
A weighting filter is used to emphasize or suppress some aspects of a phenomenon compared to others, for measurement or other purposes.
The absolute threshold of hearing (ATH) is the minimum sound level of a pure tone that an average human ear with normal hearing can hear with no other sound present. The absolute threshold relates to the sound that can just be heard by the organism. The absolute threshold is not a discrete point, and is therefore classed as the point at which a sound elicits a response a specified percentage of the time. This is also known as the auditory threshold.

In acoustics, loudness is the subjective perception of sound pressure. More formally, it is defined as, "That attribute of auditory sensation in terms of which sounds can be ordered on a scale extending from quiet to loud." The relation of physical attributes of sound to perceived loudness consists of physical, physiological and psychological components. The study of apparent loudness is included in the topic of psychoacoustics and employs methods of psychophysics.

A hearing test provides an evaluation of the sensitivity of a person's sense of hearing and is most often performed by an audiologist using an audiometer. An audiometer is used to determine a person's hearing sensitivity at different frequencies. There are other hearing tests as well, e.g., Weber test and Rinne test.
An equal-loudness contour is a measure of sound pressure level, over the frequency spectrum, for which a listener perceives a constant loudness when presented with pure steady tones. The unit of measurement for loudness levels is the phon and is arrived at by reference to equal-loudness contours. By definition, two sine waves of differing frequencies are said to have equal-loudness level measured in phons if they are perceived as equally loud by the average young person without significant hearing impairment.

The acoustic reflex is an involuntary muscle contraction that occurs in the middle ear in response to loud sound stimuli or when the person starts to vocalize.

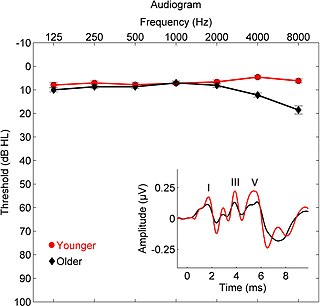
Sensorineural hearing loss (SNHL) is a type of hearing loss in which the root cause lies in the inner ear or sensory organ or the vestibulocochlear nerve. SNHL accounts for about 90% of reported hearing loss. SNHL is usually permanent and can be mild, moderate, severe, profound, or total. Various other descriptors can be used depending on the shape of the audiogram, such as high frequency, low frequency, U-shaped, notched, peaked, or flat.
An otoacoustic emission (OAE) is a sound that is generated from within the inner ear. Having been predicted by Austrian astrophysicist Thomas Gold in 1948, its existence was first demonstrated experimentally by British physicist David Kemp in 1978, and otoacoustic emissions have since been shown to arise through a number of different cellular and mechanical causes within the inner ear. Studies have shown that OAEs disappear after the inner ear has been damaged, so OAEs are often used in the laboratory and the clinic as a measure of inner ear health.
Audiometry is a branch of audiology and the science of measuring hearing acuity for variations in sound intensity and pitch and for tonal purity, involving thresholds and differing frequencies. Typically, audiometric tests determine a subject's hearing levels with the help of an audiometer, but may also measure ability to discriminate between different sound intensities, recognize pitch, or distinguish speech from background noise. Acoustic reflex and otoacoustic emissions may also be measured. Results of audiometric tests are used to diagnose hearing loss or diseases of the ear, and often make use of an audiogram.
In audiology and psychoacoustics the concept of critical bands, introduced by Harvey Fletcher in 1933 and refined in 1940, describes the frequency bandwidth of the "auditory filter" created by the cochlea, the sense organ of hearing within the inner ear. Roughly, the critical band is the band of audio frequencies within which a second tone will interfere with the perception of the first tone by auditory masking.

An audiogram is a graph that shows the audible threshold for standardized frequencies as measured by an audiometer. The Y axis represents intensity measured in decibels and the X axis represents frequency measured in hertz. The threshold of hearing is plotted relative to a standardised curve that represents 'normal' hearing, in dB(HL). They are not the same as equal-loudness contours, which are a set of curves representing equal loudness at different levels, as well as at the threshold of hearing, in absolute terms measured in dB SPL.

Hearing range describes the range of frequencies that can be heard by humans or other animals, though it can also refer to the range of levels. The human range is commonly given as 20 to 20,000 Hz, although there is considerable variation between individuals, especially at high frequencies, and a gradual loss of sensitivity to higher frequencies with age is considered normal. Sensitivity also varies with frequency, as shown by equal-loudness contours. Routine investigation for hearing loss usually involves an audiogram which shows threshold levels relative to a normal.
Ultrasonic hearing is a recognised auditory effect which allows humans to perceive sounds of a much higher frequency than would ordinarily be audible using the inner ear, usually by stimulation of the base of the cochlea through bone conduction. Normal human hearing is recognised as having an upper bound of 15–28 kHz, depending on the person.
The auditory brainstem response (ABR) is an auditory evoked potential extracted from ongoing electrical activity in the brain and recorded via electrodes placed on the scalp. The measured recording is a series of six to seven vertex positive waves of which I through V are evaluated. These waves, labeled with Roman numerals in Jewett and Williston convention, occur in the first 10 milliseconds after onset of an auditory stimulus. The ABR is considered an exogenous response because it is dependent upon external factors.
Perceptual Evaluation of Audio Quality (PEAQ) is a standardized algorithm for objectively measuring perceived audio quality, developed in 1994-1998 by a joint venture of experts within Task Group 6Q of the International Telecommunication Union's Radiocommunication Sector (ITU-R). It was originally released as ITU-R Recommendation BS.1387 in 1998 and last updated in 2001. It utilizes software to simulate perceptual properties of the human ear and then integrates multiple model output variables into a single metric. PEAQ characterizes the perceived audio quality as subjects would do in a listening test according to ITU-R BS.1116. PEAQ results principally model mean opinion scores that cover a scale from 1 (bad) to 5 (excellent).

Pure tone audiometry or pure-tone audiometry is the main hearing test used to identify hearing threshold levels of an individual, enabling determination of the degree, type and configuration of a hearing loss and thus providing a basis for diagnosis and management. Pure-tone audiometry is a subjective, behavioural measurement of a hearing threshold, as it relies on patient responses to pure tone stimuli. Therefore, pure-tone audiometry is only used on adults and children old enough to cooperate with the test procedure. As with most clinical tests, standardized calibration of the test environment, the equipment and the stimuli is needed before testing proceeds. Pure-tone audiometry only measures audibility thresholds, rather than other aspects of hearing such as sound localization and speech recognition. However, there are benefits to using pure-tone audiometry over other forms of hearing test, such as click auditory brainstem response (ABR). Pure-tone audiometry provides ear specific thresholds, and uses frequency specific pure tones to give place specific responses, so that the configuration of a hearing loss can be identified. As pure-tone audiometry uses both air and bone conduction audiometry, the type of loss can also be identified via the air-bone gap. Although pure-tone audiometry has many clinical benefits, it is not perfect at identifying all losses, such as ‘dead regions’ of the cochlea and neuropathies such as auditory processing disorder (APD). This raises the question of whether or not audiograms accurately predict someone's perceived degree of disability.

Tinnitus maskers are a range of devices based on simple white noise machines used to add natural or artificial sound into a tinnitus sufferer's environment in order to mask or cover up the ringing. The noise is supplied by a sound generator, which may reside in or above the ear or be placed on a table or elsewhere in the environment. The noise is usually white noise or music, but in some cases, it may be patterned sound or specially tailored sound based on the characteristics of the person's tinnitus.
Psychoacoustics is the branch of psychophysics involving the scientific study of sound perception and audiology—how humans perceive various sounds. More specifically, it is the branch of science studying the psychological responses associated with sound. Psychoacoustics is an interdisciplinary field of many areas, including psychology, acoustics, electronic engineering, physics, biology, physiology, and computer science.
Bone-conduction auditory brainstem response or BCABR is a type of auditory evoked response that records neural response from EEG with stimulus transmitted through bone conduction.
Binaural unmasking is phenomenon of auditory perception discovered by Ira Hirsh. In binaural unmasking, the brain combines information from the two ears in order to improve signal detection and identification in noise. The phenomenon is most commonly observed when there is a difference between the interaural phase of the signal and the interaural phase of the noise. When such a difference is present there is an improvement in masking threshold compared to a reference situation in which the interaural phases are the same, or when the stimulus has been presented monaurally. Those two cases usually give very similar thresholds. The size of the improvement is known as the "binaural masking level difference" (BMLD), or simply as the "masking level difference".








