Chimeric RNA, sometimes referred to as a fusion transcript, is composed of exons from two or more different genes that have the potential to encode novel proteins.[1] These mRNAs are different from those produced by conventional splicing as they are produced by two or more gene loci.
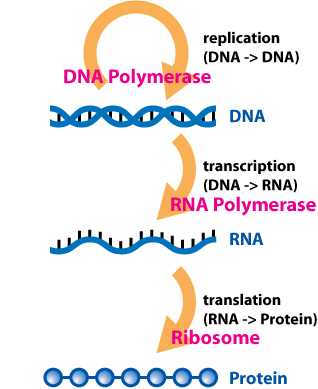
DNA encodes the genetic information required for an organism to carry out its life cycle. In effect, DNA serves as the "hard drive" which stores genetic data. DNA is replicated and serves as its own template for replication. DNA forms a double helix structure and is a composed of a sugar-phosphate backbone and nitrogenous bases; this can be thought of as a ladder structure where the sides of the ladder are constructed of deoxyribose sugar and phosphate while the rungs of the ladder are composed of paired nitrogenous bases.[4] There are four bases in a DNA molecule: adenine (A), cytosine (C), thymine (T), and guanine (G). Nucleotides are a structural component of DNA and RNA, being made of a molecule of sugar and a molecule of phosphoric acid. The double helix structure of DNA is composed of two antiparallel strands which are oriented in opposite directions. DNA is composed of base pairs in which adenine pairs with thymine and guanine pairs with cytosine. While DNA serves as template for production of ribonucleic acid (RNA), RNA is usually responsible for making protein. The process of making RNA from DNA is called transcription. RNA uses a similar set of bases except that thymine is replaced with uracil. A group of enzymes called RNA polymerases (isolated by biochemists Jerard Hurwitz and Samuel B. Weiss) function in the presence of DNA. These enzymes produce RNA using segments of chromosomal DNA as a template. Unlike replication, where a complete copy of DNA is made, transcription copies only the gene that is to be expressed as a protein.[5]
Initially, it was thought that RNA served as a structural template for protein synthesis, essentially ordering amino acids by a series of cavities shaped specifically so that only specific amino acids would fit. Crick was not satisfied with this hypothesis given that the four bases of RNA are hydrophilic and that many amino acids prefer interactions with hydrophobic groups. Additionally, some amino acids are very structurally similar and Crick felt that accurate discrimination would not be possible given the similarities. Crick then proposed that prior to incorporation into proteins, amino acids are first attached to adapter molecules which have unique surface features that can bind to specific bases on the RNA templates.[5] These adapter molecules are called transfer RNA (tRNA).
Through a series of experiments involving E. coli and the T4 phage in 1960,[5] it was shown that messenger RNA (mRNA) carriers information from DNA to the ribosomal sites of protein synthesis. The tRNA-amino acid precursors are brought into position by ribosomes where they can read the information provided mRNA templates to synthesize protein.
RNA Splicing
Creating a protein consists of two main steps: transcription of DNA into RNA and translation of RNA into protein. After DNA is transcribed into RNA, the molecule is known as pre-messenger RNA (mRNA) and it consists of exons and introns that can be split apart and rearranged in many different ways. Historically, exons are considered the coding sequence and introns are considered the "junk" DNA. Although this has been shown to be false, it is true that exons are often merged. Depending on the needs of the cell, regulatory mechanisms choose which exons, and sometimes introns, to join. This process of removing pieces of a pre- mRNA transcript and combining them with other pieces is called splicing. The human genome encodes approximately 25,000 genes but there are significantly more proteins produced. This is accomplished through RNA splicing. The exons of these 25,000 genes can be spliced in many different ways to create countless combinations of RNA transcripts and ultimately countless proteins. Normally, exons from the same pre-mRNA transcript are spliced together. However, occasionally gene products or pre-mRNA transcripts are spliced together so that exons from different transcripts are mixed together in a fusion product known as chimeric RNA. Chimeric RNA often incorporates exons from highly expressed genes,[1] but the chimeric transcript itself is usually expressed at low levels.
This chimeric RNA can then be translated into a fusion protein. Fusion proteins are very tissue-specific [1] and they are frequently associated with cancers such as colorectal, prostate,[6] and mesotheliomas.[7] They significantly exploit signal peptides and transmembrane proteins which can alter the localization of proteins, possibly contributing to the disease phenotype.
Discovery of Chimeric RNA
One of the first studies to investigate the generation of chimeric RNA examined the fusion of the first three exons of a gene known as JAZF1 to the last 15 exons of a gene known as JJAZ1.[8] This exact transcript, and the resulting protein, was found specifically in endometrial tissue. While often found in endometrial cancers, these transcripts are expressed in normal tissue as well. Originally thought to be the result of chromosomal fusions, one group investigated whether this was accurate. Using Southern blotting and fluorescence in situ hybridization (FISH) on the genome, the researchers found no evidence of DNA rearrangement. They decided to investigate further by combining human endometrial cells with rhesus fibroblasts and found chimeric products containing sequences from both species. These data suggested that chimeric RNA is generated by splicing parts of genes together rather than chromosomal re-arrangements. They also performed mass spectrometry on the translated protein to verify that the chimeric RNA is translated into protein.
Recently, advances in next-generation sequencing have decreased the cost of sequencing significantly, allowing more RNAseq projects to be conducted. These RNAseq projects are able to detect novel RNA transcripts instead of the traditional microarray in which only known transcripts can be detected. Deep sequencing enables detection of transcripts even at very low levels. This has allowed researchers to detect many more chimeric RNAs and fusion proteins and has facilitated understanding their role in health and disease.
Chimeric protein products
Numerous putative chimeric transcripts have been identified among the expressed sequence tags using high throughput RNA sequencing technology. In humans, chimeric transcripts can be generated in several ways such as trans-splicing of pre-mRNAs, RNA transcription runoff, from other errors in RNA transcription or they can also be the result of gene fusion following inter-chromosomal translocations or rearrangements. Among the few corresponding protein products that have been characterized so far, most result from chromosomal translocations and are associated with cancer. For instance, gene fusion in chronic myelogenous leukemia (CML) leads to an mRNA transcript that encompasses the 5′ end of the breakpoint cluster region protein (BCR) gene and the 3′ end of the Abelson murine leukemia viral oncogene homolog 1 (ABL) gene. Translation of this transcript results in a chimeric BCR–ABL protein that possesses increased tyrosine kinase activity. Chimeric transcripts characterize specific cellular phenotypes and are suspected to function not only in cancer, but also in normal cells. One example of a chimera in normal human cells is generated by trans-splicing of the 5′ exons of the JAZF1 gene on chromosome 7p15 and the 3′ exons of JJAZ1 (SUZ12) on chromosome 17q1. This chimeric RNA is translated in endometrial stroma cells and encodes an anti-apoptotic protein. Notable examples of chimeric genes in cancer are the fused BCR-ABL, FUS-ERG, MLL-AF6, and MOZ-CBP genes expressed in acute myeloid leukemia (AML), and the TMPRSS2-ETS chimera associated with overexpression of the oncogene in prostate cancer.[1]
Characteristics of chimeric proteins
Frenkel-Morgenstern et al. have defined two main features of chimeric proteins. They have reported that chimeras exploit signal peptides and transmembrane domains to alter the cellular localization of the associated activities. Second, chimeras incorporate parental genes that are expressed at a high level.[1] A survey of all the functional domains in proteins encoded by chimeric transcripts demonstrated that chimeras contain complete protein domains significantly more often than in random data sets.[9]
Databases of chimeric transcripts
Several databases have been constructed to incorporate chimeric transcripts from different resources using a variety of computational procedures:
Recent advances in high throughput transcriptome sequencing have paved the way for new computational methods for fusion discovery. The following are computational tools available for detection of fusion transcripts from RNA-Seq data:
Fusim is a software tool for simulating fusion transcripts for comprehensive comparison across fusion discovery methods.[17]
CRAC integrates genomic locations and local coverage to enable splice junction or fusion RNA predictions directly from RNA-seq read analysis.[18]
TopHat-Fusion can discover fusion products deriving from known genes, unknown genes and unannotated splice variants of known genes.[19]
FusionAnalyser is a tool dedicated to the identification of driver fusion rearrangements in human cancer through the analysis of paired-end high-throughput transcriptome sequencing data.[20]
ChimeraScan offers discovery of chimeric transcription between two independent transcripts in high-throughput transcriptome sequencing data by providing features such as the ability to process long (>75 bp) paired-end reads, processing of ambiguously mapping reads and detection of reads spanning a fusion junction.[21]
FusionHunter identifies fusion transcripts from transcriptional analysis of paired-end RNA-seq reads.[22]
SplitSeek allows de novo prediction of splice junctions in short-read RNA-seq data, suitable for detection of novel splicing events and chimeric transcripts.[23]
Trans-AB ySS is a de novo short-read transcriptome assembly and analysis pipeline that helps in the identification of known, new and alternative structures in expressed transcripts such as chimeric transcripts.[24]
FusionSeq identifies fusion transcripts from paired-end RNA-sequencing. It includes filters to remove spurious candidate fusions with artifacts, such as misalignment or random pairing of transcript fragments.[25]
Some caution needs to be applied in the interpretation of trans-splicing events detected in high-throughput sequencing experiments as the reverse transcriptase enzymes ubiquitously used to determine RNA sequences are capable of introducing apparent trans-splicing events that were not present in the original RNA.[26][27] Some chimeric RNAs have been confirmed by other methods however.[28]
Chimeric RNA in lower eukaryotes
Although rare in higher eukaryotes, various lower eukaryotes including nematodes and trypanosomes make extensive use of trans-splicing to generate chimeric RNAs.[29][30] In these organisms, splicing reactions between a protein coding RNA and a universal sequence result in the attachment of a splice-leader to the 5' end of the RNA, generating a functional messenger RNA. This system allows the use of operons - collections of protein-coding genes with a shared function that are simultaneously transcribed into a single RNA and then spliced into individual messenger RNAs, each of which codes for a single protein.
↑ Michaeli, S (Apr 2011). "Trans-splicing in trypanosomes: machinery and its impact on the parasite transcriptome". Future Microbiology. 6 (4): 459–74. doi:10.2217/fmb.11.20. PMID21526946.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.
{kind=link}