A, or a, is the first letter and the first vowel letter of the Latin alphabet, used in the modern English alphabet, and others worldwide. Its name in English is a, plural aes.

D, or d, is the fourth letter of the Latin alphabet, used in the modern English alphabet, the alphabets of other western European languages and others worldwide. Its name in English is dee, plural dees.
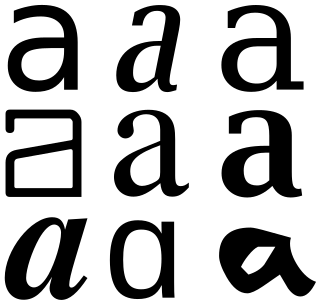
In linguistics, a grapheme is the smallest functional unit of a writing system. The word grapheme is derived from Ancient Greek γράφω (gráphō) 'write' and the suffix -eme by analogy with phoneme and other names of emic units. The study of graphemes is called graphemics. The concept of graphemes is abstract and similar to the notion in computing of a character. By comparison, a specific shape that represents any particular grapheme in a given typeface is called a glyph.

Unicode, formally The Unicode Standard, is a text encoding standard maintained by the Unicode Consortium designed to support the use of text written in all of the world's major writing systems. Version 15.1 of the standard defines 149813 characters and 161 scripts used in various ordinary, literary, academic, and technical contexts.
GB/T 2312-1980 is a key official character set of the People's Republic of China, used for Simplified Chinese characters. GB2312 is the registered internet name for EUC-CN, which is its usual encoded form. GB refers to the Guobiao standards (国家标准), whereas the T suffix denotes a non-mandatory standard.
The Greek alphabet has been used to write the Greek language since the late 9th or early 8th century BC. It is derived from the earlier Phoenician alphabet, and was the earliest known alphabetic script to have distinct letters for vowels as well as consonants. In Archaic and early Classical times, the Greek alphabet existed in many local variants, but, by the end of the 4th century BC, the Euclidean alphabet, with 24 letters, ordered from alpha to omega, had become standard and it is this version that is still used for Greek writing today.
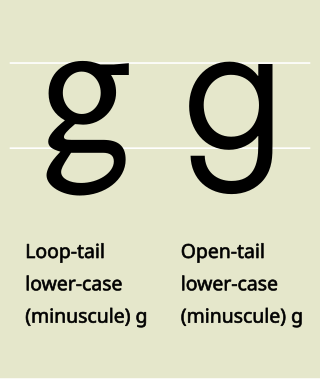
In graphemics and typography, the term allograph is used of a glyph that is a design variant of a letter or other grapheme, such as a letter, a number, an ideograph, a punctuation mark or other typographic symbol. In graphemics, an obvious example in English is the distinction between uppercase and lowercase letters. Allographs can vary greatly, without affecting the underlying identity of the grapheme. Even if the word "cat" is rendered as "cAt", it remains recognizable as the sequence of the three graphemes ⟨c⟩, ⟨a⟩, ⟨t⟩.

Bitstream Cyberbit is a commercial serif Unicode font designed by Bitstream Inc. It is freeware for non-commercial uses. It was one of the first widely available fonts to support a large portion of the Unicode repertoire.

In orthography and typography, a homoglyph is one of two or more graphemes, characters, or glyphs with shapes that appear identical or very similar but may have differing meaning. The designation is also applied to sequences of characters sharing these properties.
The internationalized domain name (IDN) homograph attack is a way a malicious party may deceive computer users about what remote system they are communicating with, by exploiting the fact that many different characters look alike. For example, the Cyrillic, Greek and Latin alphabets each have a letter ⟨o⟩ that has the same shape but different meaning from its counterparts.
In a writing system, a letter is a grapheme that generally corresponds to a phoneme—the smallest functional unit of speech—though there is rarely total one-to-one correspondence between the two. An alphabet is a writing system that uses letters.
Symbol is one of the four standard fonts available on all PostScript-based printers, starting with Apple's original LaserWriter (1985). It contains a complete unaccented Greek alphabet and a selection of commonly used mathematical symbols. Insofar as it fits into any standard classification, it is a serif font designed in the style of Times New Roman.
Unicode supports several phonetic scripts and notations through its existing scripts and the addition of extra blocks with phonetic characters. These phonetic characters are derived from an existing script, usually Latin, Greek or Cyrillic. Apart from the International Phonetic Alphabet (IPA), extensions to the IPA and obsolete and nonstandard IPA symbols, these blocks also contain characters from the Uralic Phonetic Alphabet and the Americanist Phonetic Alphabet.
Unicode equivalence is the specification by the Unicode character encoding standard that some sequences of code points represent essentially the same character. This feature was introduced in the standard to allow compatibility with preexisting standard character sets, which often included similar or identical characters.
In Unicode and the UCS, a compatibility character is a character that is encoded solely to maintain round-trip convertibility with other, often older, standards. As the Unicode Glossary says:
A character that would not have been encoded except for compatibility and round-trip convertibility with other standards
A numeral is a character that denotes a number. The decimal number digits 0–9 are used widely in various writing systems throughout the world, however the graphemes representing the decimal digits differ widely. Therefore Unicode includes 22 different sets of graphemes for the decimal digits, and also various decimal points, thousands separators, negative signs, etc. Unicode also includes several non-decimal numerals such as Aegean numerals, Roman numerals, counting rod numerals, Mayan numerals, Cuneiform numerals and ancient Greek numerals. There is also a large number of typographical variations of the Western Arabic numerals provided for specialized mathematical use and for compatibility with earlier character sets, such as ² or ②, and composite characters such as ½.
Many scripts in Unicode, such as Arabic, have special orthographic rules that require certain combinations of letterforms to be combined into special ligature forms. In English, the common ampersand (&) developed from a ligature in which the handwritten Latin letters e and t were combined. The rules governing ligature formation in Arabic can be quite complex, requiring special script-shaping technologies such as the Arabic Calligraphic Engine by Thomas Milo's DecoType.
KPS 9566 is a North Korean standard specifying a character encoding for the Chosŏn'gŭl (Hangul) writing system used for the Korean language. The edition of 1997 specified an ISO 2022-compliant 94×94 two-byte coded character set. Subsequent editions have added additional encoded characters outside of the 94×94 plane, in a manner comparable to UHC or GBK.
The ISO basic Latin alphabet is an international standard for a Latin-script alphabet that consists of two sets of 26 letters, codified in various national and international standards and used widely in international communication. They are the same letters that comprise the current English alphabet. Since medieval times, they are also the same letters of the modern Latin alphabet. The order is also important for sorting words into alphabetical order.
B, or b, is the second letter of the Latin alphabet, used in the modern English alphabet, the alphabets of other western European languages and others worldwide. Its name in English is bee, plural bees.