable US-ASCII characters, except for "&", represent themselves…. The character "&" (0x26) is represented by the two-octet sequence "&-". All other characters… are represented in modified BASE64….
- ↑ "Internet Message Access Protocol (IMAP) - Version 4rev2". RFC Editor. Internet Society. Sec. 5.1. "Mailbox Naming". August 2021. Retrieved 28 February 2023.
In IMAP4rev2, mailbox names are encoded in Net-Unicode (this differs from IMAP4rev1).
- ↑ "FAQ – UTF-8, UTF-16, UTF-32 & BOM".
- ↑ "Clarify guidance for use of a BOM as a UTF-8 encoding signature" (PDF). Retrieved 17 January 2024.
- ↑ "ArticleUtf7 - doctype-mirror - UTF-7: the case of the missing charset - Mirror of Google Doctype - Google Project Hosting". 14 October 2011. Retrieved 29 June 2012.
| Early telecommunications | |
|---|---|
| ISO/IEC 8859 |
|
| Bibliographic use | |
| National standards | |
| ISO/IEC 2022 | |
| Mac OS Code pages ("scripts") | |
| DOS code pages | |
| IBM AIX code pages | |
| Windows code pages | |
| EBCDIC code pages | |
| DEC terminals (VTx) | |
| Platform specific |
|
| Unicode / ISO/IEC 10646 | |
| TeX typesetting system | |
| Miscellaneous code pages | |
| Control character | |
| Related topics | |