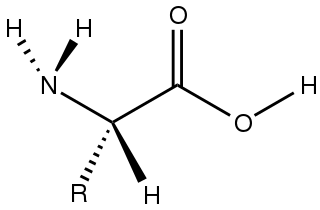
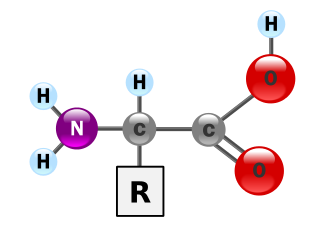
Amino acids are organic compounds that contain both amino and carboxylic acid functional groups. Although over 500 amino acids exist in nature, by far the most important are the 22 α-amino acids incorporated into proteins. Only these 22 appear in the genetic code of life.

The endoplasmic reticulum (ER) is a part of a transportation system of the eukaryotic cell, and has many other important functions such as protein folding. It is a type of organelle made up of two subunits – rough endoplasmic reticulum (RER), and smooth endoplasmic reticulum (SER). The endoplasmic reticulum is found in most eukaryotic cells and forms an interconnected network of flattened, membrane-enclosed sacs known as cisternae, and tubular structures in the SER. The membranes of the ER are continuous with the outer nuclear membrane. The endoplasmic reticulum is not found in red blood cells, or spermatozoa.
Molecular biology is a branch of biology that seeks to understand the molecular basis of biological activity in and between cells, including biomolecular synthesis, modification, mechanisms, and interactions.

In molecular biology, messenger ribonucleic acid (mRNA) is a single-stranded molecule of RNA that corresponds to the genetic sequence of a gene, and is read by a ribosome in the process of synthesizing a protein.

A prion is a misfolded protein that induces misfolding in normal variants of the same protein, leading to cellular death. Prions are responsible for prion diseases, known as transmissible spongiform encephalopathy (TSEs), which are fatal and transmissible neurodegenerative diseases affecting both humans and animals. These proteins can misfold sporadically, due to genetic mutations, or by exposure to an already misfolded protein, leading to an abnormal three-dimensional structure that can propagate misfolding in other proteins.
Proteins are large biomolecules and macromolecules that comprise one or more long chains of amino acid residues. Proteins perform a vast array of functions within organisms, including catalysing metabolic reactions, DNA replication, responding to stimuli, providing structure to cells and organisms, and transporting molecules from one location to another. Proteins differ from one another primarily in their sequence of amino acids, which is dictated by the nucleotide sequence of their genes, and which usually results in protein folding into a specific 3D structure that determines its activity.

Ribosomes are macromolecular machines, found within all cells, that perform biological protein synthesis. Ribosomes link amino acids together in the order specified by the codons of messenger RNA molecules to form polypeptide chains. Ribosomes consist of two major components: the small and large ribosomal subunits. Each subunit consists of one or more ribosomal RNA molecules and many ribosomal proteins. The ribosomes and associated molecules are also known as the translational apparatus.

Protein secondary structure is the local spatial conformation of the polypeptide backbone excluding the side chains. The two most common secondary structural elements are alpha helices and beta sheets, though beta turns and omega loops occur as well. Secondary structure elements typically spontaneously form as an intermediate before the protein folds into its three dimensional tertiary structure.

Escherichia coli ( ESH-ə-RIK-ee-ə KOH-lye) is a gram-negative, facultative anaerobic, rod-shaped, coliform bacterium of the genus Escherichia that is commonly found in the lower intestine of warm-blooded organisms. Most E. coli strains are harmless, but some serotypes such as EPEC and ETEC are pathogenic, can cause serious food poisoning in their hosts and are occasionally responsible for food contamination incidents that prompt product recalls. Most strains are part of the normal microbiota of the gut and are harmless or even beneficial to humans (although these strains tend to be less studied than the pathogenic ones). For example, some strains of E. coli benefit their hosts by producing vitamin K2 or by preventing the colonization of the intestine by pathogenic bacteria. These mutually beneficial relationships between E. coli and humans are a type of mutualistic biological relationship — where both the humans and the E. coli are benefitting each other. E. coli is expelled into the environment within fecal matter. The bacterium grows massively in fresh fecal matter under aerobic conditions for three days, but its numbers decline slowly afterwards.
The Protein Data Bank (PDB) is a database for the three-dimensional structural data of large biological molecules such as proteins and nucleic acids, which is overseen by the Worldwide Protein Data Bank (wwPDB). These structural data are obtained and deposited by biologists and biochemists worldwide through the use of experimental methodologies such as X-ray crystallography, NMR spectroscopy, and, increasingly, cryo-electron microscopy. All submitted data are reviewed by expert biocurators and, once approved, are made freely available on the Internet under the CC0 Public Domain Dedication. Global access to the data is provided by the websites of the wwPDB member organisations.

The National Center for Biotechnology Information (NCBI) is part of the (NLM), a branch of the National Institutes of Health (NIH). It is approved and funded by the government of the United States. The NCBI is located in Bethesda, Maryland, and was founded in 1988 through legislation sponsored by US Congressman Claude Pepper.
Gene expression is the process by which information from a gene is used in the synthesis of a functional gene product that enables it to produce end products, proteins or non-coding RNA, and ultimately affect a phenotype. These products are often proteins, but in non-protein-coding genes such as transfer RNA (tRNA) and small nuclear RNA (snRNA), the product is a functional non-coding RNA. The process of gene expression is used by all known life—eukaryotes, prokaryotes, and utilized by viruses—to generate the macromolecular machinery for life.

In molecular biology, post-translational modification (PTM) is the covalent process of changing proteins following protein biosynthesis. PTMs may involve enzymes or occur spontaneously. Proteins are created by ribosomes, which translate mRNA into polypeptide chains, which may then change to form the mature protein product. PTMs are important components in cell signalling, as for example when prohormones are converted to hormones.

Membrane proteins are common proteins that are part of, or interact with, biological membranes. Membrane proteins fall into several broad categories depending on their location. Integral membrane proteins are a permanent part of a cell membrane and can either penetrate the membrane (transmembrane) or associate with one or the other side of a membrane. Peripheral membrane proteins are transiently associated with the cell membrane.

A protein family is a group of evolutionarily related proteins. In many cases, a protein family has a corresponding gene family, in which each gene encodes a corresponding protein with a 1:1 relationship. The term "protein family" should not be confused with family as it is used in taxonomy.

UniProt is a freely accessible database of protein sequence and functional information, many entries being derived from genome sequencing projects. It contains a large amount of information about the biological function of proteins derived from the research literature. It is maintained by the UniProt consortium, which consists of several European bioinformatics organisations and a foundation from Washington, DC, USA.

Protein–protein interactions (PPIs) are physical contacts of high specificity established between two or more protein molecules as a result of biochemical events steered by interactions that include electrostatic forces, hydrogen bonding and the hydrophobic effect. Many are physical contacts with molecular associations between chains that occur in a cell or in a living organism in a specific biomolecular context.

Albumin is a family of globular proteins, the most common of which are the serum albumins. All of the proteins of the albumin family are water-soluble, moderately soluble in concentrated salt solutions, and experience heat denaturation. Albumins are commonly found in blood plasma and differ from other blood proteins in that they are not glycosylated. Substances containing albumins are called albuminoids.
Proteins are essential nutrients for the human body. They are one of the building blocks of body tissue and can also serve as a fuel source. As a fuel, proteins provide as much energy density as carbohydrates: 17 kJ per gram; in contrast, lipids provide 37 kJ per gram. The most important aspect and defining characteristic of protein from a nutritional standpoint is its amino acid composition.
A protein superfamily is the largest grouping (clade) of proteins for which common ancestry can be inferred. Usually this common ancestry is inferred from structural alignment and mechanistic similarity, even if no sequence similarity is evident. Sequence homology can then be deduced even if not apparent. Superfamilies typically contain several protein families which show sequence similarity within each family. The term protein clan is commonly used for protease and glycosyl hydrolases superfamilies based on the MEROPS and CAZy classification systems.
